














![Ceph Test Configurations
‘Default’ (30OSD+JOURNAL SSD)
[osd]
osd journal size = 10000
osd pool default size = 3
osd pool default min size = 2
osd crush chooseleaf type = 1
8 Threads
[osd]
osd journal size = 10000
osd pool default size = 3
osd pool default min size = 2
osd crush chooseleaf type = 1
osd op threads = 8
filestore op threads = 8
journal max write entries = 50000
journal queue max ops = 50000
24 Threads
[osd]
osd journal size = 10000
osd pool default size = 3
osd pool default min size = 2
osd crush chooseleaf type = 1
osd op threads = 24
filestore op threads = 24
journal max write entries = 50000
journal queue max ops = 50000
36 Threads
[osd]
osd journal size = 10000
osd pool default size = 3
osd pool default min size = 2
osd crush chooseleaf type = 1
osd op threads = 36
filestore op threads = 36
journal max write entries = 50000
journal queue max ops = 50000
36 + fs queue
[osd]
osd journal size = 10000
osd pool default size = 3
osd pool default min size = 2
osd crush chooseleaf type = 1
osd op threads = 36
filestore op threads = 36
filestore queue max ops = 50000
filestore queue committing max ops = 50000
journal max write entries = 50000
journal queue max ops = 50000](https://image.slidesharecdn.com/gnocchiprofilingv2-160704231338/85/Gnocchi-Profiling-v2-17-320.jpg)











Gnocchi Profiling v2
- 1. Gnocchi Numbers (more) Benchmarking 2.1.x
- 2. Test Configuration - 4 physical hosts - CentOS 7.2.1511 - 24 physical cores (hyperthreaded), 256 GB memory - 25 - 1TB disks, 10K RPM - 1Gb network - PostgreSQL 9.2.15 (single node) - Shared with ceph and compute service Default everything, except 300 connections vs 100(default) - Ceph 10.2.2 (4 nodes, 1 monitoring, 3 OSD) - 30 OSDs (1 TB disk), Journals share SSD, 2 replica, 2048 placement groups - OSD nodes shared with (idle) compute service - Gnocchi Master (~ June 3rd, 2016)
- 3. Host Configuration - Host1 - OpenStack Controller Node (Ceilometer, Heat, Nova-stuff, Neutron, Cinder, Glance, Horizon) - Ceph Monitoring service - Gnocchi API - Host2 - OpenStack Compute Node - Ceph OSD node (10 OSDs) - Host3 - Ceph OSD node (10 OSDs) - Host4 - OpenStack Compute Node - Ceph OSD node (10 OSDs) - PostgreSQL
- 4. Testing Methodology - Start 3 metricd services - 24 workers each - POST 1000 generic resources spread across 20 workers, 20 metrics each. - POST Every 10 minutes - 1 minute granularity, 10 points/metric/request - 20 000 metrics, medium archive policy - 1 min for a day, 1 hr for a week, 1 day for a year, 8 aggregates each
- 5. Batch1 metricd details - POST time (50 posts) - avg=10.8s (-65.5%), stdev=0.79 - Injection time - ~ 144 seconds - Stats - Per metric injection - avg=0.462s, min=0.235s, max=1.693s, stdev=0.174 - Average IO time - ~66% of _add_measures() - Overhead - ~10.8% (~9.89% minus all IO once metric locked) - Comparison to 20OSD w/ shared journal - POST - 65.5% quicker - Injection time - 27% quicker
- 6. Batch2 metricd details - POST time (50 posts) - avg=30.6s, stdev=2.72 - Injection time - ~ 400 seconds - Stats - Per metric injection - avg=1.316s, min=0.286s, max=5.758s, stdev=0.844 - Average IO time - ~76.0% of _add_measures() - Overhead - ~9.23% (~6.78% minus all IO once metric locked) - Comparison to 20OSD w/ shared journal - POST - 70% quicker - Injection time - 28.4% quicker
- 7. Batch3 metricd details - POST time (50 posts) - avg=30.2s, stdev=2.87 - Injection time - ~ 408 seconds - Stats - Per metric injection - avg=1.33s, min=0.285s, max=5.647s, stdev=0.824 - Average IO time - ~74.9% of _add_measures() - Overhead - ~9.58% (~6.95% minus all IO once metric locked) - Comparison to 20OSD w/ shared journal - POST - 65.4% quicker - Injection time - 26% quicker
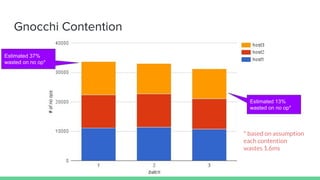
- 10. Gnocchi Contention Estimated 37% wasted on no op* Estimated 13% wasted on no op* * based on assumption each contention wastes 1.6ms
- 11. Ceph Profile
