NLP | Named Entity Chunker Training
Last Updated :
08 Jul, 2025
Named Entity Recognition (NER) is a task in Natural Language Processing (NLP) that involves identifying real-world entities such as names of people, locations, organizations and more within text. While modern NER tools like SpaCy and HuggingFace offer pre-trained models, building a custom chunker provides deeper insights into how entity recognition works and allows adaptation to domain-specific contexts.
Custom Named Entity Chunker
A custom chunker is useful and it should be built when:
- Pre-trained models fail to capture domain-specific entities.
- We want to experiment with supervised chunking techniques.
- Transparency and explainability are essential (In research or education).
The IEER corpus (Information Extraction: Entity Recognition) contains manually annotated named entity trees. However, it lacks POS-tagged tokens and sentence segmentation, which makes it more complex to process.
To train a sequence-based chunker, the chunk trees from IEER must be converted into the IOB format, which is a standard tagging scheme representing entity boundaries using B-, I-, and O prefixes.
The function below performs this conversion:
- ieertree2conlltags(tree, tagger=nltk.pos_tag) converts a chunked sentence from the IEER corpus into a list of triplets: (word, POS tag, IOB tag).
- This prepares the data for training a named entity chunker using sequence labeling.
Python
import nltk
nltk.download('ieer')
nltk.download('averaged_perceptron_tagger_eng')
nltk.download('treebank')
from nltk.corpus import ieer
def ieertree2conlltags(tree, tagger=nltk.pos_tag):
# Extract (word, entity_label) pairs
words, labels = zip(*tree.pos())
iob_tags = []
previous_label = None
for label in labels:
if label == tree.label():
iob_tags.append("O")
previous_label = None
elif label == previous_label:
iob_tags.append("I-" + label)
else:
iob_tags.append("B-" + label)
previous_label = label
# Apply POS tagging
words, pos_tags = zip(*tagger(words))
return list(zip(words, pos_tags, iob_tags))
Creating Chunked Sentences from the Corpus
Each IEER document is parsed as a single tree, so we need to yield chunked sentence-like structures from the converted IOB tags using conlltags2tree().
- ieer.parsed_docs(): Loads all documents from the IEER corpus as parsed trees.
- doc.text: Extracts the chunked tree structure (not POS-tagged) from the document.
- ieertree2conlltags(): Converts the tree into (word, POS, IOB) triplets using a POS tagger.
- conlltags2tree(): Reconstructs a chunked NLTK tree from the triplets.
- yield: Returns one chunked tree at a time as a generator.
Python
from nltk.chunk.util import conlltags2tree
def ieer_chunked_sents(tagger=nltk.pos_tag):
for doc in ieer.parsed_docs():
iob_triplets = ieertree2conlltags(doc.text, tagger)
yield conlltags2tree(iob_triplets)
This generator yields nltk. Tree structures that represent named entity chunks and can be used for training or testing.
Created Classifier Chunker
The code defines a custom chunker class ClassifierChunker that uses a Naive Bayes classifier to learn and predict IOB chunk tags (e.g., B-PERSON, I-LOCATION, O) from annotated training data.
- __init__(): Initializes the chunker and trains it using chunked trees.
- _prepare_training_data(): Converts chunked trees into (features, IOB-tag) pairs for classifier training.
- parse(): Takes a POS-tagged sentence, predicts chunk tags and returns a chunked tree.
- _default_features(): Extracts contextual features such as current word/POS, previous/next POS, previous tag, capitalization and whether the word is numeric.
Python
from nltk.chunk import ChunkParserI
from nltk.chunk.util import tree2conlltags, conlltags2tree
from nltk.classify import NaiveBayesClassifier
from typing import List, Tuple, Callable
class ClassifierChunker(ChunkParserI):
def __init__(self, train_sentences: List[nltk.Tree],
feature_func: Callable = None):
self.feature_func = feature_func or self._default_features
training_data = self._prepare_training_data(train_sentences)
self.classifier = NaiveBayesClassifier.train(training_data)
def _prepare_training_data(self, sentences: List[nltk.Tree]):
data = []
for tree in sentences:
conll_tags = tree2conlltags(tree)
history = []
for i, (word, pos, tag) in enumerate(conll_tags):
features = self.feature_func(conll_tags, i, history)
data.append((features, tag))
history.append(tag)
return data
def parse(self, sentence: List[Tuple[str, str]]) -> nltk.Tree:
history = []
conll_tags = []
for i, (word, pos) in enumerate(sentence):
features = self.feature_func(sentence, i, history)
tag = self.classifier.classify(features)
conll_tags.append((word, pos, tag))
history.append(tag)
return conlltags2tree(conll_tags)
def _default_features(self, sent, i, history):
word, pos = sent[i][0], sent[i][1]
prev_pos = sent[i - 1][1] if i > 0 else "<START>"
next_pos = sent[i + 1][1] if i < len(sent) - 1 else "<END>"
prev_tag = history[i - 1] if i > 0 else "<START>"
return {
"word": word,
"pos": pos,
"prev_pos": prev_pos,
"next_pos": next_pos,
"prev_tag": prev_tag,
"is_capitalized": word[0].isupper(),
"is_numeric": word.isdigit(),
"pos+word": f"{pos}_{word}"
}
Training the Classifier-Based Chunker
We use the ClassifierChunker class to learn patterns from the chunked sentences.
