















![1. Introduction: (Decision Trees)
17
1.1 Decision trees are a model where we break our data by making decisions using series of conditions
(questions). It is type of supervised machine learning.
1.2 Decision node:
A decision tree is composed of internal decision nodes and terminal leaves, each branch node represents a
choice between a number of alternatives and each leaf node represents a decision.
Each decision node m implements a test function fm(x) with discrete outcomes.
1.3 Decision Tree Components :
● Root node
o It refers to the start of the decision tree with maximum split (Information Gain[decides which attributes
goes into a decision node])
● Node
o Node is a condition with multiple outcomes in the tree.
● Leaf
o This is the final decision(end point) of a node from the condition(question)](https://image.slidesharecdn.com/g-13mlpdfdecisiontrees-201226010818/85/Probability-distribution-Function-Decision-Trees-in-machine-learning-17-320.jpg)


















Probability distribution Function & Decision Trees in machine learning
- 1. Machine Learning • Probability Distribution Function (PDF) • Decision Trees
- 2. Submitted To: “Dr. Ahmed Jalal” Submitted By: 1. Sadia Zafar (170403) 2. Mahnoor Fatima (170399) 3. Asmavia Rasheed (170335) Facets:
- 3. Table of Contents: Probability Distribution Function Decision Tress Introduction - Definition - Mathematical Formula Introduction - Decision Tree - Decision Node - Components Types - Normal Probabilty Distribution - Binomial Probabilty Distribution - Poisson Probabilty Distribution Decision Trees Algorithm - Classification Trees - Regression Trees - Examples Applications Overfitting - Causes of Overfitting - Examples - Avoid Overfitting Examples - For Random Variable - For Continuous Variable Pruning MATLAB Implementation MATLAB Implementation
- 4. 1. Introduction: (Probability Distribution Function) 4 1.1 Definition It is used to describe the probability that a continuous random variable and will fall within a specified range. In theory, the probability that a continuous value can be a specified value is zero because there are an infinite number of values for the continuous random value. 1.2 Formula
- 5. 2. Probability Distribution Function: 5 Types of Probability distribution function • Normal Probability Distribution • Binomial Probability Distribution • Poisson Probability Distribution
- 6. 2.1 Normal Probabilty Distribution 6 The Normal Probability Distribution is very common in the field of statistics. Whenever we measure things like people's height, weight, salary, opinions or votes, the graph of the results is very often a normal curve. Formula:
- 7. 2.1 Normal Probability Distribution: 7 Properties of a Normal Distribution: The normal curve is symmetrical about the mean μ; The mean is at the middle and divides the area into halves; The total area under the curve is equal to 1; It is completely determined by its mean and standard deviation σ (or variance σ2) Note: In a normal distribution, only 2 parameters are needed, namely μ and σ2
- 8. 2.2 Binomial Probabilty distribution 8 A binomial experiment is one that possesses the following properties: The experiment consists of n repeated trials; Each trial results in an outcome that may be classified as a success or a failure (hence the name, binomial); The probability of a success, denoted by p, remains constant from trial to trial and repeated trials are independent. The number of successes X in n trials of a binomial experiment is called a binomial random variable. Formula: P(X) = 𝐶 𝜘 𝑛 𝑝 𝑥 𝑞 𝑛 − 𝑥 where: n = the number of trials x = 0,1,2,3,… n p = the probability of success in a single trial q = the probability of failure in a single trial (i.e. q = 1 – p) 𝐶 𝜘 𝑛 is a combination.
