Artificial Intelligence
Category: Amazon Bedrock Knowledge Bases
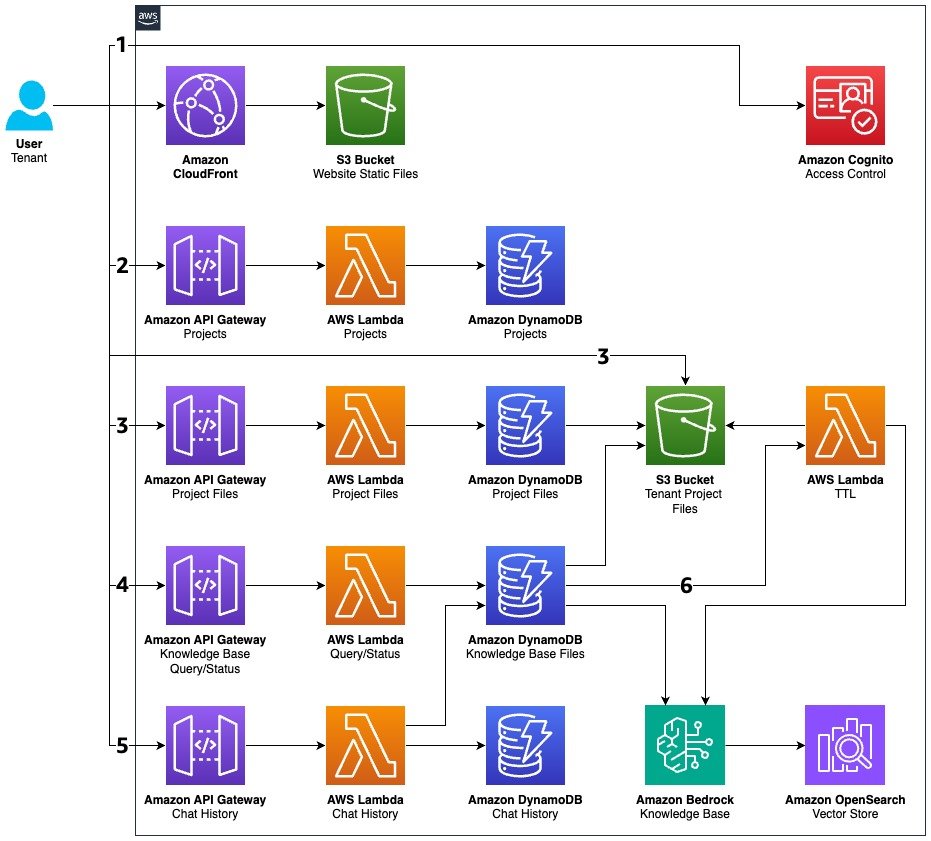
Build a just-in-time knowledge base with Amazon Bedrock
Traditional Retrieval Augmented Generation (RAG) systems consume valuable resources by ingesting and maintaining embeddings for documents that might never be queried, resulting in unnecessary storage costs and reduced system efficiency. This post presents a just-in-time knowledge base solution that reduces unused consumption through intelligent document processing. The solution processes documents only when needed and automatically removes unused resources, so organizations can scale their document repositories without proportionally increasing infrastructure costs.

Choosing the right approach for generative AI-powered structured data retrieval
In this post, we explore five different patterns for implementing LLM-powered structured data query capabilities in AWS, including direct conversational interfaces, BI tool enhancements, and custom text-to-SQL solutions.

Revolutionizing drug data analysis using Amazon Bedrock multimodal RAG capabilities
In this post, we explore how Amazon Bedrock’s multimodal RAG capabilities revolutionize drug data analysis by efficiently processing complex medical documentation containing text, images, graphs, and tables.

Build an agentic multimodal AI assistant with Amazon Nova and Amazon Bedrock Data Automation
In this post, we demonstrate how agentic workflow patterns such as Retrieval Augmented Generation (RAG), multi-tool orchestration, and conditional routing with LangGraph enable end-to-end solutions that artificial intelligence and machine learning (AI/ML) developers and enterprise architects can adopt and extend. We walk through an example of a financial management AI assistant that can provide quantitative research and grounded financial advice by analyzing both the earnings call (audio) and the presentation slides (images), along with relevant financial data feeds.

Building a custom text-to-SQL agent using Amazon Bedrock and Converse API
Developing robust text-to-SQL capabilities is a critical challenge in the field of natural language processing (NLP) and database management. The complexity of NLP and database management increases in this field, particularly while dealing with complex queries and database structures. In this post, we introduce a straightforward but powerful solution with accompanying code to text-to-SQL using a custom agent implementation along with Amazon Bedrock and Converse API.

Build conversational interfaces for structured data using Amazon Bedrock Knowledge Bases
This post provides instructions to configure a structured data retrieval solution, with practical code examples and templates. It covers implementation samples and additional considerations, empowering you to quickly build and scale your conversational data interfaces.

Adobe enhances developer productivity using Amazon Bedrock Knowledge Bases
Adobe partnered with the AWS Generative AI Innovation Center, using Amazon Bedrock Knowledge Bases and the Vector Engine for Amazon OpenSearch Serverless. This solution dramatically improved their developer support system, resulting in a 20% increase in retrieval accuracy. In this post, we discuss the details of this solution and how Adobe enhances their developer productivity.

Contextual retrieval in Anthropic using Amazon Bedrock Knowledge Bases
Contextual retrieval enhances traditional RAG by adding chunk-specific explanatory context to each chunk before generating embeddings. This approach enriches the vector representation with relevant contextual information, enabling more accurate retrieval of semantically related content when responding to user queries. In this post, we demonstrate how to use contextual retrieval with Anthropic and Amazon Bedrock Knowledge Bases.

Build GraphRAG applications using Amazon Bedrock Knowledge Bases
In this post, we explore how to use Graph-based Retrieval-Augmented Generation (GraphRAG) in Amazon Bedrock Knowledge Bases to build intelligent applications. Unlike traditional vector search, which retrieves documents based on similarity scores, knowledge graphs encode relationships between entities, allowing large language models (LLMs) to retrieve information with context-aware reasoning.

Create an agentic RAG application for advanced knowledge discovery with LlamaIndex, and Mistral in Amazon Bedrock
In this post, we demonstrate an example of building an agentic RAG application using the LlamaIndex framework. LlamaIndex is a framework that connects FMs with external data sources. It helps ingest, structure, and retrieve information from databases, APIs, PDFs, and more, enabling the agent and RAG for AI applications. This application serves as a research tool, using the Mistral Large 2 FM on Amazon Bedrock generate responses for the agent flow.