





















![References
[1]. Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott
Shenker, Ion Stoica,“Spark: Cluster Computing with Working
Sets”,University of California, Berkeley,2016.
[2]. Yanfeng Zhang, Qixin Gao, Lixin Gao, Cuirong Wang “PrIter: A
Distributed Framework for Prioritizing Iterative Computations, Parallel
and Distributed Systems”, IEEE Transactions onTransactions on Prallel
and Distributed Systems, vol.24, no.9, pp.1884, 1893, Sept.2016.
[3]. Matei Zaharia, Dhruba Borthakur, Joydeep Sen Sarma,Khaled
Elmeleegy Scott Shenker and IonStoic. “Delay scheduling: a simple
technique for achieving locality and fairness in cluster scheduling”,
Proceedings of the 5th European conference on Computer systems,
ACM New York 2016.](https://image.slidesharecdn.com/meripresentation-170423053802/85/Evolution-of-spark-framework-for-simplifying-data-analysis-26-320.jpg)


Evolution of spark framework for simplifying data analysis.
- 1. Evolution of Spark Framework for Simplifying Big Data Analytics Submitted By: Rishabh Verma Information Technology 1404313027 Submitted To: Prof. A.K.Solanki Head of Department
- 2. Content Types of data What is big data? What is Big Data Analytics? Facts on Big Data Characteristic of Big Data Traditional Approach Hadoop Hadoop Architecture HDFS and Mapreduce What is Spark? Spark Ecosystem Spark SQL Spark Streaming Mlib GraphX Comparison between Hadoop MapReduce and Apache Spark Conclusion
- 3. Types of Data Relational Data (Tables/Transaction/Legacy Data) Text Data (Web) Semi-structured Data (XML) Graph Data Social Network, Semantic Web (RDF) Streaming Data You can only scan the data once
- 4. What is Big Data? Similar to “smaller Data” but Bigger in Size.
- 5. What is Big Data Analytics? Examining large data set to find Hidden Pattern. Unknown correlations, market trends, customer preferences and other useful business information.
- 6. Facts on Big Data Over 90% of data was created in past two years only. Every minute we send 204 million emails, 1.8 million likes on facebook, send 28 thousands tweets, upload 200thousand photos on facebook. 3.5 billion thousand queries is received by google every day.
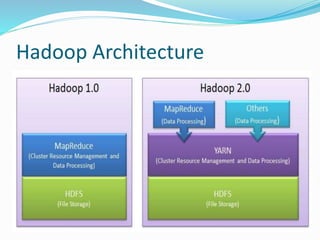
- 8. Traditional Approach-Hadoop An open-source framework, running application on large clusture. Used for distributed storage and processing of very large datasets using the MapReduce. Hadoop splits files into large blocks and distributes them across nodes in a cluster.
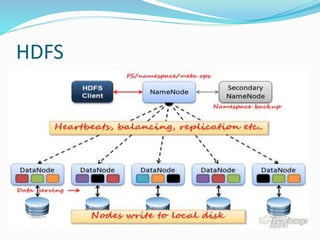
- 10. HDFS
- 11. HDFS Contain two type of node: Namenode(master) and number of Datanode(worker). Namenode manages filesystem tree and meta data of all the files. Datanode=workhorses, store and retrieve data on command of Namenode, continuosly send heartbeat signal to namenode. Data is replicated to ensure Fault Tolerance. Usually replication factor is 3.
- 12. MapReduce “Map” job sends a query for processing to various nodes in a Hadoop cluster and “Reduce” job collects all the results to output into a single value. Map: (in_value, in_key)=> (out_key, intermediate_value) Reduce: (out_key, intermediate_value)=>(out_value_list)
- 13. Map Reduce
- 14. MapReduce working Map-Reduce split input data-set to be processed by map task in parallel manner. Framework sort output of map which is input to reduce task. Input and output of the job is stored in the filesystem.
