
























































































An Overview of Apache Spark
- 1. An Overview of Apache Spark CS5607: High Performance Computational Infrastructures By: Yasoda Jayaweera
- 2. SPEAKER Yasoda Jayaweera PhD Student Brunel University, London ([email protected])
- 3. OUTLINE Spark Eco-system Spark Lifecycle Why users opt for Spark? Introduction to Apache Spark Learning Material
- 5. An open-source cluster-computing framework for large-scale data processing APACHE SPARK Yasoda Jayaweera ([email protected])
- 6. APACHE SPARK TIMELINE https://www.simplilearn.com/apache-spark-guide-for-newbies-article Yasoda Jayaweera ([email protected])
- 7. 100TB DAYTONA SORT BENCHMARK 2014 “Databricks set the record for Gray Sort Benchmark, sorting 100TB of data, or 1 trillion records in 23 minutes, which was 30 times more efficient per node than the previous record, 72 mins, held by Apache Hadoop MapReduce” Yasoda Jayaweera ([email protected])
- 8. 100TB CLOUD SORT BENCHMARK 2016 “Databricks reduced the per terabyte cost from 4.51 dollars, the previous world record held by University of California, San Diego in 2014, to 1.44 dollars” Yasoda Jayaweera ([email protected])
- 9. NOTABLE SPARK USERS Yasoda Jayaweera ([email protected]) Apache Spark Survey 2016 Report
- 10. PRODUCTS POWERED BY SPARK Yasoda Jayaweera ([email protected])
- 11. SPARK PRODUCTS BY INDUSTRY Apache Spark Survey 2016 Report Yasoda Jayaweera ([email protected])
- 12. IMPORTANT SPARK FEATURES Apache Spark Survey 2016 Report Yasoda Jayaweera ([email protected])
- 13. MAP REDUCE AND I/O OVERHEAD Read from disk -> process -> write back to disk Yasoda Jayaweera ([email protected])
- 14. MAP REDUCE AND I/O OVERHEAD Iterative processing e.g. Machine learning Repeatedly accessing the disk I/O Overhead Yasoda Jayaweera ([email protected])
- 15. MAP REDUCE AND I/O OVERHEAD Memory Hard disk/ SSD 100 – 600 MB/s10 GB/s 125 MB/s Yasoda Jayaweera ([email protected])
- 16. MAP REDUCE AND I/O OVERHEAD Memory Hard disk/ SSD 100 – 600 MB/s10 GB/s 125 MB/s 10,000 times faster Yasoda Jayaweera ([email protected])
- 17. MAP REDUCE AND I/O OVERHEAD In memory computation Yasoda Jayaweera ([email protected])
- 18. It is not always the case with MapReduce that you just executed your job on HDFS data and you are done. There are certain use cases where you need to take HDFS data as an input execute your job which writes output on HDFS. And than after another MapReduce job get executed which uses the output of previous job. Now think for a moment, every time when MapReduce job is executed it reads data from HDFS (eventually from disk) and writes output on HDFS (eventually on disk). And in case your job needs such multiple iterations, it will be very slow due to Disk IO at every iteration. In case of Apache Spark, it keeps the output of your previous stage in memory for that in next iteration it can be retrieved from memory which is quite faster than Disk IO. MAP REDUCE AND I/O OVERHEAD Yasoda Jayaweera ([email protected])
- 19. SPARK ECOSYSTEM
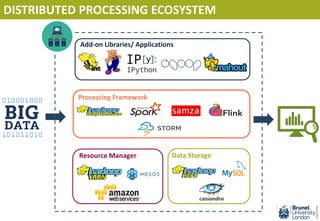
- 21. Data Storage DISTRIBUTED PROCESSING ECOSYSTEM
- 22. Processing Framework Data Storage DISTRIBUTED PROCESSING ECOSYSTEM
- 23. Processing Framework Data StorageResource Manager DISTRIBUTED PROCESSING ECOSYSTEM
