
















![Create a Document
POST /my_index_name/my_type_name
{
"title": "Elastic is funny",
"tag": [
"lucene"
]
}](https://image.slidesharecdn.com/elasticsearch-anoverview-170927073206/85/Elasticsearch-an-overview-19-320.jpg)
![Update a Document
PUT /my_index_name/my_type_name/12abc <This is the Document ID>
{
"title": "Elastic is funny",
"tag": [
"lucene"
]
}](https://image.slidesharecdn.com/elasticsearch-anoverview-170927073206/85/Elasticsearch-an-overview-20-320.jpg)





![Components of a response from Search
{
"took": 1,
"timed_out": false,
"_shards":{
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits":{
"total" : 1,
"max_score": 1.3862944,
"hits" : [
{
"_index" : "twitter",
"_type" : "tweet",
"_id" : "0",
"_score": 1.3862944,
"_source" : {
"user" :
"kimchy",
"message":
"trying out Elasticsearch",
"date" :
"2009-11-15T14:12:12",
"likes" :
0
}
}
]
}](https://image.slidesharecdn.com/elasticsearch-anoverview-170927073206/85/Elasticsearch-an-overview-26-320.jpg)



![Simple Queries / Filters
Term Query
{
"query": {
"term" : {
"user" : "Kimchy"
}
}
}
Terms Query
{
"query": {
"term" : { "user" :
["Kimchy", “Ash”] }
}
}
Multi Match
{
"query": {
"multi_match" : {
"query" : "lucene",
"fields" :
["title","tags"],
}
}
}](https://image.slidesharecdn.com/elasticsearch-anoverview-170927073206/85/Elasticsearch-an-overview-30-320.jpg)





![Create an Alias for multiple Indicies
POST /_aliases
{
"actions":
{
"add": {
"indices": ["my_index_name","my_index_name2"]
"alias": "alias_name_1",
}
}
}](https://image.slidesharecdn.com/elasticsearch-anoverview-170927073206/85/Elasticsearch-an-overview-36-320.jpg)






