



























































Data mining techniques and dss
- 1. DM Myths of DM Techniques of DM
- 2. Myth #1:Data mining provides instant crystal ball-predictions Data mining is neither a crystal ball nor a technology where answers magically appear after pushing a single button. It's a multi-step process that includes: defining the business problem, exploring and conditioning data, developing the model, and deploying the knowledge gained. Typically, companies spend the bulk of their time preprocessing and conditioning the data to make sure it is clean, consistent, and combined properly to deliver business intelligence on which they can rely. Data mining is all about the data -- successful data mining requires data that accurately reflects the business.
- 3. Myth #2: Data mining is not yet viable for business application Data mining is viable technology and highly prized for its business results. The myth tends to be perpetrated by those who need to explain why they are not yet using the process and revolves around two related statements.
- 4. Myth #3: Data mining requires a data warehouse It is true that data mining can benefit from warehoused data that is well organized, relatively clean, and easy to access. This is particularly true if the warehouse has been constructed with data mining specifically in mind and with knowledge of the requirements of the data mining project. However, the warehoused data may be less useful for data mining than the source or operational data. In the worst case, warehoused data may be completely useless (for example, if only summary data are stored).
- 5. Myth #4: DM is all about algorithms People often misunderstood that "All you need for data mining is good algorithms. The better your algorithms, the better your data mining; advancing the effectiveness of data mining means advancing our knowledge of algorithms.“ This is often to misunderstand the data mining process. Data mining is a process consisting of many elements, such as formulating business goals, mapping business goals to data mining goals, acquiring, understanding, and pre-processing the data, evaluating and presenting the results of analysis and deploying these results to achieve business benefits. This is not to minimize the importance of new or improved data mining algorithms
- 6. Myth #5: DM should be done by technology expert Quite the opposite is true, due to the paramount importance of business knowledge in data mining. When performed without business knowledge, data mining can produce nonsensical or useless results so it is essential that data mining be performed by someone with extensive knowledge of the business problem. Very seldom is this the same person with extensive knowledge of the data mining technology. It is the responsibility of data mining tool providers to ensure that tools are accessible to business users.
- 7. Myth #6: Data mining is for large companies with lots of customer data The plain fact is that if a company, large or small, has data that accurately reflects the business or its customers, it can build models against that data that lend insights into important business challenges. The amount of customer data a company possesses has never been the issue.
- 8. Fundamental concepts of DM Classification Classification is the operation most commonly supported by commercial data mining tools. It is the process of sub-dividing a data set with regard to a number of specific outcomes. For example, classifying customers into ‘high’ and ‘low’ categories with regard to credit risk. The category or ‘class’ into which each customer is placed is the ‘outcome’ of the classification.
- 9. Prediction Prediction gives the future data states based on past and current data. Prediction can be viewed as a type of classification. Ex: Predicting floods Techniques for Classification and prediction decision trees, neural networks, nearest neighbour algorithms
- 10. Understanding v Prediction Sophisticated classification techniques enable us to discover new patterns in large and complex data sets. Classification is a powerful aid to understanding a particular problem. In some cases, improved understanding is sufficient. It may suggest new initiatives and provide information that improves future decision making. Often the reason for developing an accurate classification model is to improve our capability for prediction.
- 11. Training A classification model is said to be ‘trained’ on historical data, for which the outcome is known for each record. But beware over fitting: for example100 per cent of customers called Smith who live at 28 Arcadia Street responded to the offer. One would then use a separate test dataset of historical data to validate the model. The model could then be applied to a new, unclassified data set in order to predict the outcome for each record.
- 12. Clustering It is used to find groupings of similar records in a data set without any preconditions as to what that similarity may involve. Clustering is used to identify interesting groups in a customer base that may not have been recognised before. Often undertaken as an exploratory exercise before doing further data mining using a classification technique. Techniques for Clustering - cluster analysis, neural networks
- 13. Association analysis Association analysis looks for links between records in a data set. Sometimes referred to as ‘market basket analysis’, its most common aim is to discover which items are generally purchased at the same time.
- 14. Example of Association Analysis Consider the following beer and nappy example: 500,000 transactions 20,000 transactions contain nappies (4%) 30,000 transactions contain beer (6%) 10,000 transactions contain both nappies and beer (2%)
- 15. Sequential analysis Sequential analysis looks for temporal links between purchases, rather than relationships between items in a single transaction.
