Desenvolvendo Aplicações baseadas em Big Data com PySpark
1 gostou•489 visualizações

Este documento fornece uma introdução ao processamento de Big Data com PySpark. Resume os principais conceitos como MapReduce, Apache Spark, Resilient Distributed Dataset (RDD), e demonstra exemplos práticos de transformações e ações com RDD usando PySpark.



























![Map
A função de map é repetida em todas as linhas do RDD e gera um novo RDD como
saída. Usando a transformação map(), utilizamos qualquer função, e essa função é
aplicada a todos os elementos do RDD. Por exemplo, temos um RDD [1, 2, 3, 4, 5]
se aplicarmos “rdd.map(x => x + 2)”, será obtido o resultado (3, 4, 5, 6, 7).](https://image.slidesharecdn.com/caipyra2018-180608211412/85/Desenvolvendo-Aplicacoes-baseadas-em-Big-Data-com-PySpark-29-320.jpg)
















Desenvolvendo Aplicações baseadas em Big Data com PySpark
- 1. Desenvolvendo Aplicações baseadas em Big Data com PySpark
- 2. Sobre Vinícius Aires Barros Ciência da Computação 2016 - UFT Mestrando em Ciência da Computação - ICMC USP Laboratório de Sistemas Distribuídos e Programação Concorrente - LaSDPC Áreas de Interesse: IoT, Distributed Systems, Big Data e Data Science. GitHub: @v4ires Website: http://viniciusaires.me E-mail: [email protected]
- 3. Big Data Sinônimo de grande volume de dados?
- 4. “Big Data é definido como um conjunto de dados estruturados ou não estruturados que não puderam ser percebidos, adquiridos, gerenciados e processados pelos modelos tradicionais de hardware e software”.
- 5. Conceitos ● Grandes Volumes de Dados ● Programação de Alto Desempenho (HPC) ● Dados Estruturados, Não Estruturados e Semiestruturados ● Bancos de Dados SQL e NoSQL ● MapReduce ● Apache Hadoop, Spark, etc.
- 6. Timeline 6 Apache HadoopMapReduce 2003 Google File System 2004 2006 Spark UC Berkeley Lab 2009 Apache Spark 2013 Apache Spark se torna um projeto Top Level da Apache 2014
- 7. 4V’s do Big Data
- 8. Sistemas de Arquivos Distribuídos
- 9. Bancos de Dados Distribuídos
- 10. Casos de Uso ● Sistemas de Recomendação ● Aprendizagem de Máquina ● Processamento de Imagens ● Mineração de Dados ● etc.
- 11. Desafios ● Escalabilidade ● Dados Complexos ● Interoperabilidade ● Latência ● Velocidade de Escrita em Disco e de RAM ● etc.
- 12. Modelo de Programação MapReduce ● Google ● Programação Paralela/Disribuída; ● Funções: Map & Reduce; ● Simplificação dos modelos de programação paralela e concorrente tradicionais; ● Tolerância a falhas; ● Escalabilidade.
- 14. Lightning-fast unified analytics engine Apache Spark
- 15. O que é o Apache Spark? O Apache Spark é um software de código aberto mantido pela Apache Foundation que tem como propósito fornecer uma implementação livre e melhorada do modelo de programação MapReduce.
- 16. Características ❏ Implementação em Scala ❏ Arquitetura Mestre Escravo (Master/Slave) ❏ Modelo de Programação MapReduce ❏ Resilient Distributed Dataset (RDD) ❏ Memória Principal (RAM) ❏ Processamento Distribuído ❏ Processamento em Tempo Real ❏ Escalável ❏ Tolerante a Falhas ❏ Integração com HDFS
- 17. O que não é? ❏ Linguagem de Programação ❏ Solução Definitiva ❏ Substituto do Apache Hadoop
- 19. Resilient Distributed Dataset (RDD)
- 20. Quem utiliza?
- 22. Execução do Apache Spark 1. Acessem: http://github.com/v4ires/caipyra-2 018-pyspark 2. Tenham o docker instalado 3. Executem o Container 4. Pronto :)
- 23. PySpark (Python + Spark) ● Interface de programação em Python ● Py4J (Interface de integração do Java com Python) ● Modo Iterativo de Programação ● Suporte a Python 2 e 3 ● Integração com Jupyter ● Integração com bibliotecas Python (Scipy, Matplotlib, Seaborn...)
- 24. Operadores PySpark ● Transformações ○ Map ○ FlatMap ○ Filter ○ GroupByKey ○ outros. ● Ações: ○ Take ○ Count ○ Collect ○ outros.
- 26. Exemplo Prático I WordCount (Contador de Palavras)
