FLUX.1 Kontext, the recently released model from Black Forest Labs, is a fascinating addition to the repertoire of community image generation models. The open weights FLUX.1 Kontext [dev] variant, the focus of this post, is a model meticulously optimized for image-to-image transformation tasks. This pioneering tool stands out for its incremental image editing capabilities, offering a paradigm shift in guiding the generation process.
Unlike traditional methods that rely on crafting complex prompts and integrating hard-to-source masks or depth and edge maps, FLUX.1 Kontext [dev] empowers users with a more intuitive and flexible approach. By seamlessly integrating incremental editing with cutting-edge optimization techniques for diffusion model inference performance, this new model enables the delivery of a radically different user experience for graphical editing.
NVIDIA has collaborated with Black Forest Labs to optimize FLUX.1 Kontext [dev] for NVIDIA RTX GPUs using NVIDIA TensorRT and quantization to deliver faster inference with lower VRAM requirements. Building on the foundational work showcased in NVIDIA TensorRT Unlocks FP4 Image Generation for NVIDIA Blackwell GeForce RTX 50 Series GPUs, this post covers how low-precision quantization can revolutionize the user experience. For a comprehensive model description, refer to the Black Forest Labs technical report.
Multi-turn image editing
Traditionally, image-to-image models rely on text prompts supplemented by binary masks or depth/edge maps for refined control. However, this paradigm is cumbersome, demanding meticulous crafting of multiple inputs, which ultimately hinders the widespread adoption of these models.
FLUX.1 Kontext [dev] introduces a new approach, where users can selectively edit images based primarily on provided prompts (Figure 1). This innovation allows complex editing tasks to be seamlessly divided into multi-stage processes. Notably, the model preserves the semantic integrity of the original image across all stages.


Prompt: “Transform to Bauhaus style”