- 16. Support (or prevalence) Measures how often items occur together, as a percentage of the total transactions. In this example, beer and nappies occur together 2% of the time (10,000/500,000).
- 17. Confidence (or predictability) Measures how much a particular item is dependent on another. Because 20,000 transactions contain nappies and 10,000 of these transactions contain beer, when people buy nappies, they also buy beer 50% of the time. The confidence for the rule: When people buy nappies they also buy beer 50% of the time. is 50%. Because 30,000 transactions contain beer and 10,000 of these transactions contain nappies, when people buy beer, they also buy nappies 33.33% of the time.
- 18. Expected Confidence In the absence of any knowledge about what else was bought, we can also make the following assertions from the available data: People buy nappies 4% of the time. People buy beer 6% of the time. These numbers - 4% and 6% - are called the expected confidence of buying nappies or beer, regardless of what else is purchased.
- 19. Lift Measures the ratio between the confidence of a rule and the expected confidence that the second product will be purchased. Lift is measures of the strength of an effect. In our example, the confidence of the nappies-beer buying rule is 50%, whilst the expected confidence is 6% that an arbitrary customer will buy beer. So, the lift provided by the nappies-beer rule is :8.33 (= 50%/6%).
- 20. Forecasting Forecasting (unlike prediction based on classification models) concerns the prediction of continuous values, such a person’s income based on various personal details, or the level of the stock market. Simpler forecasting problems involve a single continuous value based on a series of unordered examples. More complex problem is to predict one or more values based on a sequential pattern. Techniques include statistical time-series analysis as well as neural networks.
- 21. Techniques used in DM Regression: This is used to map data item to a real valued prediction variable. Ex: A college professor wishing to calculate his future savings Time series analysis: In this the value of an attribute is examined as it varies over time. Ex: A company trying to analyze to whom the stock can be purchased, whether from X, Y, Z
- 22. Techniques used in DM (contd..) Summarization: This maps the data into subsets with associated simple descriptions. This is also called as characterization or generalization. Ex: Comparison of universities in US is the average SAT or ACT score. Association rules: This is a model that identifies specific types of data associations. Ex: a grocery store trying to decide whether to put bread on sale.
- 23. Overview of DM
- 24. Data Mining Steps Collect the Data Clean the Data Determine what is desired Determine optimal method/tool Mine the data Analyze and verify the results Use the results
- 25. Data Mining Steps (contd..)
- 26. Data Mining Input Data mining can effectively deal with inconsistencies in your data. Even If your sources are clean, integrated, and validated, they may contain data about the real world that is simply not true. This noise can, for example, be caused by errors in user input or just plain mistakes of customers filling in questionnaires. If it does not occur too often, data mining tools are able to ignore the noise and still find the overall patterns that exist in your data.
- 27. Data Mining Output The output of data mining can provide you with more flexibility. For example, if you have a budget to mail information to 1000 people about a new product, queries or OLAP analysis directly on your data will never be able to select exactly that number of people from your database. By enhancing your data with an attribute that you can use in your query or OLAP analysis, data mining enables you to find the 1000 people most likely to respond. This example also shows that data mining is not replacing OLAP, but enhancing it.
- 28. The Future of Data Mining In the short-term, the results of data mining will be in profitable, if mundane, business related areas. Micromarketing campaigns will explore new niches. Advertising will target potential customers with new precision. In the medium term, data mining may be as common and easy to use as e-mail. We may use these tools to find the best airfare to New York, root out a phone number of a long-lost classmate, or find the best prices on lawn mowers. The long-term prospects are truly exciting. Imagine intelligent agents turned loose on medical research data or on sub-atomic particle data. Computers may reveal new treatments for diseases or new insights into the nature of the universe. There are potential dangers, though, as discussed below.
- 29. Privacy Concerns What if every telephone call you make, every credit card purchase you make, every flight you take, every visit to the doctor you make, every warranty card you send in, every employment application you fill out, every school record you have, your credit record, every web page you visit ... was all collected together? A lot would be known about you! This is an all-too-real possibility. In a database, too much information about too many people for anybody is going to make any sense? Not with data mining tools running on massively parallel processing computers! Would you feel comfortable about someone having access to all this data about you? And remember, all this data does not have to reside in one physical location; as the net grows; information of this type becomes more available to more people.
- 30. Proposed solutions might be… Data are intentionally modified from their original version, in order to misinform the recipients or for privacy and security legislation designed to protect consumers against data security failures by, among other things, requiring companies to notify consumers when their personal information has been compromised.
