In the last update, I wrote about the process of adding an async grammar checker and TeX import into LibreOffice. It was very exciting to see my blog post get picked up by Slashdot but right at the time it was published, I was finishing a feature LibreOffice should have probably added years ago: real scientific Python.
LibreOffice has lagged behind Excel in data science workflows. With my recent work in WriterAgent, you can now leverage the full Python ecosystem: Run NumPy in Calc, generate pandas DataFrames from Writer, or let AI agents create scripts.
My focus in NumPy at first was exposing it to the LLMs so they could write scripts and put the results in your document, but I eventually realized Python should be enabled for the meatbags too. The implementation is simple, robust, and fast enough, but getting here required rejecting previous approaches.
The ABI Problem
The reason why Numpy is not supported in Libreoffice today is that NumPy is not pure Python. It ships compiled C and C++ extensions containing a wide variety of high-performance math implementations that must match the exact Python ABI they were built against: minor version, architecture, compiler, and build flags. LibreOffice (for many operating systems) embeds its own Python interpreter.
If you simply append a user’s packages to LibreOffice’s sys.path and import NumPy, you will quickly crash because the binary interface between the extension and NumPy’s files is incompatible.
Two common “solutions” look attractive on paper but create long-term headaches.
1. Vendor the NumPy stack into the .oxt file. At first, it sounds reasonable: “users just install the extension and it works.” The challenge is that the full scientific stack is large—easily 50–100 MB uncompressed, and that is before you multiply by the number of platforms and Python versions.
Security and bug fix updates become the extension’s responsibility. Users who want MKL-accelerated NumPy have to use a specific pinned version of Python that matches the LibreOffice version. The download size balloons from 7 MB to a gigabyte, even for those who will never run a single line of Python.
2. Vendoring pip and auto-installing packages into LibreOffice’s embedded Python at startup is the approach taken by LibrePythonista. It is clever, but adds a different layer of fragility. If the Python code hangs or crashes, it takes down LibreOffice. You are now tightly coupled to whatever Python version LibreOffice ships with. When LibreOffice upgrades, installed packages break.
Both approaches also make the extension more complex. LibrePythonista ended up writing a lot of path manipulation and other code that has to work on every platform that LibreOffice supports. That code is easy to get subtly wrong and hard to test comprehensively.
The Design I Chose: User Venv + Subprocess Bridge
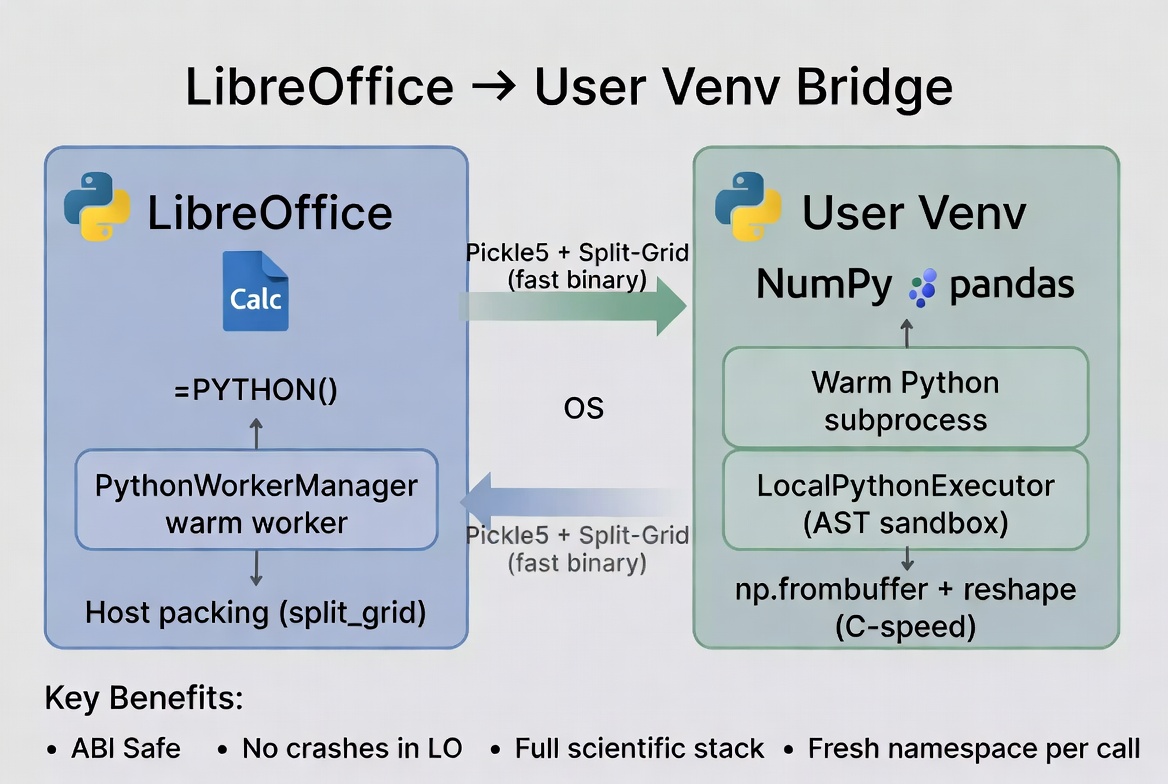
WriterAgent takes a different path. You just point LibreOffice to a Python virtual environment (venv) directory with whatever version of Python and packages you want. WriterAgent never imports NumPy (or any third-party package) in LibreOffice’s embedded Python.
Instead, it spawns (and keeps running) an external Python worker process. When you send data cross-process, both sides don’t need to be running the same version or even architecture, they just need to be able to parse JSON or whatever data format is used. The implementation is so simple I had it working an hour.
There are many benefits of this design. If you have already created a custom high-performance MKL or OpenBLAS build, you can just use it. A crash inside a user script will not take down LibreOffice.
=PYTHON() in Calc
Next, I added a formula to Calc to let you write code like this: =PYTHON("np.mean(data)", B1:B1000)

