Presto: SQL-on-anything
Download as PPTX, PDF3 likes5,432 views

Presto is an open source distributed SQL query engine that allows querying of data across different data sources. It was originally developed by Facebook and is now used by many companies. Presto uses connectors to query various data sources like HDFS, S3, Cassandra, MySQL, etc. through a single SQL interface. Companies like Facebook and Teradata use Presto in production environments to query large datasets across different data platforms.






























Presto: SQL-on-anything
- 1. Presto: SQL-on-Anything DataWorks Summit, San Jose 2017 Martin Traverso, Facebook Matt Fuller, Teradata
- 2. Let’s Make Some Noise! @DataWorksSummit #DWS17 #prestodb #facebook #teradata
- 3. What is Presto? • Open source distributed SQL query engine • Originally developed by Facebook • ANSI SQL compliant • Like Hive, it’s not a database • Key Differentiators • Performance & Scale • Cross platform query capability, not only SQL on Hadoop • Supports federated queries • Used in production at many well known web-scale companies • Distributed under the Apache License, hosted on GitHub
- 5. Multiple clusters (1000s of nodes total) 300PB in HDFS, MySQL, and Raptor 1000s users, 10-100s concurrent queries Presto in Action
- 6. 250+ nodes on AWS 40+ PB stored in S3 (Parquet) Over 650 users with 6K+ queries daily Presto in Action
- 7. 300+ nodes (2 dedicated clusters) 100K+ & 20K+ queries daily Presto in Action
- 8. 200+ nodes on-premises Parquet nested data Presto in Action
- 9. 120+ nodes in AWS 2PB is S3 and 200+ users supported by Teradata Presto in Action
- 10. Data Stream API Worker Data Stream API Worker Coordinator Metadata API Parser/ analyzer Planner Scheduler Worker Client Data Location API PluggablePresto Architecture
- 11. Presto is not a Database! • Presto is a distributed query execution engine • Storage Independent • Pluggable extensions • Connectors • Functions • Types • System access controllers • Resource group configuration managers • Event listeners • ... • Built-in core functionalities • parser, execution, types, sql functions, monitoring
- 12. Parser/ analyzer Planner Worker Metadata API Hive Cassandra Kafka MySQL … Scheduler Coordinator Presto Extensibility - Connector Data Location API Hive Cassandra Kafka MySQL … Data Stream API Hive Cassandra Kafka MySQL …
- 14. Plugins
- 16. Plugin Interface
- 17. Connector Configuration • Catalog namespace owned by connector Catalog Name
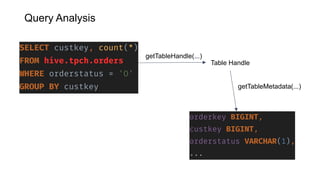
- 20. Query Planning
- 21. getSplits(...) Iterator<Split> Query Execution Split • Handle to logical chunk of a table • Attributes • Remote access? • Location
- 22. Coordinator Worker Worker Worker + splits Query Execution + splits + splits
- 24. Presto Connectors @Facebook • Hive connector • Warehouse (ad-hoc / batch) • Raptor connector • Dashboards • Reporting backend for A/B testing framework • Sharded MySQL connector • Reporting backend for user-facing products • Other custom connectors for specialized data stores
- 25. Presto Connectors @Teradata Customers • Teradata QueryGrid + Presto • Teradata, Hadoop, S3, Cassandra, RESTful • Customer Use Cases • Recent sales data in Teradata needs to be joined with archived sales data that resided in Hadoop • Hadoop user using Presto needs to access pre-computed financial record in Teradata • Existing supplier data that is in Teradata is joined with archived product data that resides in Amazon S3
- 26. AMP AMP AMP AMP Q G E x c h a n g e Q G E x c h a n g e PE Coordinator Worker Thread Worker Thread Worker Thread Worker Thread Init & metadata exchange Bi-directional fully parallel data exchange TERADATA PRESTO • Key features: • Low latency • High performance • Concurrency • Pushdown • Data conversion • Compression • Efficient CPU usage Teradata QueryGrid (powered by Presto)
- 27. Teradata QueryGrid SQL Examples Teradata query joining data from Hadoop via Presto: SELECT * FROM websales_current UNION ALL SELECT * FROM websales_archive@presto; Presto query joining data in Teradata: SELECT * FROM td.sales.websales_current UNION ALL SELECT * FROM hive.sales.websales_archive;
- 28. Conclusions • Presto Connector API is expressive • 3rd Party data source is 1st class citizen • Single ANSI SQL to rule them all • Use BI tools on data which is not BI friendly • Rapid data integration
- 29. Write your own connector! • Issue SQL to GitHub! • https://developer.github.com/v3/ • SELECT count(*) FROM prestodb.presto.stargazers; • Connector Example • https://github.com/prestodb/presto/tree/master/presto-example-http • Documentation • https://prestodb.io/docs/current/develop.html
- 30. Additional Resources • Website • www.prestodb.io • Presto Users Groups • www.groups.google.com/group/presto-users • GitHub: • www.github.com/prestodb/presto • www.github.com/Teradata/presto (Teradata’s development “fork”)