- 31. Expanding universe of data Nowadays, the world is regarded as an expanding universe of data. We have an infinite amount of data, yet little information. Some people look at this phenomenon as a new paradox of the growth of data, that is, more data means less information. Therefore, there is an urgent need for the development of new techniques to find the required information from huge amount of data.
- 32. Expanding universe of data The following factors make the data mining as a very important technique to extract implicit, previously unknown and potentially useful knowledge from data. Data mining algorithms can find "optimal" clustering or interesting regularities in a Database. Data mining algorithms typically zoom in on interesting sub-parts of the Databases. Networks make it easy to connect Databases. Machine learning techniques make it easier to find interesting connections in Database. Client/Server revolution.
- 33. Information as a factor of production Increase in available data Exacerbated by World Wide Website Information overload Computer assistance to filter, select and interpret data Extend this to allow computers to discover relevant information In the future machine assistance will become more and more important
- 34. Architecture of Data Mining
- 35. Components explained Database, data warehouse, or other information repository: This is one or a set of databases, data warehouses, spread sheets, or other kinds of information repositories. Data cleaning and data integration techniques may be performed on the data. Database or data warehouse server: The database or data warehouse server is responsible for fetching the relevant data, based on the user's data mining request.
- 36. Components explained Knowledge base: This is the domain knowledge that is used to guide the search, or evaluate the interestingness of resulting patterns. Such knowledge can include concept hierarchies, used to organize attributes or attribute values into different levels of abstraction. Knowledge such as user beliefs, which can be used to assess a pattern's interestingness based on its unexpectedness, may also be included. Other examples of domain knowledge are additional interestingness constraints or thresholds, and metadata (e.g., describing data from multiple heterogeneous sources). .
- 37. Components explained Data mining engine: This is essential to the data mining system and ideally consists of a set of functional modules for tasks such as characterization, association analysis, classification, evolution and deviation analysis.
- 38. Components explained Pattern evaluation module: This component typically employs interestingness measures and interacts with the data mining modules so as to focus the search towards interesting patterns. It may access interestingness thresholds stored in the knowledge base. Alternatively, the pattern evaluation module may be integrated with the mining module, depending on the implementation of the data mining method used.
- 39. Components explained Graphical user interface: This module communicates between users and the data mining system, allowing the user to interact with the system by specifying a data mining query or task, providing information to help focus the search, and performing exploratory data mining based on the intermediate data mining results. In addition, this component allows the user to browse database and data warehouse schemas or data structures, evaluate mined patterns, and visualize the patterns in different forms.
- 40. Classification of DM Classification according to the kinds of databases mined. A data mining system can be classified according to the kinds of databases mined. Database systems themselves can be classified according to different criteria (such as data models, or the types of data or applications involved), each of which may require its own data mining technique. Data mining systems can therefore be classified accordingly.
- 41. Classification of DM Classification according to the kinds of databases mined. For instance, if classifying according to data models, we may have a relational, transactional, object-oriented, object-relational, or data warehouse mining system. If classifying according to the special types of data handled, we may have a spatial, time-series, text, or multimedia data mining system, or a World-Wide Web mining system. Other system types include heterogeneous data mining systems, and legacy data mining systems.
- 42. Classification of DM Classification according to the kinds of knowledge mined. Data mining systems can be categorized according to the kinds of knowledge they mine, i.e., based on data mining functionalities, such as characterization, discrimination, association, classification, clustering, trend and evolution analysis, deviation analysis, similarity analysis, etc.
- 43. Classification of DM Classification according to the kinds of techniques utilized. These techniques can be described according to the degree of user interaction involved (e.g., autonomous systems, interactive exploratory systems, query-driven systems), or the methods of data analysis employed (e.g., database-oriented or data warehouse-oriented techniques, machine learning, statistics, visualization, pattern recognition, neural networks, and so on). A sophisticated data mining system will often adopt multiple data mining techniques or work out an effective, integrated technique which combines the merits of a few individual approaches.