The data variable is a special value containing the passed-in ranges, injected into the Python’s namespace at runtime. You can return a result
The only downside of =PYTHON() so far is that most of LibreOffice expects Calc functions to return a single data point. If you want to return an array, you need to select the proper number of rows in advance and use a matrix key (Ctrl+Shift+Enter) so one worker invocation can fill an entire range without N separate round-trips.
Having to select the proper number of rows in advance and remember to press Ctrl+Shift+Enter is a drag, so I’ve created ways to have scripts with the ability to overwrite multiple cells.
When the default is to return just a single value, sharing code between cells becomes very important. Fortunately, LibreOffice automatically supports the feature if you write something like this: =PYTHON($A$1,B1:B1000).
We’ve moved beyond OOP – Object Oriented Programming to COP – Cell Oriented Programming!
The xl() Hack
Microsoft’s Python in Excel forces you to write xl(“A1:B100”) inside the Python code. That string is opaque to Calc’s formula engine, so the dependency graph breaks. When you edit any cell, Excel has to re-run every Python cell in row-major order just to be safe. Move a cell, insert a row, or rename a sheet and your pipelines silently stop working or produce stale results.
WriterAgent’s =PYTHON() keeps the dependency declaration where Calc expects it: in the arguments. You get true incremental recalc and explicit ordering without fragile sheet layout. The Python code itself stays clean and readable because it just receives data: no string parsing or magic xl() calls required.
When you have a bunch of random “global variables” or tweakable parameters that you want your Python code to respect: simulation counts, thresholds, etc., the cleanest pattern is to gather a reference to them together in a single range (for example, A5 – A30), and pass that in. This keeps the formula short, makes the parameters clear, and doesn’t break the recalculation engine.
Shared kernel and initialization scripts
Right now the default behavior is isolated (each =PYTHON() cell gets its own fresh namespace), but you can turn on a shared kernel. In shared mode, every cell in the same spreadsheet shares one persistent Python namespace.
Variables, DataFrames and helper functions that you define in one cell are instantly available in the next. The big thing you have to keep in mind is that your code runs in dependency order, not left to right. However if you declare all of your dependencies as part of the ranges that are passed in, it will all just work out. There’s also a new menu item to Reset Python Session and start fresh.
To make multi-cell workflows more powerful, there are also initialization scripts. In Calc, you can create a special “Init” and attach it to your spreadsheet. It runs before the first Python function is called. You can put any expensive one-time setup code in there, and every subsequent =PYTHON() cell starts with those variables and functions ready.
The Monaco editor for rich-text Python editing

Once I had Python external communication working, adding a full-featured code editor with color syntax highlighting was mostly a matter of exposing the same pipe to a new child: pywebview + the official Monaco bundle. The JS resources are packaged with the extension but it runs in a child subprocess.
Once I had Init scripts, it was easy to generalize to add other scripts you could attach to a document, or keep in a personal scratchpad that lives in the JSON config file.
Cross-Process Serialization

There’s overhead to send data to/from another process, so it became a little game to try to see how far you could optimize it. I started with basic JSON: “((1.51321),(1514213.3),(5.14159))” which the receiving side has to chew through cell-by-cell, parsing the parenthesis, traversing the points, etc. I soon realized that it’s much more efficient to have host pack the entire range into a single float64 array. On the child side, where NumPy lives, np.frombuffer, plus a reshape to whatever Calc actually delivered, turns the float64 buffer into a proper ndarray in microseconds.
Empty cells and strings become NaN, while the string values ride along in a dictionary keyed by their position. The whole thing gets wrapped in pickle protocol 5 and sent across the pipe.
After profiling and optimizing the Python packing, the next optimization was to implement the few speed-critical pack routines in Cython. Cython is a variant of Python which can be compiled into native code. For most of WriterAgent (and every) Python codebase, the performance benefit from compiling the entire source tree to native x64 or whatever wouldn’t even be noticeable. A well-designed Python program should already be spending most of the CPU time running native code already. If your Python code is slow, it will be slow in C++ or Rust.
Serializing and deserializing 100,000 numbers takes about 50 ms with standard JSON, 12 ms with pickle (Python’s native binary serializer), and with the split-grid Cython version, it takes 1.3 ms. Microsoft sends all of your Python calculations to their servers in the cloud, so you’ll never get results in milliseconds, and if you don’t have Internet access, they’ll never arrive.
Since I didn’t want to make binaries for Windows, Mac, x64, ARM, etc, GitHub Actions using cibuildwheel lets you build the binaries for the different processors and Python versions. It’s nice not to bother with those headaches when GitHub will do it for free! At runtime the extension does a graceful fallback to pure-Python if the native module is missing. The Settings -> Python -> Test button shows you whether Cython is active.
The 150 lines of Cython take 200KB per platform and Python version, but that is the first-time Cython tax. Any new functions will take a tiny amount of additional space. I’m not sure if I’ll find another reason to write this native code, but it’s nice to have the infrastructure. For now I ship x64 Linux binaries, giving the cool kids the perf benefits, while keeping the extension portable for the rest.
Thanks for reading! Try it out, and tell me what breaks, this is still early: https://github.com/KeithCu/writeragent
If you enjoyed this article, here are the rest in the series:
Week 1: Initial fork, sidebar chat, multi-turn tools, and async streaming
Week 2 & 3: MCP, research sub-agent, voice support, and evaluation dashboard
Week 4-6: State machines, formal verification, and specialized toolsets
Week 6 & 7: Async grammar checking and TeX import support