Denodo Platform 7.0: Redefine Analytics with In-Memory Parallel Processing and Data Virtualization
0 likes401 views

The document discusses modern data architectures using a logical data lake approach with data virtualization. It describes how the Denodo platform provides big data integrations by allowing Hadoop to be used as a data source, cache, and processing engine. This is demonstrated through an example showing how Denodo's cost-based optimizer and integration with SQL-on-Hadoop processing engines like Impala can optimize query performance. The document concludes that this approach can surface all company data without replication, improve governance, and leverage existing Hadoop cluster processing power controlled by Denodo's optimizer.





















Denodo Platform 7.0: Redefine Analytics with In-Memory Parallel Processing and Data Virtualization
- 2. Redefine Analytics with In-Memory Parallel Processing and Data Virtualization Pablo Alvarez-Yañez Product Manager, Denodo
- 3. AgendaAgenda1. Modern Data Architectures 2. Denodo Platform – Big Data Integrations 3. Demo 4. Putting This All Together 5. Next Steps
- 4. The Modern Data Architecture
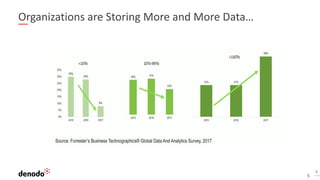
- 5. 5 Organizations are Storing More and More Data… 5
- 6. 6 … That Needs to be Stored and Processed
- 7. 7 Data Lake – The Concept Source: https://resources.zaloni.com/blog/what-is-a-data-lake
- 8. 8 Data Lake – The Challenges "However, getting value out of the data remains the responsibility of the business end user. (…) Without at least some semblance of information governance, the lake will end up being a collection of disconnected data pools or information silos all in one place." Data lakes therefore carry substantial risks. The most important is the inability to determine data quality or the lineage of findings by other analysts or users that have found value, previously, in using the same data in the lake. Another risk is security and access control. Data can be placed into the data lake with no oversight of the contents. Many data lakes are being used for data whose privacy and regulatory requirements are likely to represent risk exposure Source: https://www.forbes.com/sites/danwoods/2016/08/26/why-data-lakes-are-evil/Source: https://www.gartner.com/newsroom/id/2809117
- 9. 9 Data Lake – The Concept
- 10. 10 Logical Data Lake with Data Virtualization L O G I C A L D A T A L A K E
- 11. Denodo Platform and Big Data Integrations
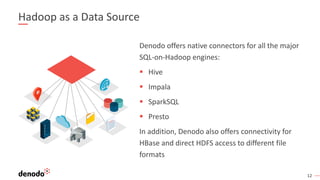
- 12. 1212 Hadoop as a Data Source Denodo offers native connectors for all the major SQL-on-Hadoop engines: ▪ Hive ▪ Impala ▪ SparkSQL ▪ Presto In addition, Denodo also offers connectivity for HBase and direct HDFS access to different file formats
- 13. 1313 Hadoop as Cache Denodo uses an external RDBMS of your choice to persist copies of the result sets to improve execution times • Since data is persisted in an RDBMS, Denodo can push down relational operations, like JOINS with other tables, to the database used for cache SQL-on-Hadoop systems can also be used as Denodo’s cache Cache load process based on direct load to HDFS: 1. Creation of the target table in Cache system 2. Generation of Parquet files (in chunks) with Snappy compression in the local machine 3. Upload in parallel of Parquet files to HDFS
- 14. 1414 Hadoop as Processing Engine Denodo optimizer provides native integration with MPP systems to provide one extra key capability: Query Acceleration Denodo can move, on demand, processing to the MPP during execution of a query • Parallel power for calculations in the virtual layer • Avoids slow processing in-disk when processing buffers don’t fit into Denodo’s memory (swapped data)
- 15. 1515 Combining Denodo’s Optimizer with a Hadoop MPP Denodo provides the most advanced optimizer in the market, with techniques focused on data virtualization scenarios with large data volumes In addition to traditional Cost Based Optimizations (CBO), Denodo’s optimizer applies innovative optimization strategies, designed specifically for virtualized scenarios, beyond traditional RDBMS optimizations. Combined with the tight integration with SQL-on-Hadoop MPP databases, it creates a very powerful combo