- 15. Apache Spark is a fast, in-memory data processing engine. Integration with Hadoop and its eco-system and can read existing data. Provide high level API in 1)Java 2)Scala 3)Python 10-100x Faster than MapReduce.
- 16. SPARK ECO-SYSTEM Spark SQL -For SQL and unstructured data. Mlib -Machine Learning Algorithms. GraphX -Graph Processing. Spark Streaming -stream processing of live data stream.
- 17. Integrated queries. -Spark SQL is a component on top of 'Spark Core' for structured data processing. HIVE Compatibility. -Spark SQL reuses the Hive frontend and metastore, giving you full compatibility with existing Hive data, queries, and UDFs Uniform Data Access -DataFrames and SQL provide a common way to access a variety of data sources, including Hive, Avro, Parquet, ORC, JSON, and JDBC
- 18. SPARK STREAMING Streaming data from data sources (e.g. live logs, system telemetry data, IoT device data, etc.) into some data ingestion system like Apache Kafka, Amazon Kinesis, etc. The data in parallel on a cluster. This is what stream processing engines are designed to do, as we will discuss in detail next. The results out to downstream systems like HBase, Cassandra, Kafka, etc.
- 20. Spark Streaming Easy, reliable, fast processing of live data streams. Fast failure and straggler recovery. Dynamic Load Balancing Found its application in cyber security, Online Advertisement and Campaign, IDS and alarms.
- 21. MLib Mlib is a low-level machine learning library that can be called from Scala, Python and Java programming languages. Perform multiple iteration to improve accuracy. Nine times as fast as the disk-based implementation used by Apache Mahout. Some algorithm used are- Clusturing: K-means. Decomposition: Principal Component Analysis (PCA) Regression: Linear Regression
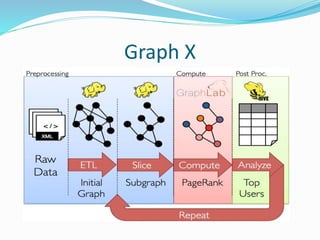
- 22. Graph X
- 23. Graph X Graph processing Library for Apache Spark. GraphX unifies ETL and iterative graph computation within a single system. RDG’s associate records with the vertices and edges in a graph and help them to exploit in less than 20 lines of code. Graph Frame an advancement in GraphX, provide uniform API for all 3 languages.
- 24. Advantage of spark over hadoop. APACHE SPARK HADOOP MapReduce 10-100X faster than Hadoop due to in memory computation. Slower than Spark, support disk based computation. Use to deal with data in real time. It is mainly focussed on Batch Processing. Spark ensures lower latency computations by caching the partial results across its memory of distributed workers. Map Reduce is completely Disk oriented. Perform streaming, batch processing, machine learning all in same clusture Hadoop Mapreduce is mainly used to generate report for historical queries.
- 25. CONCLUSION So to conclude with we can state that, the choice of Hadoop MapReduce vs. Apache Spark depends on the user-based case and we cannot make an autonomous choice.
- 26. References [1]. Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, Ion Stoica,“Spark: Cluster Computing with Working Sets”,University of California, Berkeley,2016. [2]. Yanfeng Zhang, Qixin Gao, Lixin Gao, Cuirong Wang “PrIter: A Distributed Framework for Prioritizing Iterative Computations, Parallel and Distributed Systems”, IEEE Transactions onTransactions on Prallel and Distributed Systems, vol.24, no.9, pp.1884, 1893, Sept.2016. [3]. Matei Zaharia, Dhruba Borthakur, Joydeep Sen Sarma,Khaled Elmeleegy Scott Shenker and IonStoic. “Delay scheduling: a simple technique for achieving locality and fairness in cluster scheduling”, Proceedings of the 5th European conference on Computer systems, ACM New York 2016.
Editor's Notes
- #24: ETL= extract transform load RDG resilient Distributive graphs