- 9. 2.3 Poisson probability Distribution 9 The Poisson random variable satisfies the following conditions: The number of successes in two disjoint time intervals is independent. The probability of a success during a small time interval is proportional to the entire length of the time interval. Apart from disjoint time intervals, the Poisson random variable also applies to disjoint regions of space Formula 𝑃 𝑋 = 𝑒−𝜇 𝜇 𝑥 𝑥! Where: x = 0,1,2,3. . . e = 2.71828 = mean number of successes in the given time interval or region of space
- 10. 3.Probability Distribution Function: 10 Applications • The number of deaths by horse kicking in the Prussian army (first application) • Birth defects and genetic mutations • Rare diseases (like Leukemia, but not AIDS because it is infectious and so not independent) - especially in legal cases • Car accidents • Traffic flow and ideal gap distance • Number of typing errors on a page • Hairs found in McDonald's hamburgers • Spread of an endangered animal in Africa • Failure of a machine in one month
- 11. 4. Probability Distribution Function: 11 4.1 Example: Problem 1 ( For Random Variables ) Consider a scenario where a person rolls two dice (die) and adds up the numbers rolled. Since the numbers on dice range from 1 to 6, the set of possible outcomes is from 2 to 12. A pdf can be used to show the probability of realizing any value from 2 to 12. It shows the set of possible outcomes along with the number of ways of achieving the outcome value, the probability of achieving each outcome value (pdf). For example, there were 6 different ways to roll a 7 from two dice. These combinations are (1,6), (2,5), (3,4), (4,3), (5,2), and (6,1). Since there are 36 different combinations of outcomes from the two die, the probability of rolling a seven is 6/36=1/6, and thus, the pdf of 7 is 16.7%.
- 12. 4. Probability Distribution Function (Example) 12 Graphical Representation of PDF:
- 13. 4. Probability Distribution Function 13 4.2 Example: Problem 2: ( For Continuous Variables) A sample of data for a standard normal distribution. The left- hand side of the table has the interval values a and b. The corresponding probability to the immediate right in this table shows the probability that the standard normal distribution will have a value between a and b. That is, if x is a standard normal variable, the probability that x will have a value between a and b is shown in the probability column. Table
- 14. 14 4.2 Example: 2 (Continue) For a standard normal distribution, the values shown in column “a” and column “b” can also be thought of as the number of standard deviations where 1=plus one standard deviation and −1=minus one standard deviation (and the same for the other values). Readers familiar with probability and statistics will surely recall that the probability that a standard normal random variable will be between −1 and +1 is 68.3%, the probability that a standard normal variable will be between −2 and +2 is 95.4%, and the probability that a standard normal variable will be between −3 and +3 is 99.7%. The data on the right-hand side of the table corresponds to the probability that a standard normal random value will be less than the value indicated in the column titled z. Readers familiar with probability and statistics will recall that the probability that a normal standard variable will be less than 0 is 50%, less than 1 is 84%, less than 2 is 97.7%, and less than 3 is 99.9%. Graphical representation of pdf 4. Probability Distribution Function
- 15. 5.PDF MATLAB Implementation: 15 This example shows how to fit probability distribution objects to grouped sample data, and create a plot to visually compare the pdf of each group. The data contains miles per gallon (MPG) measurements for different makes and models of cars, grouped by country of origin (Origin), model year (Model_Year), and other vehicle characteristics.
- 17. 1. Introduction: (Decision Trees) 17 1.1 Decision trees are a model where we break our data by making decisions using series of conditions (questions). It is type of supervised machine learning. 1.2 Decision node: A decision tree is composed of internal decision nodes and terminal leaves, each branch node represents a choice between a number of alternatives and each leaf node represents a decision. Each decision node m implements a test function fm(x) with discrete outcomes. 1.3 Decision Tree Components : ● Root node o It refers to the start of the decision tree with maximum split (Information Gain[decides which attributes goes into a decision node]) ● Node o Node is a condition with multiple outcomes in the tree. ● Leaf o This is the final decision(end point) of a node from the condition(question)
- 18. Decision Tree Example 1 A decision tree for person health problem. • Is a person healthy? • For this purpose, we must provide certain information like does he walk daily? Does he eat healthy? 18
- 19. Decision Tree Example 2 A decision tree for the mammal classification problem. Root Node -> Body Temperature Internal Node -> Gives Birth Leaf Node -> Non-mammals (Last node) 19
- 20. 2. Decision Tree Algorithms: 20 2.1 Classification Tree: A classification, impurity measure tree, the goodness of a split is quantified by an impurity measure. It maps the data into predefined groups or classes and searches for new patterns. For example, we may wish to use classification to predict whether the weather on a particular day will be “sunny”, “rainy”, or “cloudy”. Impurity Metrics: It can be calculated by using impurity measures of each split. 1. Entropy 2. Gini Index (Ig) 3. Misclassification Error where c is the number of classes and 0 log2 0 = 0 in entropy calculations.
