Scaling self service on Hadoop
1 like1,254 views

Scaling self service on Hadoop involves moving from a traditional ETL model with limited self-service to a more agile approach using tools like Hadoop, Hive, and QlikView. This allows extracting and transforming data in Hadoop and loading it into QlikView for self-service reporting and analysis. Over time, the environment has expanded to include real-time processing using technologies like Kafka and Storm. Current challenges include improving security, data quality, code reuse and integration with other BI tools to further enable self-service analytics across the organization.





























































Scaling self service on Hadoop
- 1. Scaling self service on Hadoop Sander Kieft @skieft
- 2. Photo credits: niznoz - https://www.flickr.com/photos/niznoz/3116766661/
- 3. About me @skieft Manager Core Services at Sanoma Responsible for all common services, including the Big Data platform Work: – Centralized services – Data platform – Search Like: – Work – Water(sports) – Whiskey – Tinkering: Arduino, Raspberry PI, soldering stuff 27April20153
- 4. Sanoma, Publishing and Learning company 2+100 2 Finnish newspapers Over 100 magazines 27April2015 Presentationname4 5 TV channels in Finland and The Netherlands 200+ Websites 100 Mobile applications on various mobile platforms
- 5. Past
- 6. History < 2008 2009 2010 2011 2012 2013 2014 2015
- 7. Self service Photo credits: misternaxal - http://www.flickr.com/photos/misternaxal/2888791930/
- 8. Self service
- 9. Self service levels Personal Departmental Corporate Full self service Support with publishing dashboards and data loading Full service and support on dashboard Information is created by end users with little or no oversight. Users are empowered to integrate different data sources and make their own calculations. Information has been created by end users and is worth sharing, but has not been validated. Information that has gone through a rigorous validation process can be disseminated as official data. 27April20159 Information Workers Information Consumers Full Agility Centralized Development Excel Static reportsFocus
- 10. Self service position – 2010 starting point Source Extraction Trans- formation Modeling Load Report / Dashboar d Insight 27April201510 Data team Analysts
- 11. History < 2008 2009 2010 2011 2012 2013 2014 2015 4/27/2015 © SanomaMedia11
- 12. Glue: ETL EXTRACT TRANSFORM LOAD 27April201512
- 17. #fail
- 18. Hadoop and Qlikview proofed to be really valuable tools Traditional ETL tools don’t scale for Big Data sources Big Data projects are not BI projects Doing full end-to-end integrations and dashboard development doesn’t scale Qlikview was not good enough as the front-end to the cluster Hadoop requires developers not BI consultants Learnings
- 19. History < 2008 2009 2010 2011 2012 2013 2014 2015
- 21. Russell Jurney Agile Data 27.4.2015 © SanomaMedia Presentationname/Author21
- 22. Self service position – Agile Data Source Extraction Trans- formation Modeling Load Report / Dashboar d Insight 27April201522
- 23. New glue Photo credits: Sheng Hunglin - http://www.flickr.com/photos/shenghunglin/304959443/
- 24. ETL Tool features Processing Scheduling Data quality Data lineage Versioning Annotating 27April201524
- 25. 27April2015 Presentationname25 Photo credits: atomicbartbeans - http://www.flickr.com/photos/atomicbartbeans/71575328/
- 26. 27.4.2015 © SanomaMedia Presentationname/Author26
- 27. 27.4.2015 © SanomaMedia Presentationname/Author27
- 28. Processing - Jython No JVM startup overhead for Hadoop API usage Relatively concise syntax (Python) Mix Python standard library with any Java libs 27April2015 Presentationname28