Prompt: “Change the colors to a pastel palette”
In the context of FLUX.1 Kontext [dev], inference speed matters, as a faster model enables the user to incrementally test new changes in a short cycle. This eventually culminates in a new chat-based UX for image editing. On the other hand, lower memory consumption is also important, as image generation pipelines are composed of multiple models. As the models become more powerful the required memory increases, limiting their adoptions. By quantizing models in lower precision, it is possible to execute such pipelines on more NVIDIA RTX hardware, increasing adoption or reducing inference cost.
As with previous work, the optimization work targeted NVIDIA Blackwell GPUs with fifth-generation Tensor Cores and native support for 4-bit floating point (FP4) operations. Tools used for this work include NVIDIA TensorRT Model Optimizer to perform quantization and TensorRT for inference runtime producing the final engines.
Pipeline and quantization
This section focuses on the computational aspects of the pipeline, analyzing critical components and optimization strategies to enhance performance.
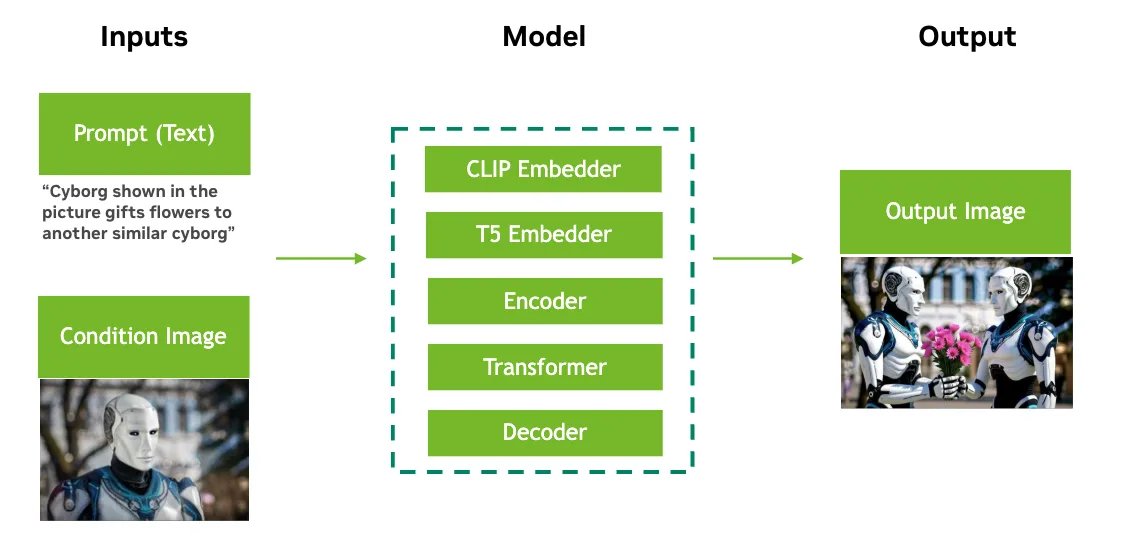
FLUX.1 [dev] models consist of several key modules: a vision-transformer backbone, an autoencoder, CLIP, and T5 (Figure 2). Notably, FLUX.1 Kontext [dev] differs from other variants (such as FLUX.1-Deph-dev) by converting input images into tokens, which are then concatenated to the output image tokens used during the diffusion process. This design choice has significant implications: it nearly doubles the context window length compared to other FLUX.1-dev variants, increasing both memory and computational demands. Early experiments demonstrated that the transformer module consumes approximately 96% of the total processing time, making it the ideal target for optimization.
The well-known Transformer architecture primarily comprises general matrix multiplication (GEMM) operations, such as those in linear layers, and scaled dot-product attention (SDPA) mechanisms. While substantial research has focused on quantization techniques for GEMM in various low-precision setups, less attention has been devoted to leveraging low-precision formats for the attention operation. A notable exception has been the SageAttention paper series.
Figure 3 highlights the computational impact of SDPA and GEMM kernels, accounting for about 75% of the transformer module’s total compute budget. Note how the Attention (SPDA) and Linear layer (GEMM) dominate the overall compute budget of the transformer module.
![Chart showing breakdown of all the kernels needed to execute the Transformer module used by FLUX.1 Kontext [dev] model.](https://developer-blogs.nvidia.com/wp-content/uploads/2025/06/chart-kernels-transformer-module-flux1-kontext-png.webp)
To balance accuracy and speed, the following quantization strategy was adopted for SDPA optimization:
- The Query, Key, and Value tokens are projected into a common vector space by a low-precision matrix-multiplication using per-tensor FP8 or per-block FP4 quantization, as specified in the quantization configuration.
- The output obtained from the first matrix-multiplication is accumulated in higher precision and an additional quantization operation is needed to convert the inputs of the first batched-matrix-multiplication (BMM1) into FP8. In other words, the projection QKT is executed in FP8.
- The Softmax operation is currently only supported in FP32, so no quantization is performed at this stage.
- The second batch multiplication (BMM2) is also computed using a per-tensor FP8 quantization setup.
The proposed quantization schema for SPDA is similar for both FP8 and FP4 variants, differing only in the precision used for Query, Key, and Value projections.
Figure 4 shows a graphical representation of this schema. Inputs are quantized using a per-block FP4 quantization schema. BMMs are computed in FP8 using a per-tensor quantization. Softmax is always executed in FP32. Finally, note that the Quant layer reported in the figure actually refers to the FakeQuantize operation.

