




































C19013010 the tutorial to build shared ai services session 1
- 1. The tutorial to build shared AI services --Session 1 Suqiang Song (Jack) Director & Chapter Leader of Data/AI Engineering @ Mastercard [email protected] https://www.linkedin.com/in/suqiang-song-72041716/
- 2. Agenda Module 1: Case study: AI as a Service (30 mins) • A typical end to end AI Service • Hidden truths of AI • Options of AI as a Service • The journey of AI as a Service • Challenges of traditional machine learning • How deep learning can improve • Enterprise requirements for AI as a Service • Deep learning approaches evaluation Session 1: Jan. 30th Wed 10am-12pm PT Module 2: Keras on Spark (30 mins) • Keras introduction • Options of Keras on Spark • Use case for user item propensity model • Build a User Item Propensity model with deep learning algorithms • Neural Collaborative Filtering deep learning algorithm Code Lab 1 (45 mins) • Build a Docker image and run a Keras on Spark container • Run the NCF deep learning pipeline for User Item Propensity model Q & A (15 mins)
- 3. Course Prerequisites • Install Docker at your local laptop • Download two Docker images from shared drive URL keras-py27-jupyter-cpu.tar and demo-whole.tar passcode : jack • Load images to your Docker environment https://1drv.ms/f/s!AsXKHMXBWUIBiBpaYk9FFjdoUifg $ docker load -i keras-py27-jupyter-cpu.tar $ docker load -i demo-whole.tar
- 4. Module 1
- 5. A typical end to end AI Service Personalized recommendations Services Client Data Data Lake Third Party Data Harmonize, link and scale Independent Variables Step 1: Data Inputs & Harmonization Propensity Engine Target Groups / Variables Propensities & Predictions Step 2: Features & Models Customer Preferences Offer limits and objectives Business rules & constraints Step 3: Business Rules Optimisation Engine Recommendations & Decisions Step 4: Optimisation Execution & Fulfilment Analysis & Results Step 5: Fulfilment & Analysis
- 6. Micro services + pipelines Recommendation Services ML /DL learning pipelines Historical + Incremental Data Sources Data Pipeline Bus Data Pipeline Engine Data Integration Pipelines RT, Rule and Batch Serving Pipelines RT, NRT and Batch Data Pipeline Bus Real Time Event Integration Batch Data Integration Business Rule Integration Online Systems CRM Files Transfer Data LakeMessage Bus Learning Pipelines ML/DL, His and Incremental Real Time Serving Streaming Serving Batch Serving Monitoring Metrics Metrics Pipelines Model Performance Metrics Monitoring Open APIs All kinds of Micro service Serving APIs Integration Endpoints
- 7. Published Recommendation Services (Open APIs ) Shared Serving pipelines Service n Service 1 Shared Serving Resource Pool (Repository) Batch Serving Processors User-Items Propensity Model Interactive Serving Processors APIs Call Flow APIs Compose Async Return Result APIs Call Flow APIs Compose Sync Return Result User-Items Propensity Model User Item Scoring User –User Similarity Searching Item-Item Similarity Searching User-User Ranking Item-Item Ranking Available Recommendation Services …..
- 8. “Hidden Technical Debt in Machine Learning Systems,” Google NIPS 2015 Figure 1: Only a small fraction of real-world ML systems is composed of the ML code. The required surrounding infrastructure is vast and complex. These include boundary erosion, entanglement, hidden feedback loops, undeclared consumers, data dependencies, configuration issues, changes in the external world, and a variety of system-level anti-patterns Hidden truths for AI
- 9. Hidden truths for AI – Where the debts ?
