





















![Reference
[1]. Mohammed ali al-garadi, Mohammad rashid hussain , Nawsher khan , Ghulam murtaza,
Henry friday nweke, Ihsan ali , Ghulam mujtaba, Haruna chiroma , Hasan ali khattak , and
Abdullah gani .“Predicting Cyberbullying on Social Media in the Big Data Era Using Machine
Learning Algorithms: Review of Literature and Open Challenges. vol.7, pp. 70701 - 70718, 22
May 2019,doi.10.1109/ACCESS.2019.2918354.
[2]. Waleed Mugahed Al-Rahmi ; Noraffandy Yahaya ; Mahdi M. Alamri,” A Model of Factors
Affecting Cyber Bullying Behaviors Among University Students. vol. 7, pp. 153417– 153431,
October. 2019,doi. 10.1109/ACCESS.2018.2881292.
[3].Norah Basheer Alotaibi :” Cyber Bullying and the Expected Consequences on the Students’
Academic Achievement”. vol. 7, pp.153417 - 153431, 16 October 2019, doi.
10.1109/ACCESS.2019.2947163.](https://image.slidesharecdn.com/predictingcyberbullyingontwitterusingmachinelearning3-211005023755/85/Predicting-cyber-bullying-on-t-witter-using-machine-learning-24-320.jpg)
![Reference
[4]. Pete Burnap1 and Matthew L Williams,” Us and them: identifying cyber hate on Twitter
across multiple protected characteristics”, Burnap and Williams ,. EPJ Data Science vol. 5,
Article number: 11, 23 March 2016,doi. 10.1140/epjds/s13688-016-0072-6.
•
[5]. Egundo Moisés Toapanta, John Angelo Recalde Monar, Luis Mafla Gallegos,”Prototype to
Perform Audit in Social Networks to Determine Cyberbullying”. 01 October
2020,doi.10.1109/WorldS450073.2020.9210335.
•
[6]. Saloni Wade1, Maithili Parulekar2, Prof. Kumud Wasnik,” Cyber Bullying Detection on
Twitter Mining” International research journal of engineering and technology (IRJET) vol. 07,
issue: 07 , July 2020.](https://image.slidesharecdn.com/predictingcyberbullyingontwitterusingmachinelearning3-211005023755/85/Predicting-cyber-bullying-on-t-witter-using-machine-learning-25-320.jpg)


Predicting cyber bullying on t witter using machine learning
- 1. PREDICTING CYBER BULLYING ON TWITTER USING MACHINE LEARNING U N D E R T H E G U I D A N C E O F , D R . E . I L A V A R A S A N , M . T E C H . , P H . D , P R O F E S S O R P O N D I C H E R R Y E N G I N E E R I N G C O L L E G E T E A M M E M B E R S : Z A H I D S H A B A N M I R ( 2 0 C S 3 3 9 ) J O H N P A U L A ( 2 0 C S 3 3 1 )
- 2. AGENDA Introduction Problem Definition Objectives of the proposed system Literature Review Proposed System Current Status of the project Hardware and Software requirements Conclusion References
- 3. INTRODUCTION In today’s world which has been made smaller by technology, new age problems have been born. No doubt technology has a lot of benefits; however, it also comes with a negative side. It has given birth to cyberbullying. To put it simply, cyberbullying refers to the misuse of information technology with the intention to harass others. Subsequently, cyberbullying comes in various forms. It doesn’t necessarily mean hacking someone’s profiles or posing to be someone else.
- 4. INTRODUCTION It also includes posting negative comments about somebody or spreading rumors to defame someone. As everyone is caught up on the social network, it makes it very easy for anyone to misuse this access. For this reason prediction of cyberbullying has become area of research.
- 5. PROBLEM DEFINITION In the last few years, online communication has shifted toward user- driven technologies, such as SM websites, blogs, online virtual communities, and online sharing platforms. New forms of aggression and violence emerge exclusively online. The dramatic increase in negative human behavior on SM, with high increments in aggressive behavior, presents a new challenge. Consequently, developing a cyber bullying prediction model that detects aggressive behavior that is related to the security of human beings is more important than developing a prediction model for aggressive behavior related to the security of machines.
- 6. OBJECTIVES OF THE PROPOSED SYSTEM: To propose our project NLP (Natural Language Processing) and Machine learning techniques for Cyberbullying prediction in social media. •By using NLP, get lot of features like sentiment analysis, pos- tagging, noun phrase extraction, etc Merits
- 7. OBJECTIVES OF THE PROPOSED SYSTEM: A word can appear as a verb in a sentence, whereas in other sentences, it can appear as an adverb. Also, based on the sentence structure, a word can be in the present, past, or past participle form. If we consider including all these words instead of stemming these words into their root form as part of our model, then dictionary size will be huge, and also, the model will perform a massive amount of unnecessary calculation, which is an inefficient use of the memory. So, ultimately the model will take more time during the training process. To avoid all these, we perform stemming operations to convert each word into its root form.
