



































































![Inference – Spark Code
import pandas as pd
from keras.models import load_model, Sequential
from pyspark.sql.types import Row
def keras_spark_predict(model_path, weights_path, partition):
# load model
model = Sequential.from_config(model_path.value)
model.set_weights(weights_path.value)
# Create a list containing features.
featurs_list = map(lambda x: [x[:]], partition)
featurs_df = pd.DataFrame(featurs_list)
# predict with keras model
predictions = model.predict_on_batch(featurs_df)
predictions_return = map(lambda prediction: Row(prediction=prediction[0].item()), predictions)
return iter(predictions_return)
rdd = rdd.mapPartitions(lambda partition: keras_spark_predict(model_path, weights_path, partition))
https://github.com/liorsidi/GPU_deep_demo](https://image.slidesharecdn.com/gpudeep-190518140310/85/GPU-and-Deep-learning-best-practices-73-320.jpg)








![Back to the Demo
#https://stackoverflow.com/questions/43137288/how-to-determine-needed-memory-of-keras-model
def get_model_memory_usage(batch_size, model):
import numpy as np
from keras import backend as K
shapes_mem_count = 0
for l in model.layers:
single_layer_mem = 1
for s in l.output_shape:
if s is None:
continue
single_layer_mem *= s
shapes_mem_count += single_layer_mem
trainable_count = np.sum([K.count_params(p) for p in set(model.trainable_weights)])
non_trainable_count = np.sum([K.count_params(p) for p in set(model.non_trainable_weights)])
number_size = 4.0
if K.floatx() == 'float16':
number_size = 2.0
if K.floatx() == 'float64':
number_size = 8.0
total_memory = number_size*(batch_size*shapes_mem_count + trainable_count + non_trainable_count)
gbytes = np.round(total_memory / (1024.0 ** 3), 3)
return gbytes
https://github.com/liorsidi/GPU_deep_demo](https://image.slidesharecdn.com/gpudeep-190518140310/85/GPU-and-Deep-learning-best-practices-82-320.jpg)



GPU and Deep learning best practices
- 1. GPU + Deep learning Basics & best practices Lior Sidi DMBI Datahack – May 2019
- 2. About Me Data scientist & More
- 3. Agenda • Deep learning basics • GPU Basics • CUDA • Multi-GPU • GPU Configurations • IDE Configuration • Spark for inference • GPU Demo
- 4. Slides are based on.. • My experience • Machine learning course - Prof Lior Rokach • Stanford CS231 • NVIDIA.com • Tensorflow.org
- 6. Error-Back-Propagation, Baharvand, Ahmadi, Rahaie 6 Recap • Training Starts through the input layer: • The same happens for y2 and y3.
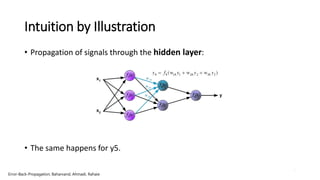
- 7. 7 Intuition by Illustration • Propagation of signals through the hidden layer: • The same happens for y5. Error-Back-Propagation, Baharvand, Ahmadi, Rahaie
- 8. 8 Intuition by Illustration • Propagation of signals through the output layer: Error-Back-Propagation, Baharvand, Ahmadi, Rahaie
- 9. 9 Intuition by Illustration • Error signal of output layer neuron: Error-Back-Propagation, Baharvand, Ahmadi, Rahaie
- 10. 10 Intuition by Illustration • propagate error signal back to all neurons. Error-Back-Propagation, Baharvand, Ahmadi, Rahaie
- 11. 11 Intuition by Illustration • If propagated errors came from few neurons, they are added: • The same happens for neuron-2 and neuron-3. Error-Back-Propagation, Baharvand, Ahmadi, Rahaie
- 12. 12 Intuition by Illustration • Weight updating starts: • The same happens for all neurons. Error-Back-Propagation, Baharvand, Ahmadi, Rahaie
- 13. Tensorboard https://www.tensorflow.org/guide/graphs
- 14. Model Parameters Dataset Sample Dataset Dataset Dataset Dataset sample Training MachineSample Dataset How can we make the training Faster? Training Flow
- 15. Model Parameters Dataset Sample Dataset Dataset Dataset Dataset sample Batch Training MachineDataset Dataset sample Dataset How can we make the training Faster? Compute the gradients on batch of samples Training Flow But How?