- 10. Hidden truths for AI -- continue Time Cost Data Exploration & Harmonization Features Engineering 0,0 Evaluation & Benchmarking Model Deployment &Serving $100,000 Months Modeling A Long and Expense Journey Data Collection Feature Extraction Configuration Data Verification Ml Code Process Management Tools Analysis Tools Serving Infrastructure Machine Resource Management Monitoring
- 11. Options of AI as a Service AI Applications Machine learning frameworks • Machine learning frameworks: Provide stable and secure environments and consolidate integrated wrappers on top of variable technologies for regular machine learning works • Applications build silos from scratch • Fully managed machine learning servic es use templates, pre-built models and drag-and-drop development tools to si mplify and expedite the process of usin g a machine learning framework • Applications share templates and pre- built models , assembly and infer them into pipelines or business context • Automation Services, tasks like explora tory data analysis, pre-processing of da ta, hyper-parameter tuning, model sele ction and putting models into producti on can be automated • “God's Return to God, Satan's Return to Satan , Math’s Return AI, Business’s Return Biz” Machine learning frameworks AI Applications Machine learning frameworks Fully managed machine learning services AI Applications On / Off Premise Advanced Infrastructure Fully managed machine learning services On / Off Premise Advanced Infrastructure On / Off Premise Advanced Infrastructure Automation Services
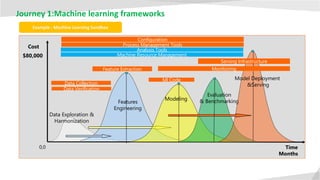
- 12. Journey 1:Machine learning frameworks Time Cost Data Exploration & Harmonization Features Engineering 0,0 Evaluation & Benchmarking Model Deployment &Serving $80,000 Months Modeling Example : Machine Learning Sandbox Data Collection Feature Extraction Configuration Data Verification Ml Code Process Management Tools Analysis Tools Serving Infrastructure Machine Resource Management Monitoring
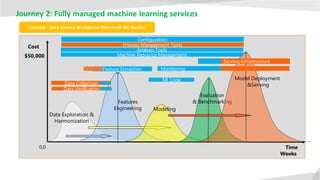
- 13. Journey 2: Fully managed machine learning services Time Cost Features Engineering 0,0 Evaluation & Benchmarking $50,000 Weeks Model Deployment &Serving Modeling Data Exploration & Harmonization Example : Data Science Workbench (Microsoft ML Studio) Data Collection Feature Extraction Configuration Data Verification Ml Code Process Management Tools Analysis Tools Serving Infrastructure Machine Resource Management Monitoring
- 14. Journey 3: Automation Services Time Cost Features Engineering 0,0 Evaluation & Benchmarking $10,000 Days Model Deployment &ServingData Exploration & Harmonization Modeling Example : Netflix , Amazon Sage Maker… Data Collection Feature Extraction Configuration Data Verification Ml Code Process Management Tools Analysis Tools Serving Infrastructure Machine Resource Management Monitoring
- 15. What we can learn from Netflix ? https://www.slideshare.net/FaisalZakariaSiddiqi/ml-infra-for-netflix-recommendations-ai-nextcon-talk
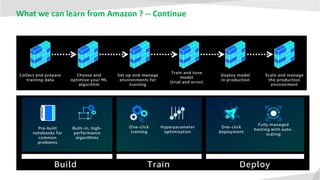
- 16. What we can learn from Amazon ?
- 17. What we can learn from Amazon ? -- Continue
- 18. What we can learn from Prediction IO ? http://predictionio.apache.org/
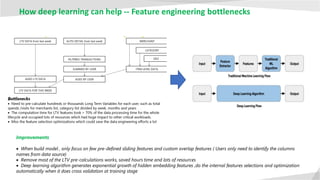
- 19. Feature engineering bottlenecks Pre-calculate hundreds or thousands Long Term Variables take lots of resources and times ( greater than 70%) Model scalability limitations Trade-off between automation in parallel and scaling machine learning to ever larger datasets and ever more complicated models Heavily relies on human machine learning experts Relies on human to perform the most of tasks, such as features selection, model selection, model hyper parameters tuning , critically analyze the results obtained… Isolated non-reusable APIs and CI/CD pipelines Application teams spent lots of time with data scientist to build high level serving APIs , back and force. Most of time are using different technical stacks and non-reusable pipelines. Isolated promotions and operation readiness without automate CI/CD Less integration with end to end data pipelines and serving multiple contexts Gap to bring machine learning process into the existing enterprise data pipelines and application contexts including offline, streaming and real-time 1 2 3 4 5 Learning Serving Challenges of traditional machine learning
- 20. How deep learning can help -- Feature engineering bottlenecks Improvements • When build model , only focus on few pre-defined sliding features and custom overlap features ( Users only need to identify the columns names from data source) • Remove most of the LTV pre-calculations works, saved hours time and lots of resources • Deep learning algorithm generates exponential growth of hidden embedding features ,do the internal features selections and optimization automatically when it does cross validation at training stage
- 21. How deep learning can help -- Heavily relies on human machine learning experts Improvements • Common neural network "tricks", including initialization, L2 and dropout regularization, Batch normalization, gradient checking • A variety of optimization algorithms, such as mini-batch gradient descent, Momentum, RMSprop and Adam • Provides optimization-as-a-service using an ensemble of optimization strategies, allowing practitioners to efficiently optimize models faster and cheaper than standard approaches.