Elasticsearch an overview
- 1. Created by - Amit Juneja
- 2. PART 1 - Overview and Real World Applications
- 3. The Problem ● You are selling beer online ● You have a huge database of beers and brewreis ( Approx ~ 2 million ) ● You want simple keyword based searching ● You also want structured searching ( All beers > 7% ABV ) ● You want some real time analytics on how many beers are being viewed and bought
- 4. Enter Elasticsearch ● Lucene Based ● Distributed ● Fast ● RESTful interface ● Document-Based with JSON ● Real Time search and analytics engine ● Open Source - Apache licence ● Platform Independent
- 5. Why not Relational Database Management Systems (RDBMS) ? ● Full text search generally slower ● Cannot provide relevancy score for results ● Not suitable for unstructured data ● Limited partition tolerance ( cannot be distributed easily )
- 6. Elasticsearch - Basic Terminology
- 8. Real World Use Case 1 - Dell ● Switched to Elasticsearch to index 27 million documents which contained product information ● Dell uses two Elasticsearch cluster running on Windows server (.NET framework) ● Dell uses one cluster for searching and the other for analytics. The analytics cluster has 1 billion documents with their site and product analytics ● Dell leveraged Elasticsearch’s real time feature to create a virtual assistant which gives relevant suggestions based on partial keywords
- 9. Real World Use Case 1 - The Guardian ● Switched to Elasticsearch for realtime insight into audience engagement ● Every user with access privileges can see realtime traffic and viewership data for stories on The Guardian which helps them modify content to attract more traffic and get more exposure during peak rates ● The guardian processes 27 million documents per day with their in house analytics system which consists of Elasticsearch at the core ● Dell leveraged Elasticsearch’s real time feature to create a virtual assistant which gives relevant suggestions based on partial keywords
- 10. shardsMaster Client 1 Client 2
- 11. Inverted Index
- 12. Part 2 - Indexing, Updating and Deleting
- 13. Mapping in Elasticsearch ● Each index can have different types ● You can define the datatype of fields in a type with mapping { “sample_index” : { “mappings” : { “sample_type1” : { “properties” : { “date_a_sample_field” : { “type” : “date”, “format” : “dateOptionalTime” } } } } } }
- 14. Data Types available in Elasticsearch Mapping ● Core Types ○ String ○ Numeric ○ Date ○ Boolean ● Arrays ● Multi-fields ● Pre-defined fields ( _timestamp, _uid, _ttle )
- 15. Creating an Index PUT /my_index_name { "settings": { "number_of_replicas": 1, "number_of_shards": 3, "analysis": {}, "refresh_interval": "1s" }, "mappings": { "my_type_name": { "properties": { "title": { "type": "text", "analyzer": "english" } } } } }
- 16. Update an Index Setting PUT /my_index_name/_settings { "index": { "refresh_interval": "-1", "number_of_replicas": 0 } }
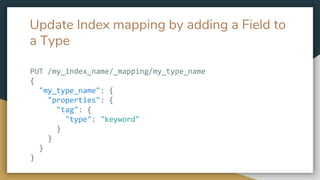
- 17. Update Index mapping by adding a Field to a Type PUT /my_index_name/_mapping/my_type_name { "my_type_name": { "properties": { "tag": { "type": "keyword" } } } }
- 18. Get Mapping and Settings GET /my_index_name/_mapping GET /my_index_name/_settings
- 19. Create a Document POST /my_index_name/my_type_name { "title": "Elastic is funny", "tag": [ "lucene" ] }
- 20. Update a Document PUT /my_index_name/my_type_name/12abc <This is the Document ID> { "title": "Elastic is funny", "tag": [ "lucene" ] }
- 21. Delete a Document DELETE /my_index_name/my_type_name/12abc Open / Close an Index to save memory/CPU POST /my_index_name/_close POST /my_index_name/_open
- 22. Part 3 - Searching and Filtering
- 23. Search Scopes GET /_search -d “...” ---> Entire cluster GET /index_name/_search -d “...” ----> Just the index GET /index_name/type_name/_search -d “...” ----> Just the type in the index GET /_all/type_name/_search -d “...” ----> All type with name type_name in the cluster GET /*/type_name/_search -d “...” ----> All type with name type_name in the cluster GET /index_name_1,index_name_2/type_name_1,type_name_2/_search -d “...” -----> the types in the indexes
- 24. Basic components of a Search request ● Query : Configures the best documents to return based on a score ● Size : Amount of documents to return ● From : Used to do pagination. Can be expensive since ES orders results. Example - A value of 7 will return result from 8th result ● _source : The fields to return with the result ● Sort : Default or customized sorting for results
- 25. URL based search requests GET /index_name/_search?from=7&size=5 GET /index_name/_search?sort=date:asc GET /index_name/_search?sort=date:asc&q=title:elasticsearch
- 26. Components of a response from Search { "took": 1, "timed_out": false, "_shards":{ "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits":{ "total" : 1, "max_score": 1.3862944, "hits" : [ { "_index" : "twitter", "_type" : "tweet", "_id" : "0", "_score": 1.3862944, "_source" : { "user" : "kimchy", "message": "trying out Elasticsearch", "date" : "2009-11-15T14:12:12", "likes" : 0 } } ] }
- 27. Query DSL GET _search { "query": { "match": { "FIELD": "TEXT" } } } GET _search { "query": { "match_all": {} } }
- 28. Filters ● Filters perform a simple YES/NO operation on the documents to form the result set
- 29. Example of a Query with filter { "query": { "bool": { "must": { "match": { "text": "quick brown fox" } }, "filter": { "term": { "status": "published" } } }
- 30. Simple Queries / Filters Term Query { "query": { "term" : { "user" : "Kimchy" } } } Terms Query { "query": { "term" : { "user" : ["Kimchy", “Ash”] } } } Multi Match { "query": { "multi_match" : { "query" : "lucene", "fields" : ["title","tags"], } } }
- 31. More Queries / Filters Range Query { "query": { "range" : { "field_name" :{ "gte":"Value"} } } } Prefix query { "query": { "prefix" : { "title" : "elas"} } } Wildcard query { "query": { "wildcard" : { "title" : "ba*r?", } } }
- 32. bool Query must Combine clauses with AND must_not Combine clauses with binary NOT should Combine clauses with binary OR
- 33. Aliases in Elasticsearch ● Grouping multiple indexes or a single index and giving it an alias name for the purpose of querying / searching ● Aliases can be used with a filter to create multiple “views” of the same index
- 34. Create an Alias for single Index POST /_aliases { "actions": { "add": { "index": "my_index_name", "alias": "alias_name_1", } } }
- 35. Remove an Alias for single Index POST /_aliases { "actions": { "remove": { "index": "my_index_name", "alias": "alias_name_1", } } }
- 36. Create an Alias for multiple Indicies POST /_aliases { "actions": { "add": { "indices": ["my_index_name","my_index_name2"] "alias": "alias_name_1", } } }
- 37. Create an Alias for multiple Indicies with wildcard POST /_aliases { "actions": { "add": { "index": "my_index_name*" "alias": "alias_name_1", } } }
- 38. Create an Alias with filter term and routing value POST /_aliases { "actions": { "add": { "index": "my_index_name", "alias": "bar", "filter" : { "term" : { "customer_id" : "1" } } "routing" : 1 } } } Routing values can be used To avoid unnecessary shard operations They are added to the document automaticall And will be added to the search query which is Using the alias
- 39. Design Problem Your application has multiple users and each user has multiple subscriptions. Assume subscriptions follow the same format more or less What is the best way to design an elasticsearch cluster for this type of problem?
- 40. Potential Designs ● Have an index per user and each user has subscription documents Advantages ● Searches are fairly easy ● In line with relational database mentality ● Controlling shards and replica of each index gives us the advantage of independent scaling Disadvantages ● Too many shards! ● Waste of space as not all shards will have documents up to their capacity ● Couple thousand customers can make elasticsearch unresponsive
- 41. Potential Designs…(contd) ● Single Index + Aliasing Advantages ● No extra shards needed Disadvantages ● Each shard will be hit when querying making queries slower
- 42. Best Solution Single Index + Aliasing with Routing enabled ● Create alias for each customer in the single index ● Assign a routing key to each alias which is the same as customer id ● Now each query hits only specific shards making queries really fast