- 17. GPU basics
- 18. This image is licensed under CC-BY 2.0 Spot the CPU! (central processing unit) http://cs231n.stanford.edu/
- 19. Spot the GPUs! (graphics processing unit) This image is in the public domain http://cs231n.stanford.edu/
- 20. CPU / GPU Communication Model is here Data is here http://cs231n.stanford.edu/
- 21. CPU / GPU Communication Model is here Data is here If you aren’t careful, training can bottleneck on reading data and transferring to GPU! Solutions: - Read all data into RAM - Use SSD instead of HDD - Use multiple CPU threads to prefetch data http://cs231n.stanford.edu/
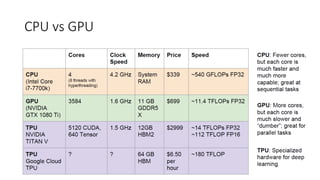
- 22. CPU vs GPU
- 23. CPU vs GPU Cores Few very complex Hundreds simple instructions Different Same Management Operation system Hardware Operations Serial parallel
- 24. CPU vs GPU Cores Few very complex Hundreds simple instructions Different Same Management Operation system Hardware Operations Serial parallel High throughput (number of task per unit time) Low Latency (time to do Task)
- 25. CPU vs GPU *A teraflop refers to the capability of a processor to calculate one trillion floating-point operations per second http://cs231n.stanford.edu/
- 26. CPU vs GPU
- 29. DATA Center VS AI LAB http://christopher5106.github.io/big/data/2015/07/31/deep-learning-machine-gpu-accelerated-computing-versus-cluster.html
- 31. Other cool DL hardware (we wont cover) FPGA - Field Programmable Gate Array Optimized for inference power efficiency flexible hardware architecture functional safety https://www.aldec.com/en/company/blog/167--fpgas-vs-gpus-for-machine-learning-applications-which-one-is-better
- 32. CUDA
- 33. CUDA • CUDA is a parallel computing platform and application programming interface (API) model created by Nvidia • software layer that gives direct access to the GPU
- 34. CUDA – processing flow
- 35. CUDA Deep Neural Network • a GPU-accelerated library for deep neural networks. • Provides highly tuned implementations for standard routines such as forward and backward convolution, pooling, normalization, and activation layers.
- 36. CPU vs GPU in practice (CPU performance not well-optimized, a little unfair) 66x 67x 71x 64x 76x Data from https://github.com/jcjohnson/cnn-benchmarks
- 37. CPU vs GPU in practice cuDNN much faster than “unoptimized” CUDA 2.8x 3.0x 3.1x 3.4x 2.8x Data from https://github.com/jcjohnson/cnn-benchmarks
- 38. Multi-GPU
- 39. TheNeed for DistributedTraining • Largerand Deeper models arebeingproposed; AlexNetto ResNetto NMT – DNNsrequire a lot of memory – Larger models cannotfita GPU’s memory • Single GPU training became abottleneck • As mentionedearlier,communityhas alreadymoved to multi-GPUtraining • Multi-GPU in one node is good but thereis alimitto Scale-up(8 GPUs) • Multi-node (Distributed or Parallel) Training isnecessary!!
- 40. Comparing complexity... An Analysis of Deep Neural Network Models for Practical Applications, 2017. 8/6/2017: Facebook managed to reduce the training time of a ResNet-50 deep learning model on ImageNet from 29 hours to one hour Instead of using batches of 256 images with eight GPUs they use batch sizes of 8,192 images distributed across 256 GPUs. Figures copyright Alfredo Canziani, Adam Paszke, Eugenio Culurciello, 2017.
- 41. Parallelism Types model parallelism different machines in the distributed system are responsible for the computations in different parts of a single network. for example, each layer in the neural network may be assigned to a different machine.
- 42. Parallelism Types model parallelism different machines in the distributed system are responsible for the computations in different parts of a single network. for example, each layer in the neural network may be assigned to a different machine. data parallelism different machines have a complete copy of the model; each machine simply gets a different portion of the data, and results from each are somehow combined
- 43. Hybrid Model
- 44. Combinationof ParallelizationStrategies HotInterconnects‘17NetworkBasedComputingLaboratory 44 Courtesy: http://on-demand.gputechconf.com/gtc/2017/presentation/s7724-minjie-wong-tofu-parallelizing-deep-learning.pdf
- 45. Data Parallelism • Data parallel approaches to distributed training keep a copy of the entire model on each worker machine, processing different subsets of the training data set on each.