- 24. Processing Framework Data StorageResource Manager Add-on Libraries/ Applications DISTRIBUTED PROCESSING ECOSYSTEM
- 25. Processing Framework Data Storage Resource Manager Add-on Libraries/ Applications DISTRIBUTED PROCESSING ECOSYSTEM
- 26. Processing Framework Data StorageResource Manager Add-on Libraries/ Applications DISTRIBUTED PROCESSING ECOSYSTEM
- 27. Processing Framework Data StorageResource Manager Add-on Libraries/ Applications DISTRIBUTED PROCESSING ECOSYSTEM
- 28. Processing Framework Data StorageResource Manager Add-on Libraries/ Applications DISTRIBUTED PROCESSING ECOSYSTEM
- 29. APACHE SPARK ECO SYSTEM Spark Core Yasoda Jayaweera ([email protected])
- 30. APACHE SPARK ECO SYSTEM Spark Core Data Frame API Yasoda Jayaweera ([email protected])
- 31. APACHE SPARK ECO SYSTEM Spark Core Data Frame API Spark SQL Spark Streaming MLlib Add-on library Yasoda Jayaweera ([email protected])
- 32. APACHE SPARK ECO SYSTEM Spark core - Inner most layer - Core represents the functionalities of Spark - Spark can run both in-memory or on disk (like Hadoop) Data frame API - Programming languages which are used to instruct Spark (invoke it’s functionalities) - Spark supports 4 main languages (Scala – which is the language Spark is built on, R, Python and Java Add-on libraries – Additional functionality which the core doesn’t supply - SQL, streaming, machine learning (MLlib) and graph processing are inbuilt in Spark - BlinkDB and Tachyon are 3rd party applications Yasoda Jayaweera ([email protected])
- 33. SPARK LIFE CYCLE
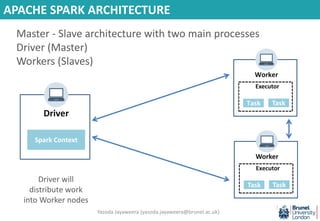
- 34. Driver Spark Context Executor Worker Spark Context Task Task Executor Worker Spark Context Task Task APACHE SPARK ARCHITECTURE Driver will distribute work into Worker nodes Master - Slave architecture with two main processes Driver (Master) Workers (Slaves) Yasoda Jayaweera ([email protected])
- 35. DATA REPRESENTATION IN SPARK RDD (Resilient Distributed Dataset) - Representation of the partitioned data in the memory - Immutable Yasoda Jayaweera ([email protected])
- 36. RDD CREATION AND DISTRIBUTION Tiger Dog Pig Elephant Cat Robin Dolphin Shark Gold fish Rooster Beaver Peacock Fox Rat Bat Jaguar Sheep Cow RDD Partition 6Partition 1 Partition 3 Partition 4 Partition 5Partition 2 More partitions -> more parallelism (more you can spread it around the cluster) Data partitioning is done using partitioning algorithms Yasoda Jayaweera ([email protected])
- 37. RDD CREATION AND DISTRIBUTION Cluster of 3 nodes Tiger Dog Pig Elephant Cat Robin Dolphin Shark Gold fish Rooster Beaver Peacock Fox Rat Bat Jaguar Sheep Cow RDD Partition 6 Worker Executor RDDRDD Worker Executor RDD Worker Executor RDD RDD RDD Partition 1 Partition 3 Partition 4 Partition 5Partition 2
- 38. RDD CREATION AND DISTRIBUTION Cluster of 3 nodes Tiger Dog Pig Elephant Cat Robin Dolphin Shark Gold fish Rooster Beaver Peacock Fox Rat Bat Jaguar Sheep Cow RDD Partition 6 Worker Executor RDDRDD Worker Executor RDD Worker Executor RDD RDD RDD Partition 1 Partition 3 Partition 4 Partition 5Partition 2
- 39. RDD CREATION AND DISTRIBUTION Cluster of 3 nodes Tiger Dog Pig Elephant Cat Robin Dolphin Shark Gold fish Rooster Beaver Peacock Fox Rat Bat Jaguar Sheep Cow RDD Partition 6 Worker Executor RDDRDD Worker Executor RDD Worker Executor RDD RDD RDD Partition 1 Partition 3 Partition 4 Partition 5Partition 2