- 16. 1616 Example: Scenario Evolution of sales per ZIP code over the previous years. Scenario: ▪ Current data (last 12 months) in EDW ▪ Historical data offloaded to Hadoop cluster for cheaper storage ▪ Customer master data is used often, so it is cached in the Hadoop cluster Very large data volumes: ▪ Sales tables have hundreds of millions of rows join group by ZIP union Current Sales 100 million rows Historical Sales 300 million rows Customer 2 million rows (cached)
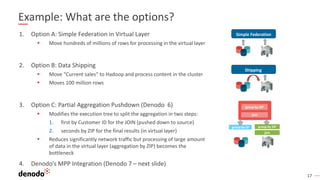
- 17. 1717 Example: What are the options? 1. Option A: Simple Federation in Virtual Layer ▪ Move hundreds of millions of rows for processing in the virtual layer 2. Option B: Data Shipping ▪ Move “Current sales” to Hadoop and process content in the cluster ▪ Moves 100 million rows 3. Option C: Partial Aggregation Pushdown (Denodo 6) ▪ Modifies the execution tree to split the aggregation in two steps: 1. first by Customer ID for the JOIN (pushed down to source) 2. seconds by ZIP for the final results (in virtual layer) ▪ Reduces significantly network traffic but processing of large amount of data in the virtual layer (aggregation by ZIP) becomes the bottleneck 4. Denodo’s MPP Integration (Denodo 7 – next slide) Simple Federation Shipping join group by ID group by ZIP group by ZIP join
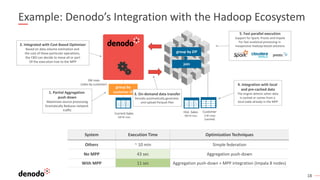
- 18. 18 Example: Denodo’s Integration with the Hadoop Ecosystem 2M rows (sales by customer) System Execution Time Optimization Techniques Others ~ 10 min Simple federation No MPP 43 sec Aggregation push-down With MPP 11 sec Aggregation push-down + MPP integration (Impala 8 nodes) Current Sales 100 M rows group by customer ID1. Partial Aggregation push down Maximizes source processing Dramatically Reduces network traffic 3. On-demand data transfer Denodo automatically generates and upload Parquet files 4. Integration with local and pre-cached data The engine detects when data Is cached or comes from a local table already in the MPP 2. Integrated with Cost Based Optimizer Based on data volume estimation and the cost of these particular operations, the CBO can decide to move all or part Of the execution tree to the MPP 5. Fast parallel execution Support for Spark, Presto and Impala For fast analytical processing in inexpensive Hadoop-based solutions Hist. Sales 300 M rows Customer 2 M rows (cached) join group by ZIP
- 19. Demo
- 20. Putting all the pieces together
- 21. 2121 Putting all the pieces together These three techniques (Hadoop as a data source, cache and processing engine) can be combined to successfully approach complex scenarios with big data volumes in an efficient way: ▪ Surfaces all the company data without the need to replicate all data to the Hadoop lake, in a business friendly manner ▪ Improves governance and metadata management to avoid “data swamps”: data lineage, catalog, access control, impact analysis for changes, etc. ▪ Allows for on-demand combination of real-time (from the original sources) with historical data (in the cluster) ▪ Leverages the processing power of the existing cluster controlled by Denodo’s optimizer
- 22. 2222 Architecture – Technical notes To benefit from this architecture, Denodo servers should run in edge nodes of the Hadoop cluster This will ensure: ▪ Faster uploads to HDFS ▪ Faster data retrieval from the MPP ▪ Better compatibility with the Hadoop configuration and versions of the libraries Denodo Cluster ▪ Multiple nodes behind a load balancer for HA ▪ Running on Hadoop Edge nodes Hadoop Cluster ▪ Processing and Storage nodes ▪ Same subnet as Denodo cluster
- 23. Q&AQ&A
- 24. 24 DOWNLOAD DENODO EXPRESS DENODO FOR AWS DENODO FOR AZURE Download Denodo Express Next Steps Access Denodo Platform in the cloud! 30 day free trial available!
- 25. Thank you! © Copyright Denodo Technologies. All rights reserved Unless otherwise specified, no part of this PDF file may be reproduced or utilized in any for or by any means, electronic or mechanical, including photocopying and microfilm, without prior the written authorization from Denodo Technologies. #FastDataStrategy