- 44. Decision Support Systems (DSS) A decision support system is a computer- based system that supports the decision making process • Assist decision makers in semi-structured tasks • Support not replace human judgment • Highly interactive • Improve effectiveness of human decision makers
- 45. DSS characteristics Provide support in semi-structured and unstructured situations, includes human judgment and computerized information Support for various managerial levels Support to individuals and groups Support to interdependent and/or sequential decisions Support all phases of the decision-making process Support a variety of decision-making processes and styles
- 46. DSS characteristics Are adaptive Have user friendly interfaces Goal: improve effectiveness of decision making The decision maker controls the decisionmaking process End-users can build simple systems Utilizes models for analysis Provides access to a variety of data sources, formats, and types
- 47. Why DSS? • Increasing complexity of decisions o Technology o Information: • “Data, data everywhere, and not the time to think!” o Number and complexity of options o Pace of change
- 48. Why DSS? • Increasing availability of computerized support o Inexpensive high-powered computing o Better software o More efficient software development process • Increasing usability of computers o COTS (Commercial Off The Shelf) tools o Customization
- 49. Types of Problems • Structured o Repetitive o Standard solution methods exist o Complete automation may be feasible • Unstructured o One-time o No standard solutions o Rely on judgment o Automation is usually infeasible • Semi-structured o Some elements and/or phases of decision making process have repetitive elements
- 50. Decision Support Trends • IT is increasingly pervasive • Users are increasingly computer savvy • Computer hardware is increasingly smaller and more powerful • Systems are increasingly interconnected • The Web is increasingly interwoven into all aspects of our lives • Demand for usable, flexible, powerful decision support will continue to grow • Decision support will be embedded into a wide variety of consumer and business products
- 51. Humans and Computers: Complementary Strengths • Human decision makers o Good at seeing patterns o Can work with incomplete problem representations o Exercise subtle judgment we do not know how to automate o Often unaware of how they perform tasks o Poor at integrating large numbers of cues o Unreliable and slow at tedious bookkeeping tasks and complex calculations
- 52. Humans and Computers: Complementary Strengths Computers o Still inferior to humans at pattern recognition, messy unstructured problems o Good at integrating large numbers of features o Good at tedious bookkeeping o Rapid and accurate at complex calculations
- 53. DSS classifications Model Driven DSS: A model-driven DSS emphasizes access to and manipulation of financial, optimization and/or simulation models. Simple quantitative models provide the most elementary level of functionality. Data Driven DSS: Data-driven DSS emphasizes access to and manipulation of a time-series of internal company data and sometimes external and real-time data. Simple file systems accessed by query and retrieval tools provide the most elementary level of functionality.
- 54. DSS classifications Communication Driven DSS: Communications- driven DSS use network and communications technologies to facilitate decision-relevant collaboration and communication. In these systems, communication technologies are the dominant architectural component. Document Driven DSS: Document-driven DSS uses computer storage and processing technologies to provide document retrieval and analysis. Large document databases may include scanned documents, hypertext documents, images, sounds and video.
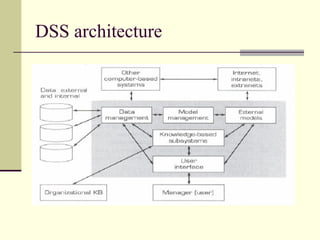
- 55. DSS architecture
- 56. Data Management subsystem consists of DSS database, Database management system, Data directory and Query facility. It does the following Captures/ extracts data for inclusion in a DSS database Updates (adds, deletes, edits, changes) data records and files Interrelates data from different sources Retrieves data from the database for queries and reports
- 57. Data Management subsystem Provides comprehensive data security(protection from unauthorised access, recovery capabilities, etc) Handles personal and unofficial data so that users can experiment with alternative solutions based on their own judgement Performs complex data manipulation tasks based on queries Tracks data use within DSS Manages data through a data dictionary
- 58. Model Management Sub system consists of Analog of the database management subsystem, Model base, Model base management system, Modeling language, Model directory, Model execution, integration, and command processor Strategic Models: Non routine mergers, impact analysis, capital budgeting Tactical Models: Allocation & Control labor requirements, sales promotion planning Operational Models: Routine-day-to-day production scheduling, inventory control, quality control Analytical Models: SAS, SPSS, OR, data mining
- 59. KBS Knowledge based Subsystem Provides expertise in solving complex unstructured and semi-structured problems Expertise provided by an expert system or other intelligent system Advanced DSS have a knowledge based (management) component Leads to intelligent DSS Example: Data mining
- 60. User interface User Interface sub system Includes all communication between a user and the MSS Graphical user interfaces (GUI) Voice recognition and speech synthesis possible
- 61. User Different usage patterns for the user, the manager, or the decision maker Managers Staff specialists Intermediaries 1. Staff assistant 2. Expert tool user 3. Business (system) analyst 4. GSS Facilitator