- 40. RDD CREATION AND DISTRIBUTION Cluster of 3 nodes Tiger Dog Pig Elephant Cat Robin Dolphin Shark Gold fish Rooster Beaver Peacock Fox Rat Bat Jaguar Sheep Cow RDD Partition 6 Worker Executor RDDRDD Worker Executor RDD Worker Executor RDD RDD RDD Partition 1 Partition 3 Partition 4 Partition 5Partition 2
- 41. RDD CREATION AND DISTRIBUTION Cluster of 3 nodes Tiger Dog Pig Elephant Cat Robin Dolphin Shark Gold fish Rooster Beaver Peacock Fox Rat Bat Jaguar Sheep Cow RDD Partition 6 Worker Executor RDDRDD Worker Executor RDD Worker Executor RDD RDD RDD Partition 1 Partition 3 Partition 4 Partition 5Partition 2 There are partitioning algorithms to do the allocation in the most efficient manner
- 42. RDD OPERATIONS Two types of operations on RDDs - Transformations - Actions Yasoda Jayaweera ([email protected])
- 43. RDD OPERATIONS - TRANSFORMATIONS Transformations - Functions used to transform the data in an RDD - Transformed data is always loaded into a new RDD (immutable RDD) - Examples: map(), flatMap(), filter(), union(), intersection() groupByKey(), reduceByKey(), join(), sample() etc - Applying a transformation doesn’t load data into a RDD Yasoda Jayaweera ([email protected])
- 44. RDD OPERATIONS - ACTIONS Actions - Returns a value after running a computation on a dataset - Examples: reduce(), collect(), count(), countByKey(), takeSample(), saveAsTextFile() etc - Triggering an action will load data into a RDD Yasoda Jayaweera ([email protected])
- 45. SPARK : WordCount JavaRDD<String> textFile = sc.textFile("hdfs://..."); JavaPairRDD<String, Integer> counts = textFile .flatMap(s -> Arrays.asList(s.split(" ")).iterator()) .mapToPair(word -> new Tuple2<>(word, 1)) .reduceByKey((a, b) -> a + b); counts.saveAsTextFile("hdfs://..."); Yasoda Jayaweera ([email protected])
- 46. SPARK : WordCount val textFile = sc.textFile("hdfs://...") val counts = textFile.flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _) counts.saveAsTextFile("hdfs://...") Yasoda Jayaweera ([email protected])
- 47. SPARK : WordCount text_file = sc.textFile("hdfs://...") counts = text_file.flatMap(lambda line: line.split(" ")) .map(lambda word: (word, 1)) .reduceByKey(lambda a, b: a + b) counts.saveAsTextFile("hdfs://...") Yasoda Jayaweera ([email protected])
- 48. APACHE SPARK LIFE CYCLE JavaRDD<String> textFile = sc.textFile("hdfs://..");
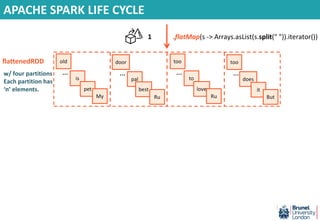
- 49. APACHE SPARK LIFE CYCLE JavaRDD<String> textFile = sc.textFile("hdfs://.."); Input/ base RDD w/ four partitions My pet is a dog. Its name is Ru. Ru is five years old. Ru’s best pal is Suddi who lives next door. Ru loves to eat tuna and mangoes. It loves birds too. But it does not like children. Ru hates bathing too. W W W W
- 50. APACHE SPARK LIFE CYCLE My pet is a dog. Its name is Ru. Ru is five years old. Ru’s best pal is Suddi who lives next door. Ru loves to eat tuna and mangoes. It loves birds too. But it does not like children. Ru hates bathing too. .flatMap(s -> Arrays.asList(s.split(" ")).iterator()) JavaRDD<String> textFile = sc.textFile("hdfs://.."); Input/ base RDD w/ four partitions 1