Among the many quantization methodologies, the work focused on post-training quantization (PTQ) in FP8, PTQ in FP4, and SVD-Quant in FP4. The overall quantization process is conducted using the TensorRT Model Optimizer library while TensorRT is used as the compiler to fuse the various quantization kernels. The overall process is as follows:
- Define an appropriate quantization configuration used by TensorRT Model Optimizer.
- Use TensorRT Model Optimizer to inject the quantization layer according to the configuration into the original FLUX.1 Kontext [dev] model.
- Load a calibration dataset consisting of prompt/conditioning-image pairs.
- Use TensorRT Model Optimizer to perform post-training calibration.
- Export the quantized model into Open Neural Network Exchange (ONNX) model format.
- Use TensorRT to load the ONNX model and perform kernel fusion for the specific target hardware resulting in the final TensorRT engine.
Model output and performance
Table 1 reports the number of milliseconds required to perform a single diffusion step by the (quantized) vision transformer; thus smaller values indicating better efficiency. The performance improvement going from BF16 to FP8 is substantial, as the 8-bit precision reduces the memory bandwidth requirements and increases computational throughput. The smaller gains from FP4 compared to FP8 are attributed to two factors:
- Figure 3 shows how Attention is the dominant operator in the transformer modules. In the previous section it is explained how SPDA is mainly quantized in FP8 to preserve numerical stability; thus limiting end-to-end speedup of FP4 compared to FP8.
- The adoption of a context window twice as long as for other Flux1.dev models further affects FP4 benefits w.r.t. FP8 due to quadratic computational cost of the Attention operator.
| FP4 (ms) | FP8 (ms) | BF16 (ms) | |
| NVIDIA RTX 5090 | 273 | 358 | 669 |
| NVIDIA RTX PRO 6000 Blackwell Edition | 254 | 317 | 607 |
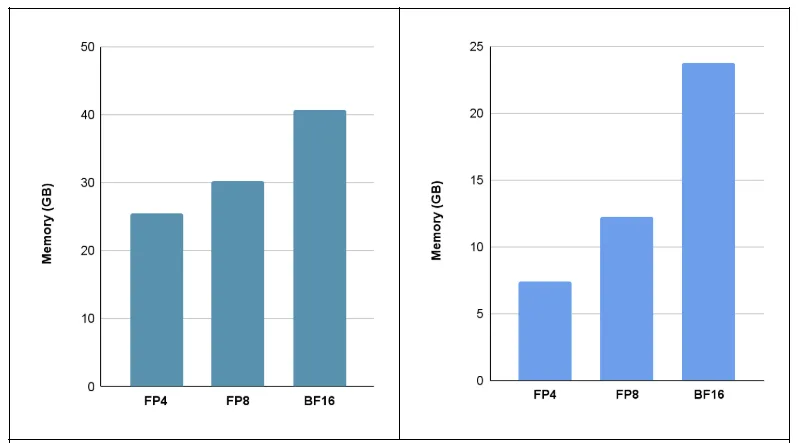
Figure 5 shows the memory usage of the FLUX.1 Kontext [dev] model across different numerical precisions. When focusing solely on the transformer backbone (Figure 5, right), low-precision quantization achieves approximately 2x and 3x memory savings when transitioning from BF16 to FP8 and FP4, respectively.
However, the overall memory reduction for the full pipeline is less significant, as the other components of the model are not quantized. Memory-efficient models are particularly valuable because they can be more easily deployed on consumer-grade GPUs, such as the 5090. Likewise, service providers can take advantage of reduced memory footprints to run multiple instances of the same model, thereby improving throughput and cost-efficiency.
Finally, Figures 6 and 7 show how the quality of low-precision models compare with respect to the full precision model.




Figure 6. Image editing performance of the FLUX.1 Kontext [dev] model in various precision formats for the
prompt, “Remove all the people in this image”




Summary
The acceleration of the FLUX.1 Kontext [dev] model could lead to a responsive user experience, thanks in part to its incremental editing capabilities. This synergy transforms the generation of captivating images into an interactive process, which will inspire the creative community to embrace this innovative approach to content creation.
From a technical standpoint, this post covered valuable insights into the TensorRT Model Optimizer approach to quantizing the scale-dot-product-attention operator—a pivotal component of transformer architectures. Researchers working on AI models can build upon this foundation and develop novel techniques that more effectively harness low-precision data types. Enhancing the inference-time efficiency of the Attention operator while maintaining high numerical accuracy could have a huge beneficial impact on the wider machine-learning community.
Similarly, model developers can leverage TensorRT Model Optimizer and TensorRT as reliable tools for accelerating inference and simplifying model deployment.
The union of the latest NVIDIA hardware with TensorRT and TensorRT Model Optimizer presents a formidable combination. This synergy democratizes access to cutting-edge AI technology, enabling a broader user base to leverage its power. By bridging the gap between cloud capabilities and local workstations, we are thrilled to bring the full potential of generative AI directly to your desktop.