- ieer_chunked_sents(): Converts IEER documents into chunked trees using IOB tags.
- ieer_chunks = list(...): Loads all 94 IEER chunked trees into a list.
- Training/Testing Split: train_data: First 80 chunked trees for training, test_data: Remaining 14 trees for testing.
- ClassifierChunker(train_data): Initializes and trains the custom Naive Bayes chunker using the training set.
- treebank_chunk.tagged_sents()[0]: Fetches a POS-tagged sentence from the Treebank corpus.
- chunker.parse(...): Applies the trained model to the sentence, returning a chunked nltk.Tree.
Python
from nltk.corpus import treebank_chunk
from chunkers import ClassifierChunker # Must be implemented or imported
# Load chunked examples from IEER
ieer_chunks = list(ieer_chunked_sents())
print("Length of ieer_chunks :", len(ieer_chunks)) # Output: 94
# Split into training and testing sets
train_data = ieer_chunks[:80]
test_data = ieer_chunks[80:]
# Initialize and train the classifier-based chunker
chunker = ClassifierChunker(train_data)
# Parse a tagged sentence from the Treebank corpus
sample_sentence = treebank_chunk.tagged_sents()[0]
parsed_output = chunker.parse(sample_sentence)
print("\nparsing :\n", parsed_output)
Output:
 Chunker Output
Chunker OutputHere, "Pierre Vinken" is tagged as a LOCATION, "61 years" as a DURATION, and "Nov. 29" as a DATE. These are extracted as entity chunks by the trained model.
Evaluation on Test Data
To assess the chunker's performance, we use NLTK's built-in evaluation metrics: accuracy, precision and recall.
Python
results = chunker.evaluate(test_data)
print("\nAccuracy :", results.accuracy())
print("Precision:", results.precision())
print("Recall :", results.recall())
Output:
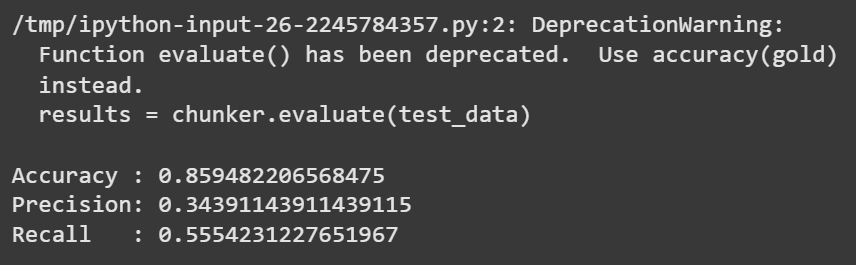 Evaluation results
Evaluation resultsThe model shows good accuracy, but precision and recall are relatively modest due to:
- Small corpus size (only 94 documents)
- Lack of sentence segmentation in IEER
- Reliance on auto-generated POS tags
You can Download the complete code from - here
Challenges
- Corpus Size: The IEER corpus is limited to 94 documents, restricting the model's ability to generalize.
- Sentence Granularity: IEER treats each document as one large tree, leading to unnatural training examples.
- POS Tagging: POS tags are tested using nltk.pos_tag() and are not gold-standard, which can have possible inconsistencies.
- Chunker Features: Unless ClassifierChunker is enhanced with contextual features, its performance will remain limited.
Training a named entity chunker from the IEER corpus offers a good understanding of sequence labeling and chunk-based NER. Though small and noisy, the corpus provides structured annotations that make it suitable for prototyping and experimentation.
Similar Reads
Named Entity Recognition in NLP In this article, we'll dive into the various concepts related to NER, explain the steps involved in the process, and understand it with some good examples. Named Entity Recognition (NER) is a critical component of Natural Language Processing (NLP) that has gained significant attention and research i
6 min read
NLP | Training Tagger Based Chunker | Set 1 To train a chunker is an alternative to manually specifying regular expression (regex) chunk patterns. But manually training to specify the expression is a tedious task to do as it follows the hit and trial method to get the exact right patterns. So, existing corpus data can be used to train chunker
2 min read
NLP | Training Tagger Based Chunker | Set 2 Conll2000 corpus defines the chunks using IOB tags. It specifies where the chunk begins and ends, along with its types.A part-of-speech tagger can be trained on these IOB tags to further power a ChunkerI subclass.First using the chunked_sents() method of corpus, a tree is obtained and is then transf
3 min read
Named Entity Recognition Named Entity Recognition (NER) in NLP focuses on identifying and categorizing important information known as entities in text. These entities can be names of people, places, organizations, dates, etc. It helps in transforming unstructured text into structured information which helps in tasks like te
5 min read
NLP | Splitting and Merging Chunks In natural language processing (NLP), text division into pieces that are smaller and easier to handle with subsequent recombination is an essential process. These actions, referred to as splitting and merging, enable systems to comprehend the language structure more effectively and allow for analysi
3 min read
Transfer Learning in NLP Transfer learning is an important tool in natural language processing (NLP) that helps build powerful models without needing massive amounts of data. This article explains what transfer learning is, why it's important in NLP, and how it works. Table of Content Why Transfer Learning is important in N
15+ min read