- 51. APACHE SPARK LIFE CYCLE My pet is a dog. Its name is Ru. Ru is five years old. Ru’s best pal is Suddi who lives next door. Ru loves to eat tuna and mangoes. It loves birds too. But it does not like children. Ru hates bathing too. old … is pet My .flatMap(s -> Arrays.asList(s.split(" ")).iterator()) door … pal best Ru too … to love Ru too … does it But JavaRDD<String> textFile = sc.textFile("hdfs://.."); flattened RDD w/ four partitions Each partition has ‘n’ elements. Input/ base RDD w/ four partitions W W W W 1
- 52. APACHE SPARK LIFE CYCLE .flatMap(s -> Arrays.asList(s.split(" ")).iterator()) old … is pet My door … pal best Ru too … to love Ru too … does it But flattenedRDD w/ four partitions Each partition has ‘n’ elements. 1
- 53. APACHE SPARK LIFE CYCLE .flatMap(s -> Arrays.asList(s.split(" ")).iterator()) old … is pet My door … pal best Ru too … to love Ru too … does it But .mapToPair(word -> new Tuple2<>(word, 1)) flattenedRDD w/ four partitions Each partition has ‘n’ elements. 1 2
- 54. APACHE SPARK LIFE CYCLE .flatMap(s -> Arrays.asList(s.split(" ")).iterator()) old … is pet My door … pal best Ru too … to love Ru too … does it But .mapToPair(word -> new Tuple2<>(word, 1)) flattenedRDD w/ four partitions Each partition has ‘n’ elements. mapPairsRDD w/ four partitions Each partition has ‘n’ elements. (My, 1) (Pet, 1) (is, 1) (Ru, 1) (best, 1) (pal, 1) (Ru, 1) (love, 1) (to, 1) (But, 1) (it, 1) (too, 1) W W W W 1 2
- 55. APACHE SPARK LIFE CYCLE .mapToPair(word -> new Tuple2<>(word, 1)) mapPairsRDD w/ four partitions Each partition has ‘n’ elements. (My, 1) (Pet, 1) (is, 1) (Ru, 1) (best, 1) (pal, 1) (Ru, 1) (love, 1) (to, 1) (But, 1) (it, 1) (too, 1) 2
- 56. APACHE SPARK LIFE CYCLE .mapToPair(word -> new Tuple2<>(word, 1)) .reduceByKey((a, b) -> a + b); mapPairsRDD w/ four partitions Each partition has ‘n’ elements. (My, 1) (Pet, 1) (is, 1) (Ru, 1) (best, 1) (pal, 1) (Ru, 1) (love, 1) (to, 1) (But, 1) (it, 1) (too, 1) 2 3
- 57. APACHE SPARK LIFE CYCLE .mapToPair(word -> new Tuple2<>(word, 1)) (My, 1) (Pet, 1) (is, 3) .reduceByKey((a, b) -> a + b); mapPairsRDD w/ four partitions Each partition has ‘n’ elements. (My, 1) (Pet, 1) (is, 1) (Ru, 1) (best, 1) (pal, 1) (Ru, 1) (love, 1) (to, 1) (But, 1) (it, 1) (too, 1) localSumRDD w/ four partitions Each partition has ‘n’ elements. W W W W 2 3
- 58. APACHE SPARK LIFE CYCLE (My, 1) (Pet, 1) (is, 3) .reduceByKey((a, b) -> a + b); (My, 1) (Pet, 1) (is, 10) (the, 8) (Ru, 5) (pal, 3) (it, 5) (like, 1) (name, 3) (too, 3) (food, 1) (dog, 1) Shuffle across worker nodes localSumRDD w/ four partitions Each partition has ‘n’ elements. globalSumRDD w/ three partitions 3
- 59. APACHE SPARK LIFE CYCLE (My, 1) (Pet, 1) (is, 10) (the, 8) (Ru, 5) (pal, 3) (it, 5) (like, 1) (name, 3) (too, 3) (food, 1) (dog, 1) counts.saveAsTextFile("hdfs://..."); Driver globalSumRDD w/ three partitions
- 60. APACHE SPARK LIFE CYCLE -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- Input/ base RDD flattened RDD mapPairs RDD localSum RDD globalSum RDD Driver Shuffle Unless an action is called upon RDDs will not get materialized Yasoda Jayaweera ([email protected])
- 61. APACHE SPARK LIFE CYCLE -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- Input/ base RDD flattened RDD mapPairs RDD localSum RDD globalSum RDD Driver Shuffle DAG (Directed Acyclic Graph) DAG is the list of instructions Yasoda Jayaweera ([email protected])