- 12. LIMITATIONS OF THE EXISTING SYSTEM/RESEARCH ISSUES: Cyberbullying prediction based on Content-based features of various machine learning methods. Increasing over fitting risk when the number of observations is insufficient Over fitting is not reduced. The given paper uses only text message as input. Demerits:
- 13. LIMITATIONS OF THE EXISTING SYSTEM/RESEARCH ISSUES: Training patterns cannot be updated dynamically .It has to be manually done every time The model takes more time during the training process to convert the each words to itsroot form. The given model does not deal with the real time problem where now days usage of words has modified people tend to use emoji and emoticons rather than typing words in such cases the proposed model does not have all the above mentioned features.
- 14. Existing System Collect input tweets from the tweeter. Preprocessing of input comments – remove duplicates, stop words, punctuations. Train the model using SVM and hyperparamater tunning is also done. Visualize the aspects of the given model. 1. 2. 3. 4.
- 15. THE PROPOSED SYSTEM 1.Collect input(text,audio) tweets from the tweeter. 2.Coversion of emoji and audio to text is done. 3.Preprocessing of input comments – remove duplicates, stop words, punctuations. 4.Train the model using RNN and hyperparamater tunning is also done. 5.Visualize the aspects of the given model.
- 16. ARCHITECTURE OF PROPOSED SYSTEM
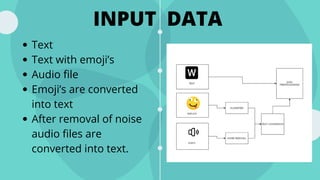
- 17. INPUT DATA Text Text with emoji’s Audio file Emoji’s are converted into text After removal of noise audio files are converted into text.
- 18. DATA PREPROCESSING •Tokenization(chopping it up into pieces) •Removing Stop Word(filtering of words) •Stemming and Lemmitazation (generation of root words) •GLoVe(Global Vectors for Word Representation)
- 19. RNN Recurrent Neural Network • Deep learning •Sequential data •Output from previous step are fed as input to the current step. •Important feature of RNN is Hidden state, which remembers some information about a sequence.
- 20. Current Status of the project •Collected the Datasets •Working with the datasets
- 21. Input and Output Example for cyber bullying or non- cyber bullying: Cyber bullying What.. you are an idiot?. Non- cyber bullying That person is a hero to us all.
- 22. Hardware and Software requirements Environment: •Software Requirements: •Cloud Tool: Anaconda •Operating system: 64 Bit OS (Windows 7/ 8 / 10) / Linux •Scripting : Python •IDE : Jupyter notebook,Google colab or Spyder. Hardware Requirements: •RAM: Minimum 4GB •ROM: 20 GB minimum
- 23. CONCLUSION Considering that social media has become the most common way to communicate, cyberbullying is the most common method of bullying. It is important to delete cyberbullying because it is plaguing every user, including our next generation . The situation with cyber bullying is getting only worse, as the incidents of depression and suicide are only increasing.In this we use NLP (Natural Language Processing) and Machine learning techniques for Cyberbullying prediction in social media. We believe that the current study will provide crucial details on and new directions in the field of detecting aggressive human behavior, including cyberbullying detection in online social networking sites.
- 24. Reference [1]. Mohammed ali al-garadi, Mohammad rashid hussain , Nawsher khan , Ghulam murtaza, Henry friday nweke, Ihsan ali , Ghulam mujtaba, Haruna chiroma , Hasan ali khattak , and Abdullah gani .“Predicting Cyberbullying on Social Media in the Big Data Era Using Machine Learning Algorithms: Review of Literature and Open Challenges. vol.7, pp. 70701 - 70718, 22 May 2019,doi.10.1109/ACCESS.2019.2918354. [2]. Waleed Mugahed Al-Rahmi ; Noraffandy Yahaya ; Mahdi M. Alamri,” A Model of Factors Affecting Cyber Bullying Behaviors Among University Students. vol. 7, pp. 153417– 153431, October. 2019,doi. 10.1109/ACCESS.2018.2881292. [3].Norah Basheer Alotaibi :” Cyber Bullying and the Expected Consequences on the Students’ Academic Achievement”. vol. 7, pp.153417 - 153431, 16 October 2019, doi. 10.1109/ACCESS.2019.2947163.
- 25. Reference [4]. Pete Burnap1 and Matthew L Williams,” Us and them: identifying cyber hate on Twitter across multiple protected characteristics”, Burnap and Williams ,. EPJ Data Science vol. 5, Article number: 11, 23 March 2016,doi. 10.1140/epjds/s13688-016-0072-6. • [5]. Egundo Moisés Toapanta, John Angelo Recalde Monar, Luis Mafla Gallegos,”Prototype to Perform Audit in Social Networks to Determine Cyberbullying”. 01 October 2020,doi.10.1109/WorldS450073.2020.9210335. • [6]. Saloni Wade1, Maithili Parulekar2, Prof. Kumud Wasnik,” Cyber Bullying Detection on Twitter Mining” International research journal of engineering and technology (IRJET) vol. 07, issue: 07 , July 2020.
- 26. QUERIES
- 27. THANK YOU