- 29. Scheduling - Jenkins Flexible scheduling with dependencies Saves output E-mails on errors Scales to multiple nodes REST API Status monitor Integrates with version control 27April2015 Presentationname29
- 30. ETL Tool features Processing – Bash & Jython Scheduling – Jenkins Data quality Data lineage Versioning – Mecurial (hg) Annotating – Commenting the code 27April2015 Presentationname30
- 31. Processes Photo credits: Paul McGreevy - http://www.flickr.com/photos/48379763@N03/6271909867/
- 32. Independent jobs Source (external) HDFS upload + move in place Staging (HDFS) MapReduce + HDFS move Hive-staging (HDFS) Hive map external table + SELECT INTO Hive 27April2015 Presentationname32
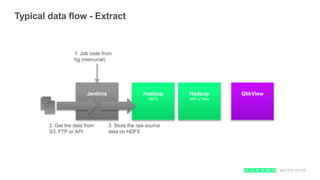
- 33. Typical data flow - Extract Jenkins QlikViewHadoop HDFS Hadoop M/R or Hive 1. Job code from hg (mercurial) 2. Get the data from S3, FTP or API 3. Store the raw source data on HDFS
- 34. Typical data flow - Transform Jenkins QlikViewHadoop HDFS Hadoop M/R or Hive 1. Job code from hg (mercurial) 2. Execute M/R or Hive Query 3. Transform the data to the intermediate structure
- 35. Typical data flow - Load Jenkins QlikViewHadoop HDFS Hadoop M/R or Hive 1. Job code from hg (mercurial) 2. Execute Hive Query 3. Load data to QlikView
- 36. Out of order jobs At any point, you don’t really know what ‘made it’ to Hive Will happen anyway, because some days the data delivery is going to be three hours late Or you get half in the morning and the other half later in the day It really depends on what you do with the data This is where metrics + fixable data store help... 27April2015 Presentationname36
- 37. Fixable data store Using Hive partitions Jobs that move data from staging create partitions When new data / insight about the data arrives, drop the partition and re-insert Be careful to reset any metrics in this case Basically: instead of trying to make everything transactional, repair afterwards Use metrics to determine whether data is fit for purpose 27April2015 Presentationname37
- 38. Photo credits: DL76 - http://www.flickr.com/photos/dl76/3643359247/
- 39. Enabling self service 27.4.2015 © SanomaMedia39 ?? Netherlands Finland Staging Raw Data (Native format) HDFS Normalized Data structure HIVE Reusable stem data • Weather • Int. event calanders • Int. AdWord Prices • Exchange rates Source systems FI NL ? Extract Transform Data Scientists Business Analists
- 40. Enabling self service 27.4.2015 © SanomaMedia40 ?? Netherlands Finland Staging Raw Data (Native format) HDFS Normalized Data structure HIVE Reusable stem data • Weather • Int. event calanders • Int. AdWord Prices • Exchange rates Source systems FI NL ? Extract Transform Data Scientists Business Analists
- 41. HUE & Hive
- 42. QlikView
- 43. R Studio Server
- 44. Jenkins
- 45. Architecture
- 46. High Level Architecture 46 sources Jenkins & Jython ETL Back Office Analytics Meta Data AdServing (incl. mobile, video,cpc,yield, etc.) Market Content QlikView Dashboard/ Reporting Hive & HUE Subscription Hadoop Scheduled loads AdHoc Queries Scheduled exports R Studio Advanced Analytics
- 47. Current State - Real time Extending own collecting infrastructure Using this to drive recommendations, real time dashboarding, user segementation and targeting in real time Using Kafka and Storm 27April2015 Presentationname47
- 48. High Level Architecture 48 Jenkins & Jython ETL Meta Data QlikView Dashboard/ Reporting Hive & HUE (Real time) Collecting CLOE Hadoop Scheduled loads AdHoc Queries Scheduled exports Recommendations / Learn to Rank R Studio Advanced Analytics Storm Stream processing Recommendatio ns & online learningFlume / Kafka Back Office Analytics AdServing (incl. mobile, video,cpc,yield, etc.) Market Content sources Subscription