- 22. How deep learning can help -- Model scalability Improvements • Scale models in deeper and wider without decreasing metrics NCF Wide And Deep LR
- 23. Seamless integration with Products Internal & External • Add deep learning capabilities to existing Analytic Applications and/or machine learning workflows rather than rebuild all of them Collocated with mass data storage • Analyze a large amount of data on the same Big Data clusters where the data are stored (HDFS, HBase, Hive, etc.) rather than move or duplicate data Shared infrastructure with Multi- tenant isolated resources • Leverage existing Big Data clusters and deep learning workloads should be managed and monitored with other workloads (ETL, data warehouse, traditional ML etc..) rather than run ML/DL workloads standalone in separate clusters Data governance with restricted Processing • Follow data privacy, regulation and compliance ( such as PCI/PII compliance and GDPR rather than operate data in unsecured zones Adopt structured sparse data sets • More challenges also more benefits to adopt structured high dimensional sparse data sets rather than non-structured dense data sets Automation and easy to go • End to end automation rather than manual efforts • Easy API enablement rather than big learning curve or depend on special experts Enterprise requirements for AI as a Service
- 24. • Examples are good for dense high sample size data sets (But won’t help us ) • Claimed that the GPU computing are better than CPU which requires new hardware infrastructure (very long timeline normally ) • Success requires many engineer-hours ( Impossible to Install a Tensor Flow Cluster at STAGE ...) • Low level APIs with steep learning curve ( Where is your PhD degree ? ) • Not well integrated with other enterprise tools and need data movements (couldn't leverage the existing ETL, data warehousing and other analytic relevant data pipelines, technologies and tool sets. And it is also a big challenge to make duplicate data pipelines and data copy to the capacity and performance.) • Tedious and fragile to distribute computations ( less monitoring ) • The concerns of Enterprise Maturity and InfoSec ( such as use GPU cluster with Tensor Flow from Google Cloud ) ………….. Deep learning approaches evaluation -- Super Stars
- 25. Module 2
- 26. Keras introduction -- Introduce a simple play ground , not just for Keras https://github.com/ufoym/deepo
- 27. Keras introduction -- Basic concepts Keras: an API for specifying & training differentiable programs Keras is the official high-level API of TensorFlow
- 28. Keras introduction -- Three API styles The Sequential Model • - Dead simple • - Only for single-input, single-output, sequential layer stacks • - Good for 70+% of use cases The functional API • - Like playing with Lego bricks • - Multi-input, multi-output, arbitrary static graph topologies • - Good for 95% of use cases Model subclassing • - Maximum flexibility • - Larger potential error surface
- 29. Keras introduction -- Example for entry : MINST by MLP and CNN
- 30. Code time ! $ docker run -it -p 8888:8888 --ipc=host ufoym/deepo:all-py27-jupyter-cpu jupyter notebook --no-browser --ip=0.0.0.0 --allow-root --NotebookApp.token="demo" -- notebook-dir='/root'
- 31. Why Spark ?
- 32. What does Spark offer for deep learning ? Integrations with existing DL libraries • Deep Learning Pipelines (from Databricks) • Caffe (CaffeOnSpark) • Keras (Elephas) • mxnet • Paddle • TensorFlow (TensorFlow on Spark, TensorFrames) • CNTK (mmlspark) Implementations of DL on Spark • BigDL+ Analytic Zoo • DeepDist • DeepLearning4J • SparkCL • SparkNet
- 33. Options of Keras on Spark
- 34. Why BigDL ?
- 35. https://github.com/intel-analytics/analytics-zoo Analytics Zoo -> Unified Analytics + AI Platform for Spark and BigDL Why Analytics Zoo ?
- 36. Use case for user item propensity model https://catalog.data.gov/dataset/purchase-card-pcard-fiscal-year-2014
- 37. Build a User Item Propensity model with deep learning algorithms
- 38. Neural Collaborative Filtering deep learning algorithm https://arxiv.org/pdf/1708.05031.pdf https://github.com/hexiangnan/neural_collaborative_filtering
- 39. Code Lab 1 $ docker run -it -p 8080:8080 -p 8443:8443 -p 10000:10000 -p 8998:8998 -p 12345:12345 -p 8088:8088 -p 4040:4040 -p 7077:7077 -e NotebookPort=12345 - e NotebookToken="demo" -e RUNTIME_DRIVER_CORES_ENV=1-e RUNTIME_DRIVER_MEMORY=2g -e RUNTIME_EXECUTOR_CORES=1 -e RUNTIME_EXECUTOR_MEMORY=4g -e RUNTIME_TOTAL_EXECUTOR_CORES=1 --name demo -h demo demo:latest bash
- 40. Build a Docker image and run a Keras on Spark container https://github.com/jack1981/AaaSDemo
- 41. Run the NCF deep learning pipeline for User Item Propensity model https://github.com/jack1981/AaaSDemo
- 42. Q & A