- 21. 2.1 Classification Tree: 21 Entropy: • Entropy is a measure of the uncertainty about a source of messages. • Given a collection S, containing positive and negative examples of some target concept, the entropy of S relative to this classification. where, pi is the proportion of S belonging to class i Entropy is 0 if all the members of S belong to the same class. Entropy is 1 when the collection contains an equal no. of +ve and -ve examples. Entropy is between 0 and 1 if the collection contains unequal no. of +ve and -ve examples.
- 22. 2.1 Classification Tree: 22 Gini Index (Ig): • The gini index of node impurity is the measure most commonly chosen for classification-type problems. • If a dataset T contains examples from n classes. • Gini index, Gini(T) is defined as: where pj is the relative frequency of class j in T • If a dataset T is split into two subsets T1 and T2 with sizes N1 and N2 respectively, the gini index of the split data contains examples from n classes, the gini index (T) is defined as: Ginisplit(T) = N1/N gini(T1) + N2/N gini(T2)
- 23. 2.1 Classification Tree: 23 Misclassification Error: Misclassification occur due to selection of property which is not suitable for classification. When all classes, groups, or categories of a variable have the same error rate or probability of being misclassified then it is said to be misclassification error. Figure Shows Comparison of all Impurity Metrics Scaled Entropy = Entropy/2 Gini Index is intermediate values of impurity lying between classification error and entropy.
- 24. 2.1 Classification Tree: 24 Numerical Example of Entropy, Gini Index, Misclassification error:
- 25. 2. Decision Tree Algorithms: 25 2.2 Regression Tree: • Used to predict for individuals on the basis of information gained from a previous sample of similar individuals. It has continuous varying data. For Example: • A person wants do some savings for future and then it will be based on his current values and several past values. He uses a linear regression formula to predict his future savings. • It may also be used in modelling the effect of doses in medicines or agriculture, response of a customer to a mail and evaluate the risk that the client will not pay back the loan taken from the bank. • Day can be sunny, cloudy, rainy or mild. Weather doesn’t consist on one or two things. In fact, it depends on temperature, wind, humidity. And it varies hourly. So data is continuous varying and decision can be changed according to current parameters.
- 26. 3. Overfitting: 26 • If a decision tree is fully grown, it may lose some generalization capability. • This is a phenomenon known as overfitting. “A hypothesis overfits the training examples if some other hypothesis that fits the training examples less well actually performs better over the entire distribution of instances (i.e., including instances beyond the training examples)” 3.1 Causes of Overfitting: 1. Overfitting Due to Presence of Noise: - Mislabeled instances may contradict the class labels of other similar records. 2. Overfitting Due to Lack of Representative Instances: - Lack of representative instances in the training data can prevent refinement of the learning algorithm.
- 27. 3. Overfitting: 27 4.1 Overfitting Due to Presence of Noise: An Example
- 30. 3. Overfitting: 30 3.1 Overfitting Due to Lack of Representative Instances: - Lack of representative instances in the training data can prevent refinement of the learning algorithm
- 32. 3. Overfitting: 32 3.2 Avoid Overfitting in Decision Trees: “A good model must not only fit the training data well but also accurately classify records it has never seen.” • Approaches that stop growing the tree earlier, before it reaches the point where it perfectly classifies the training data. • Approaches that allow the tree to overfit the data, and then post-prune the tree. • Approaches: • Separate set of examples.
- 33. 4. Pruning: 33 • Consider each of the decision nodes in the tree to be candidates for pruning. • Pruning a decision node consists of removing the subtree rooted at that node, making it a leaf node, and assigning it the most common classification of the training examples affiliated with that node. • Nodes are removed only if the resulting pruned tree performs no worse than the original over the validation set. • Pruning of nodes continues until further pruning is harmful (i.e., decreases accuracy of the tree over the validation set). • Illustration:
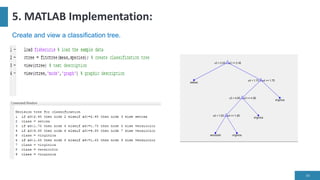
- 34. 5. MATLAB Implementation: 34 Create and view a classification tree.
- 35. 5.MATLAB Implementation: 35 Now, create and view a regression tree.
- 36. 36