- 27. Hello World (World Count)
- 28. Transformações Alguns exemplos de transformações com RDD
- 29. Map A função de map é repetida em todas as linhas do RDD e gera um novo RDD como saída. Usando a transformação map(), utilizamos qualquer função, e essa função é aplicada a todos os elementos do RDD. Por exemplo, temos um RDD [1, 2, 3, 4, 5] se aplicarmos “rdd.map(x => x + 2)”, será obtido o resultado (3, 4, 5, 6, 7).
- 30. FlatMap Na função flatMap() para cada elemento de entrada temos muitos elementos em um RDD de saída. O uso mais simples de flatMap() é dividir cada string de entrada em palavras. Map e flatMap são semelhantes na maneira que eles pegam uma linha da entrada RDD e aplicam uma função nessa linha. A principal diferença entre map() e flatMap() é que a função map() retorna apenas um elemento, enquanto flatMap() pode retornar uma lista de elementos.
- 31. Filter A função RDD filter() retorna um novo RDD, contendo apenas os elementos que atendem a um predicado. Por exemplo, suponha que o RDD contenha primeiro cinco números naturais (1, 2, 3, 4 e 5) e o predicado é verificar os números pares. O RDD resultante após aplicar a função filter() conterá apenas os números pares, ou seja, 2 e 4.
- 32. GroupByKey Quando usamos groupByKey() em um conjunto de dados de pares (K, V), os dados são embaralhados de acordo com o valor da chave K em um outro RDD.
- 33. ReduceByKey Quando usamos reduceByKey em um dataset (K, V), os pares na mesma máquina com a mesma chave são combinados antes que os dados sejam embaralhados.
- 34. Union Com a função union(), obtemos a união de dois RDD em um novo RDD. A principal regra dessa função é que os dois RDDs devem ser do mesmo tipo. Por exemplo, os elementos do RDD1 são {“Spark”, “Spark”, “Hadoop”, “Flink”} e os do RDD2 são {“Big data”, “Spark”, “Flink”}, portanto, o rdd1.union(rdd2) resultará nos seguintes elementos {“Spark”, “Spark”, “Spark”, “Hadoop”, “Flink”, “Flink”, “Big Data”}.
- 35. SortByKey Quando aplicamos a função sortByKey() em um conjunto de dados de pares (K, V), os dados são classificados de acordo com a chave K em outro RDD.
- 36. Ações Alguns exemplos de ações com RDD
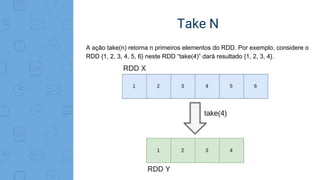
- 37. Take N A ação take(n) retorna n primeiros elementos do RDD. Por exemplo, considere o RDD {1, 2, 3, 4, 5, 6} neste RDD “take(4)” dará resultado {1, 2, 3, 4}.
- 38. Top N A ação top(n) retorna n últimos elementos do RDD. Por exemplo, considere o RDD {1, 2, 3, 4, 5, 6} neste RDD “top(4)” dará resultado {6, 5, 4, 3}.
- 39. Count A ação count() retorna o número de elementos no RDD. Por exemplo, o RDD possui valores {1, 2, 3, 4, 6} neste RDD a função “count ()” irá retornar o valor 6.
- 40. Collect A ação collect() é a operação comum e simples que retorna todo o conteúdo de um RDD para um contexto de memória local. A ação collect() tem como restrição a capacidade de memória local de armazenar todos dos dados contidos em um RDD.
- 41. Reduce A função reduce() pega grupos de elementos como entrada do RDD e, em seguida, produz a saída do mesmo tipo. Diversos operadores podem ser utilizados na operação de redução, por exemplo, adição, subtração, multiplicação, divisão, dentre outros.
- 42. ForEach Quando temos uma situação em que queremos aplicar a operação em cada elemento do RDD, mas não deve retornar o valor para o driver. Neste caso, a função foreach() é útil. Por exemplo, inserindo um registro no banco de dados.
- 43. MLlib Biblioteca de Aprendizagem de Máquina
- 44. K-Means ● Algoritmo de aprendizagem de Máquina Não Supervisionado ● Algoritmo de Agrupamento ou Clusterização ● Versão otimizada para uso de programação paralela/concorrente ● Medida de Distância (Similaridade de Dados)
- 45. Outros exemplos Exemplos de códigos
- 46. Obrigado! Dúvidas? Você pode me encontrar: ▸ @v4ires ▸ [email protected]