- 62. APACHE SPARK LIFE CYCLE Driver Call the Action – saveAsTextFile() Yasoda Jayaweera ([email protected])
- 63. APACHE SPARK LIFE CYCLE -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- Input/ base RDD Driver reads data from the text file Input/ base RDD is materialized and data is loaded into partitions Partitions of the RDD are distributed to worker nodes Yasoda Jayaweera ([email protected])
- 64. APACHE SPARK LIFE CYCLE -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- Input/ base RDD flattened RDD T1 Transformation 1 – flatMap(split()) Transformation is applied parallelly to data in each partition in the worker nodes Yasoda Jayaweera ([email protected])
- 65. APACHE SPARK LIFE CYCLE flattened RDD mapPairs RDD -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- Input/ base RDD T1 T2 Transformation 2 – mapToPair((word,1)) Transformation is applied parallelly to data in each partition in the worker nodes Yasoda Jayaweera ([email protected])
- 66. APACHE SPARK LIFE CYCLE -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- Input/ base RDD flattened RDD mapPairs RDD localSum RDD globalSum RDD T1 T2 T3 Shuffle reduceByKey () transformation Transformation 3 – reduceByKey() First the pairs are aggregated locally in the localSumRDD, Next the pairs are shuffled across the workers to get the global sum. globalSumRDD is created Yasoda Jayaweera ([email protected])
- 67. APACHE SPARK LIFE CYCLE -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- Input/ base RDD flattened RDD mapPairs RDD localSum RDD globalSum RDD Driver T1 T2 T3 Shuffle Data is save to a text file in the specified data storage A1 Yasoda Jayaweera ([email protected])
- 68. APACHE SPARK LIFE CYCLE -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- Input/ base RDD flattened RDD mapPairs RDD localSum RDD globalSum RDD Driver T1 T2 T3 Shuffle A1 As soon as the action is completed data is cleared from the RDDs No data in memory Yasoda Jayaweera ([email protected])
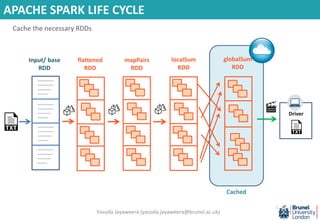
- 69. APACHE SPARK LIFE CYCLE -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- Input/ base RDD flattened RDD mapPairs RDD localSum RDD globalSum RDD DriverT1 T2 T3 Cached Cache the necessary RDDs A1 Yasoda Jayaweera ([email protected])
- 70. APACHE SPARK LIFE CYCLE Driver Cached globalSum RDD -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- -------------- -------------- ------------ --------- Input/ base RDD flattened RDD mapPairs RDD localSum RDD T1 T2 T3 A1 A2 Even after an action is completed the cached RDD will still be in the memory Other RDDs will be immaterialized/ cleared from memory Yasoda Jayaweera ([email protected])
- 71. - Until an action is called upon data Spark will not load the data into the memory (Spark lazy evaluation) - Actions trigger the data loading process - No data will be stored in the memory after an action - If you need to store the data it should be done by explicitly caching the data APACHE SPARK LIFE CYCLE Yasoda Jayaweera ([email protected])
- 72. DIFFERENT DATA REPRESENTATIONS IN SPARK RDD (Resilient Distributed Dataset) Dataframes - Allows you to use query language (SQL) to manipulate data - More like having your data in a table - Faster than RDDs Datasets Yasoda Jayaweera ([email protected])
- 73. WHY USERS OPT FOR SPARK?