- 46. Data Parallelism • Data parallel approaches to distributed training keep a copy of the entire model on each worker machine, processing different subsets of the training data set on each. • Data parallel training approaches all require some method of combining results and synchronizing the model parameters between each worker • Approaches: • Parameter averaging vs. update (gradient)-based approaches • Synchronous vs. asynchronous methods • Centralized vs. distributed synchronization
- 47. Parameter Averaging • Parameter averaging is the conceptually simplest approach to data parallelism. With parameter averaging, training proceeds as follows: 1. Initialize the network parameters randomly based on the model configuration 2. Distribute a copy of the current parameters to each worker 3. Train each worker on a subset of the data 4. Set the global parameters to the average the parameters from each worker 5. While there is more data to process, go to step 2
- 49. Multi GPU - Data Parallelism on Keras! https://keras.io/utils/#multi_gpu_model
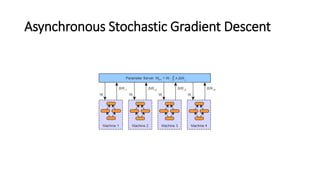
- 50. Asynchronous Stochastic Gradient Descent • An ‘update based’ data parallelism. • The primary difference between the two is that instead of transferring parameters from the workers to the parameter server, we will transfer the updates (i.e., gradients post learning rate and momentum, etc.) instead.
- 51. Asynchronous Stochastic Gradient Descent
- 52. When to Use Distributed Deep Learning?
- 54. Common GPU stack for Data science Pycharm IDE High level API Driver Hardware Platform / backend Library
- 55. Challenges • Linux • SUDO • Many packages • Env path • GPU has strong CPU
- 56. GPU configuration 1. Tensorflow GPU • pip install tensorflow-gpu https://www.tensorflow.org/install/gpu
- 57. GPU configuration 1. Tensorflow GPU • pip install tensorflow-gpu 2. Software requirements - Install CUDA with apt • NVIDIA® GPU drivers —CUDA 10.0 requires 410.x or higher. • CUDA® Toolkit —TensorFlow supports CUDA 10.0 (TensorFlow >= 1.13.0) • CUPTI ships with the CUDA Toolkit. • cuDNN SDK (>= 7.4.1) https://www.tensorflow.org/install/gpu
- 58. GPU configuration # Add NVIDIA package repositories # Add HTTPS support for apt-key sudo apt-get install gnupg-curl wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_10.0.130-1_amd64.deb sudo dpkg -i cuda-repo-ubuntu1604_10.0.130-1_amd64.deb sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pub sudo apt-get update wget http://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1604/x86_64/nvidia-machine-learning-repo-ubuntu1604_1.0.0-1_amd64.deb sudo apt install ./nvidia-machine-learning-repo-ubuntu1604_1.0.0-1_amd64.deb sudo apt-get update # Install NVIDIA Driver # Issue with driver install requires creating /usr/lib/nvidia sudo mkdir /usr/lib/nvidia sudo apt-get install --no-install-recommends nvidia-410 # Reboot. Check that GPUs are visible using the command: nvidia-smi # Install development and runtime libraries (~4GB) sudo apt-get install --no-install-recommends cuda-10-0 libcudnn7=7.4.1.5-1+cuda10.0 libcudnn7-dev=7.4.1.5-1+cuda10.0 # Install TensorRT. Requires that libcudnn7 is installed above. sudo apt-get update && sudo apt-get install nvinfer-runtime-trt-repo-ubuntu1604-5.0.2-ga-cuda10.0 && sudo apt-get update && sudo apt-get install -y --no-install-recommends libnvinfer-dev=5.0.2-1+cuda10.0 https://www.tensorflow.org/install/gpu
- 59. NVIDIA System Management Interface • The NVIDIA System Management Interface (nvidia-smi) is a command line utility, based on top of the NVIDIA Management Library (NVML), intended to aid in the management and monitoring of NVIDIA GPU devices. • This utility allows administrators to query GPU device state and with the appropriate privileges, permits administrators to modify GPU device state. It is targeted at the TeslaTM, GRIDTM, QuadroTM and Titan X product, though limited support is also available on other NVIDIA GPUs. https://developer.nvidia.com/nvidia-system-management-interface
- 60. NVIDIA System Management Interface watch --interval 1 nvidia-smi MobaXterm