- 49. DC1 DC2 Sanoma Media The Netherlands Infra Production VMs Managed HostingColocation Big Data platform Dev., test and acceptance VMs Production VMs • NO SLA (yet) • Limited support BD9-5 • No Full system backups • Managed by us with systems department help • 99,98% availability • 24/7 support • Multi DC • Full system backups • High performance EMC SAN storage • Managed by dedicated systems department
- 50. DC1 DC2 Sanoma Media The Netherlands Infra Production VMs Managed HostingColocation Big Data platform Dev., test and acceptance VMs Production VMs • NO SLA (yet) • Limited support BD9-5 • No Full system backups • Managed by us with systems department help • 99,98% availability • 24/7 support • Multi DC • Full system backups • High performance EMC SAN storage • Managed by dedicated systems department Processing Storage Batch Collecting Real time Recommendations Queue data for 3 days Run on stale data for 3 days
- 51. Present
- 52. Self service position – Present Source Extraction Trans- formation Modeling Load Report / Dashboar d Insight 27April2015 Presentationname52
- 53. Present < 2008 2009 2010 2011 2012 2013 2014 2015 YARN
- 54. Moving to YARN (CDH 4.3 -> 5.1) 27April2015 "Blastingfrankfurt"byHeptagon-Ownwork.LicensedunderCCBY-SA3.0viaWikimediaCommons-http://commons.wikimedia.org/wiki/File:Blasting_frankfurt.jpg#/media/File:Blasting_frankfurt.jpg54 Functional testing wasn’t enough Takes time to tune the parameters Defaults are NOT good enough Cluster dead locks Grouped nodes with similar Hardware requirements into Node groups CDH 4 to 5 specific Hive CLI -> Beeline Hive Locking
- 55. Combining various data sources (web analytics + advertising + user profiles) A/B testing + deeper analyses Ad spend ROI optimization & attribution Ad auction price optimization Ad retargeting Item and user based recommendations Search optimizations – Online Learn to Rank – Search suggestions Current state – Use case 27 April2015 Presentationname55
- 56. Current state - Usage Main use case for reporting and analytics, increasing data science workloads Sanoma standard data platform, used in all Sanoma countries > 250 daily dashboard users 40 daily users: analysts & developers 43 source systems, with 125 different sources 400 tables in hive 27April2015 Presentationname56
- 57. Current state – Tech and team Platform Team: – 1 product owner – 3 developers Close collaborators: – ~10 data scientists – 1 Qlikview application manager – ½ (system) architect Platform: – 50-60 nodes – > 600TB storage – ~3000 jobs/day Typical nodes – 1-2 CPU 4-12 cores – 2 system disks (RAID 1) – 4 data disks (2TB, 3TB or 4TB) – 24-32GB RAM 27April2015 Presentationname57
- 59. 1. Security 2. Increase SLA’s 3. Integration with other BI environments 4. Improve Self service 5. Data Quality 6. Code reuse Challenges 27 April2015 Presentationname59
- 60. Future
- 61. Better integration batch and real time (unified code base) Improve the availability and SLA’s of the platform Optimizing Job scheduling (Resource Pools) Automated query/job optimization tips for analysts Fix Jenkins, is single point of failure Moving some NLP (Natural Language Processing) and Image recognition workload to hadoop 27April2015 Presentationname61 What’s next
Editor's Notes
- #3: Poultery
- #7: Mainly webanalytics Forester 1 dev + 1 bi
- #10: Business Intelligence Self Service Sweet Spot
- #26: ETL Pentaho SAS DI Studio Informatica Oozie Other
- #55: - cluster deadlocks can appear in moments of high utilization: low reducer slowstart threshold can result in a situation of many jobs with all reducers already allocated, taking up the slots for the remaining mappers which still need to finish ; apparently the Fair scheduler is not smart enough to detect this => all jobs are hanging (deadlock) solution: increase reducer slowstart threshold (mapreduce.job.reduce.slowstart.completedmaps) to 0.99