- 74. WHY USERS OPT FOR SPARK? Speed Ease of use Generality Runs everywhere Community Yasoda Jayaweera ([email protected])
- 75. SPEED Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk - In-memory computing - DAG execution engine Yasoda Jayaweera ([email protected])
- 76. EASE OF USE Ability to write applications quickly in Java, Scala, Python, R Apache Spark Survey 2016 Report Yasoda Jayaweera ([email protected])
- 77. GENERALITY Spark is a unified system that combines SQL, streaming, and complex analytics Main functionalities - Scheduling : schedule computational tasks to run on a cluster - Monitoring : monitor the progress of the big data app - Distributing : distribute computational tasks across the cluster Yasoda Jayaweera ([email protected])
- 78. GENERALITY Pregel Large scale graph processing Tez Distributed processing with DAG Mahout Machine learning for Hadoop GraphLab Parallel algorithms in machine learning Impala Real time query engine for Hadoop Storm Real time distributed computation system Drill Open source SQL query engine for big data exploration Specialized systems for SQL, streaming and complex analytics Fragmented in product perspective and IT knowledge perspective! Yasoda Jayaweera ([email protected])
- 79. GENERALITY Fragmented in product perspective and IT knowledge perspective! - Specialized systems for Hadoop are distinct from one to another - If you learn one specialized system (for Hadoop MapReduce) that knowledge can’t be transferred to another product - You have to spend more time learning than analysing your data But Spark is a unified system that can easily connect with different systems Yasoda Jayaweera ([email protected])
- 80. RUNS EVERYWHERE Data Storage Applications Resource Managers/ https://databricks.com/blog/2016/01/05/apache-spark-2015-year-in-review.html Yasoda Jayaweera ([email protected])
- 81. GENERALITY “Two engineers who know Spark API can do what ten engineers could do in a distributed processing environment” Yasoda Jayaweera ([email protected])
- 82. COMMUNITY Rapidly growing community - New features - Product support Apache Spark Survey 2016 Report Yasoda Jayaweera ([email protected])
- 83. LIMITATIONS? Is memory a limitation for in-memory processing? Results of the 100TB Daytona sort benchmark 2014
- 84. LIMITATIONS? The results of the 100TB SORT benchmark in 2014 shows that memory is not a limitation Because Spark was able to sport 100TB data with only 6600 cores (virtualized – not physical) and 1PB of data with a lesser number of cores Spark is smart enough to manage the available memory regardless of the capacity of the data Yasoda Jayaweera ([email protected])
- 85. SUMMARY Spark is a unified system for processing large amounts of data Compared to Hadoop MapReduce Spark is - faster by keeping data in memory - easy to program Spark is ideal for - in – memory computation - real – time data processing Yasoda Jayaweera ([email protected])
- 86. MapReduce VS SPARK Spark is comparatively better than MapReduce This doesn’t mean MapReduce will be obsolete If you are selecting between MapReduce and Spark or considering about adopting Spark there is a lot to think about Yasoda Jayaweera ([email protected])
- 87. MapReduce VS SPARK Choosing/ changing an existing processing platform depends on a number of reasons Client requirements - will the client benefit from faster result? - Can Spark produce a significant change in the delivery time/ cost compared to MapReduce Existing internal capabilities and cost of changing the existing platforms - e.g. hardware, software, developers, company policy etc Types of problem you are trying to address - MapReduce is good for batch processing where as Spark is more suitable for real-time analytics or in-memory computations Future expansion plans for the company - will they move from batch processing to real-time analytics? New features which could be added to a product in the future Application dependency - Other applications that are connected to a specific product . If you change one platform will we have to change other dependant applications as well? And the cost incurred?
- 88. SPARK’S FASTEST GROWING AREAS Apache Spark Survey 2016 Report Yasoda Jayaweera ([email protected])
- 90. LEARNING MATERIAL Books Online courses - Spark official website - Databricks - Udemy - Coursera - Data Flair Spark London user group meetup (user groups in your country) Yasoda Jayaweera ([email protected])
- 91. FURTHER READING DAG (Directed Acyclic Graph) How Apache Spark works in Distributed Cluster Mode Spark context Different data representations: RDD, dataframes and datasets Transformations and actions Yasoda Jayaweera ([email protected])
- 93. REFERENCES Apache Spark for Beginners https://data-flair.training/blogs/apache-spark-for-beginners Introduction to Spark by Brian Clapper at 2015 Spark Summit https://www.youtube.com/watch?v=PFK6gsnlV5E RDDs, DataFrames and Datasets in Apache Spark by Brian Clapper in 2016 https://www.youtube.com/watch?v=pZQsDloGB4w Yasoda Jayaweera ([email protected])