- 61. Code Validation import tensorflow as tf print(tf.test.is_gpu_available(cuda_only=False,min_cuda_compute_capability=None)) from tensorflow.python.client import device_lib local_device_protos = device_lib.list_local_devices() print local_device_protos https://github.com/liorsidi/GPU_deep_demo
- 62. Code Validation import tensorflow as tf print(tf.test.is_gpu_available(cuda_only=False,min_cuda_compute_capability=None)) from tensorflow.python.client import device_lib local_device_protos = device_lib.list_local_devices() print local_device_protos https://github.com/liorsidi/GPU_deep_demo
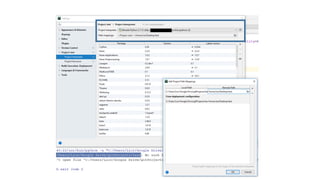
- 66. 2. remote interpreter configuration
- 67. 2. remote interpreter configuration
- 68. 3. remote interpreter folders Now wait
- 70. Tesnorflow on spark For inference
- 72. Inference - Spark 1. Install tensorflow & Keras on each node 2. Train a model on GPU 3. Save model as H5 file 4. Define batch size based on executor memory size & network size 5. Load the saved model on each node in the cluster 6. Run Code 1. Base on RDD 2. Use map partition to call executors code: 1. Load model 2. Predict_on_batch
- 73. Inference – Spark Code import pandas as pd from keras.models import load_model, Sequential from pyspark.sql.types import Row def keras_spark_predict(model_path, weights_path, partition): # load model model = Sequential.from_config(model_path.value) model.set_weights(weights_path.value) # Create a list containing features. featurs_list = map(lambda x: [x[:]], partition) featurs_df = pd.DataFrame(featurs_list) # predict with keras model predictions = model.predict_on_batch(featurs_df) predictions_return = map(lambda prediction: Row(prediction=prediction[0].item()), predictions) return iter(predictions_return) rdd = rdd.mapPartitions(lambda partition: keras_spark_predict(model_path, weights_path, partition)) https://github.com/liorsidi/GPU_deep_demo
- 74. Keep in mind other newer approaches • Spark • sparkflow • TensorFlowOnSpark • spark-deep-learning
- 75. GPU DEMO
- 81. Batch sizing • Batch size • Inference = Network parameters • Fully connected layers = #outputs x #inputs (weights) + #output (Bias) • In keras: • Summary • trainable_weights • non_trainable_weights • (+ Data generators) https://towardsdatascience.com/understanding-and-calculating-the-number-of-parameters-in-convolution-neural- networks-cnns-fc88790d530d
- 82. Back to the Demo #https://stackoverflow.com/questions/43137288/how-to-determine-needed-memory-of-keras-model def get_model_memory_usage(batch_size, model): import numpy as np from keras import backend as K shapes_mem_count = 0 for l in model.layers: single_layer_mem = 1 for s in l.output_shape: if s is None: continue single_layer_mem *= s shapes_mem_count += single_layer_mem trainable_count = np.sum([K.count_params(p) for p in set(model.trainable_weights)]) non_trainable_count = np.sum([K.count_params(p) for p in set(model.non_trainable_weights)]) number_size = 4.0 if K.floatx() == 'float16': number_size = 2.0 if K.floatx() == 'float64': number_size = 8.0 total_memory = number_size*(batch_size*shapes_mem_count + trainable_count + non_trainable_count) gbytes = np.round(total_memory / (1024.0 ** 3), 3) return gbytes https://github.com/liorsidi/GPU_deep_demo
- 83. To summarize • GPU are Awesome • Mind the batch size • Monitor your GPU (validate for every tf software update) • Work with Pycharm – remote interpreter • Separate between training and inference • Consider using free cloud tier • Fast.ai
- 84. Thank you & Good luck!
- 85. Tips for winning data hackathons • Separate roles: • Domain expert – explore the data, define features, read papers, metrics • Data engineer – preprocess data, extract feature, evaluation pipeline • Data scientist – algorithm development, evaluation, hyper tuning • Evaluation – avoid overfitting - someone is trying to trick you • Be consistent with your plan and feature exploration • Limited data • Augmentation • Extreme regularizations • Creativity • Think out of the box • Use state of the art tools • Save time and rest