- 12. Ceph Profile - Read speed - avg = 6727 kB/s (+32%) - max = 28293 kB/s (+47%) - stdev = 4185 (+69%) - Write speed - avg = 1565 kB/s (+36%) - max = 8655 kB/s (+94%) - stdev = 1262 (+65%) - Operations - avg = 8349 op/s (+36%) - max = 31791 op/s (+62%) - stdev = 5289 (+77%) Difference compared to 20OSD, non-SSD deployment
- 13. Tuning Ceph
- 14. Hardware Configurations - Ceph 10.2.2 - 30 OSDs (1 TB disk), Journals share SSD, 2 replica, 2048 placement groups - OSD nodes shared with (idle) compute service - Network File System - 8 - 1TB 10K HDD, RAID0 - Separate host from metricd services
- 15. Ceph Hardware - Processing Rate
- 16. Ceph Hardware - Processing Rate
- 17. Ceph Test Configurations ‘Default’ (30OSD+JOURNAL SSD) [osd] osd journal size = 10000 osd pool default size = 3 osd pool default min size = 2 osd crush chooseleaf type = 1 8 Threads [osd] osd journal size = 10000 osd pool default size = 3 osd pool default min size = 2 osd crush chooseleaf type = 1 osd op threads = 8 filestore op threads = 8 journal max write entries = 50000 journal queue max ops = 50000 24 Threads [osd] osd journal size = 10000 osd pool default size = 3 osd pool default min size = 2 osd crush chooseleaf type = 1 osd op threads = 24 filestore op threads = 24 journal max write entries = 50000 journal queue max ops = 50000 36 Threads [osd] osd journal size = 10000 osd pool default size = 3 osd pool default min size = 2 osd crush chooseleaf type = 1 osd op threads = 36 filestore op threads = 36 journal max write entries = 50000 journal queue max ops = 50000 36 + fs queue [osd] osd journal size = 10000 osd pool default size = 3 osd pool default min size = 2 osd crush chooseleaf type = 1 osd op threads = 36 filestore op threads = 36 filestore queue max ops = 50000 filestore queue committing max ops = 50000 journal max write entries = 50000 journal queue max ops = 50000
- 18. Ceph Configurations - Metrics processed per 5s
- 19. Ceph Configurations - Processing Rate
- 20. Tuned vs Untuned - Comparing Batch3 (36 + fs queue) vs Batch3 (default) - POST time (50 posts) - avg=21.1s (-30.1%), stdev=0.904 (-68.5%) - Injection time - ~ 199 seconds (-51.2%) - Stats - Per metric injection - avg=0.596s(-55.2%) - stdev=0.477(-42.1%) - min=0.286s(+0%) - max=9.12s (+38%) - Overhead - ~15.2% (~14.1% minus all IO once metric locked) - Consistent write performance between batches!
- 21. Ceph Profile - Read speed - avg = 10978 kB/s (+63%) - max = 27104 kB/s (-4%) - stdev = 5230 (+25%) - Write speed - avg = 2521 kB/s (+61%) - max = 5304 kB/s (-39%) - stdev = 994(-21%) - Operations - avg = 13534 op/s (+62%) - max = 30398 op/s (-4%) - stdev = 5739(+9%) Difference compared to default 30OSD+SSD journal configuration using standard Ceph configurations
- 23. Optimisation Opportunities - Gnocchi has a lot of IO - By default, over 25 reads and 25 writes for every single metric - Serialising and deserialising each time - Degradation as number of points grows (up to object split size) - Needs to read in full object with related points, update, and write full object for each aggregate even if updating one point out of thousands.
- 24. Current Serialisation Simpler serialisation merged into master and backported to 2.1
- 25. Effects of IO
- 26. Serialisation Format Existing {‘values’:{<timestamp>: float, <timestamp>: float, ... <timestamp>: float}} - ~18B/point or ~10B/point (compressed) - Not appendable - Msgpack serialisation, super fast Proposed delimiter+float+delimiter+float+. ..+delimiter+float - 9B/point (or much if compressed) - Appendable - Delimiter can be used to describe subsequent bytes - Timestamp computed by offset - eg. Position 9 to 17 is data x seconds from start - Zero padding required if first point not start of split - Handles compression much better
- 27. Comparing Serialisation Formats Existing deserialisation needs to be sorted. It is more comparable if factored in.
- 28. Looking to 3.x - Testing larger datasets (a few thousand points/metric) - Benchmarking new proposed format - Study effects of alternative storage solutions - Try to add in support for intermediary storage in memory