Integrating Apache Phoenix with Distributed Query Engines
Download as PPTX, PDF3 likes485 views

The document discusses the integration of Apache Phoenix with distributed query engines like Presto and Spark, highlighting their functionalities and architecture. It details the use of connectors for managing data queries efficiently and addresses limitations and future improvements, such as pushdowns for complex operations and statistics integration. The document also emphasizes the shift towards resilient distributed datasets (RDDs) to optimize data processing and support iterative algorithms and interactive data mining.




















![Phoenix-Spark connector (Datasource V1)
case class PhoenixRelation(tableName: String, zkUrl: String...) extends
BaseRelation with PrunedFilteredScan {
override def buildScan(requiredColumns: Array[String], filters:
Array[Filter]): RDD[Row] = {new PhoenixRDD(..)
override def schema: StructType = {...
override def unhandledFilters(filters: Array[Filter]): Array[Filter] =
{....
}](https://image.slidesharecdn.com/tues220pmintegratingapachephoenixwithdistributedqueryenginesthomasdsilva-190603184718/85/Integrating-Apache-Phoenix-with-Distributed-Query-Engines-23-320.jpg)
![Phoenix-Spark connector (Datasource V1)
Uses NewHadoopRDD to read/write data from a phoenix table
val phoenixRDD = sc.newAPIHadoopRDD(phoenixConf,
classOf[PhoenixInputFormat[PhoenixRecordWritable]], // class of
MR input format
classOf[NullWritable], // class of key
classOf[PhoenixRecordWritable]) // class of value](https://image.slidesharecdn.com/tues220pmintegratingapachephoenixwithdistributedqueryenginesthomasdsilva-190603184718/85/Integrating-Apache-Phoenix-with-Distributed-Query-Engines-24-320.jpg)

![Datasource V2 (evolving)
public interface DataSourceReader {
StructType readSchema();
List<InputPartition<InternalRow>> planInputPartitions();
}
public interface SupportsPushDownFilters extends DataSourceReader {
Filter[] pushFilters(Filter[] filters);
Filter[] pushedFilters();
}
public interface SupportsPushDownRequiredColumns extends DataSourceReader{
void pruneColumns(StructType requiredSchema);
}](https://image.slidesharecdn.com/tues220pmintegratingapachephoenixwithdistributedqueryenginesthomasdsilva-190603184718/85/Integrating-Apache-Phoenix-with-Distributed-Query-Engines-26-320.jpg)


Integrating Apache Phoenix with Distributed Query Engines
- 1. Integrating Apache Phoenix with Distributed Query Engines Vincent Poon Thomas D’Silva
- 2. Outline ● Presto Connector ● Spark Connector ● Demo
- 3. What is Presto? ● Presto is an open source distributed SQL query engine for running interactive analytic queries on big datasets ○ latency sensitive use cases ■ Visualizations, dashboards, notebooks, BI tools ○ queries in seconds or minutes ● Developed at Facebook, contributed to open source (2013) ● ANSI SQL compliant ● AWS Athena, Google BigQuery
- 9. Phoenix MapReduce framework ● Useful for long running queries that read most/all of the data ● Steps: ○ Run query through planner to get QueryPlan ○ Setup parallel scans for QueryPlan ■ One scan per region (or guidepost with stats) ○ Extract HBase scans from final QueryPlan ○ Create one Mapper per scan, execute in YARN
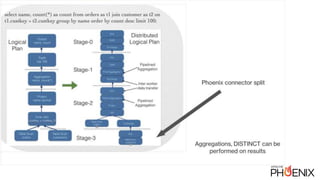
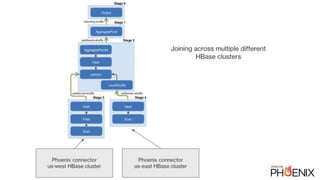
- 10. Phoenix connector for Presto ● Similar to Phoenix MapReduce: ● Steps: ○ Run query through planner, get parallel HBase scans ○ Create a Presto Split for each scan ■ reuses the Presto JDBC connector code ■ wrap each scan in a ResultSet ○ Splits executed by Presto Workers
- 15. Future work ● Integrate with new Presto work on pushdown of complex operations (aggregations, joins, etc) ○ Currently only predicates are pushed down to Phoenix ○ Phoenix can then pushdown further to HBase coprocessor ● Integrate Phoenix stats with Presto cost-based optimizer ○ Join reordering based on stats
- 16. Background Most current cluster programming models are based on acyclic data flow from stable storage to stable storage Map Map Map Reduce Reduce Input Output
- 17. Motivation Map Map Map Reduce Reduce Input Output Benefits of data flow: runtime can decide where to run tasks and can automatically recover from failures Most current cluster programming models are based on acyclic data flow from stable storage to stable storage
- 18. Motivation Acyclic data flow is inefficient for applications that repeatedly reuse a working set of data: »Iterative algorithms (machine learning, graphs) »Interactive data mining tools (R, Excel, Python) With current frameworks, apps reload data from stable storage on each query
- 19. Spark Goals Extend the MapReduce model to better support two common classes of analytics apps: »Iterative algorithms (machine learning, graphs) »Interactive data mining Enhance programmability: »Integrate into Scala programming language »Allow interactive use from Scala interpreter (slides from https://svn.apache.org/repos/asf/spark/talks/overview.pptx)
- 20. Solution: Resilient Distributed Datasets (RDDs) Allow apps to keep working sets in memory for efficient reuse Retain the attractive properties of MapReduce »Fault tolerance, data locality, scalability Support a wide range of applications
- 21. Programming Model Resilient distributed datasets (RDDs) »Immutable, partitioned collections of objects »Created through parallel transformations (map, filter, groupBy, join, …) on data in stable storage »Can be cached for efficient reuse Actions on RDDs »Count, reduce, collect, save, …
- 22. Phoenix-Spark connector (Datasource V1) ● Spark supports JDBC, but parallelizes queries only numeric columns ● Connector uses splits provided by Phoenix to read/write data ● Support column projection and simple filter push down
- 23. Phoenix-Spark connector (Datasource V1) case class PhoenixRelation(tableName: String, zkUrl: String...) extends BaseRelation with PrunedFilteredScan { override def buildScan(requiredColumns: Array[String], filters: Array[Filter]): RDD[Row] = {new PhoenixRDD(..) override def schema: StructType = {... override def unhandledFilters(filters: Array[Filter]): Array[Filter] = {.... }
- 24. Phoenix-Spark connector (Datasource V1) Uses NewHadoopRDD to read/write data from a phoenix table val phoenixRDD = sc.newAPIHadoopRDD(phoenixConf, classOf[PhoenixInputFormat[PhoenixRecordWritable]], // class of MR input format classOf[NullWritable], // class of key classOf[PhoenixRecordWritable]) // class of value
- 25. Datasource V1 ● No support for pushing down limit or aggregates ● No support for statistics ● Depends on upper level RDD API
- 26. Datasource V2 (evolving) public interface DataSourceReader { StructType readSchema(); List<InputPartition<InternalRow>> planInputPartitions(); } public interface SupportsPushDownFilters extends DataSourceReader { Filter[] pushFilters(Filter[] filters); Filter[] pushedFilters(); } public interface SupportsPushDownRequiredColumns extends DataSourceReader{ void pruneColumns(StructType requiredSchema); }
- 27. Future Work SPARK-22386 ● Limit Pushdown ● Aggregate Pushdown ● Support clustering for writes
- 28. Demo