Reproducible Science and Deep Software Variability
1 like380 views

The keynote discusses the challenges of achieving reproducible science in various domains due to deep software variability, where multiple factors including operating systems and libraries can lead to divergent results from the same data. It highlights the need for multidisciplinary collaboration and socio-technical innovations to address these challenges and improve scientific reproducibility. Furthermore, the document emphasizes the importance of understanding the interactions between software configurations and input data in computational science to ensure consistent results.













































![“Neuroimaging pipelines are known to generate different results
depending on the computing platform where they are compiled and
executed.” Significant differences were revealed between
FreeSurfer version v5.0.0 and the two earlier versions.
[...] About a factor two smaller differences were detected
between Macintosh and Hewlett-Packard workstations
and between OSX 10.5 and OSX 10.6. The observed
differences are similar in magnitude as effect sizes
reported in accuracy evaluations and neurodegenerative
studies.
see also Krefting, D., Scheel, M., Freing, A., Specovius, S., Paul, F., and
Brandt, A. (2011). “Reliability of quantitative neuroimage analysis using
freesurfer in distributed environments,” in MICCAI Workshop on
High-Performance and Distributed Computing for Medical Imaging.](https://image.slidesharecdn.com/vamoskeynotedeepvariabilityrescience-220301153546/85/Reproducible-Science-and-Deep-Software-Variability-46-320.jpg)

![“Neuroimaging pipelines are known to generate different results
depending on the computing platform where they are compiled and
executed.”
Statically building programs improves reproducibility across OSes, but small
differences may still remain when dynamic libraries are loaded by static
executables[...]. When static builds are not an option, software heterogeneity might
be addressed using virtual machines. However, such solutions are only
workarounds: differences may still arise between static executables built on
different OSes, or between dynamic executables executed in different VMs.
Reproducibility of neuroimaging
analyses across operating systems,
Glatard et al., Front. Neuroinform., 24
April 2015](https://image.slidesharecdn.com/vamoskeynotedeepvariabilityrescience-220301153546/85/Reproducible-Science-and-Deep-Software-Variability-48-320.jpg)



![Joelle Pineau “Building Reproducible, Reusable, and Robust Machine Learning Software” ICSE’19 keynote “[...] results
can be brittle to even minor perturbations in the domain or experimental procedure”
What is the magnitude of the effect
hyperparameter settings can have on baseline
performance?
How does the choice of network architecture for
the policy and value function approximation affect
performance?
How can the reward scale affect results?
Can random seeds drastically alter performance?
How do the environment properties affect
variability in reported RL algorithm performance?
Are commonly used baseline implementations
comparable?](https://image.slidesharecdn.com/vamoskeynotedeepvariabilityrescience-220301153546/85/Reproducible-Science-and-Deep-Software-Variability-52-320.jpg)

























![Applications of different analysis pipelines, alterations in software version, and even changes in operating
system have both shown to cause variation in the results of a neuroimaging study. Example:
Joelle Pineau “Building Reproducible, Reusable, and Robust Machine Learning Software” ICSE’19 keynote
“[...] results can be brittle to even minor perturbations in the domain or experimental procedure” Example:
DEEP SOFTWARE
VARIABILITY
DEEP SOFTWARE
VARIABILITY
Deep software variability is a threat to
scientific, software-based experiments
78](https://image.slidesharecdn.com/vamoskeynotedeepvariabilityrescience-220301153546/85/Reproducible-Science-and-Deep-Software-Variability-78-320.jpg)


![Reproducible Science and Deep Software Variability
REFERENCES
[1] 2021. Hail, software! Nature Computational Science 1, 2 (01
Feb 2021), 89–89. https://doi.org/10.1038/s43588-021-00037-8
[2] Marc Andreessen. 2011. Why software is eating the world.
Wall Street Journal 20, 2011 (2011), C2.
[3] Lorena A Barba. 2018. Terminologies for reproducible re-
search. arXiv preprint arXiv:1802.03311 (2018).
[4] Rotem Botvinik-Nezer, Felix Holzmeister, Colin F Camerer,
Anna Dreber, Juergen Huber, Magnus Johannesson, Michael
Kirchler, Roni Iwanir, Jeanette A Mumford, R Alison Adcock,
et al. 2020. Variability in the analysis of a single neuroimaging
dataset by many teams. Nature 582, 7810 (2020), 84–88.
[5] Xavier Bouthillier, César Laurent, and Pascal Vincent. 2019.
Unreproducible research is reproducible. In International Con-
ference on Machine Learning. PMLR, 725–734.
[6] Joshua Carp. 2012. On the plurality of (methodological) worlds:
estimating the analytic flexibility of FMRI experiments. Fron-
tiers in neuroscience 6 (2012), 149.
[7] Roberto Di Cosmo and Stefano Zacchiroli. 2017. Software
heritage: Why and how to preserve software source code. In
iPRES 2017-14th International Conference on Digital Preserva-
tion. 1–10.
[8] Steve M Easterbrook and Timothy C Johns. 2009. Engineering
the software for understanding climate change. Computing in
science & engineering 11, 6 (2009), 65–74.
[9] Tristan Glatard, Lindsay B Lewis, Rafael Ferreira da Silva, Reza
Adalat, Natacha Beck, Claude Lepage, Pierre Rioux, Marc-
Etienne Rousseau, Tarek Sherif, Ewa Deelman, et al. 2015.
Reproducibility of neuroimaging analyses across operating
systems. Frontiers in neuroinformatics 9 (2015), 12.
[10] Ed HBM Gronenschild, Petra Habets, Heidi IL Jacobs, Ron
Mengelers, Nico Rozendaal, Jim Van Os, and Machteld
Marcelis. 2012. The effects of FreeSurfer version, workstation
type, and Macintosh operating system version on anatomical
volume and cortical thickness measurements. PloS one 7, 6
(2012), e38234.
[11] Peter Henderson, Riashat Islam, Philip Bachman, Joelle Pineau,
Doina Precup, and David Meger. 2018. Deep reinforcement
learning that matters. In Proceedings of the AAAI Conference
on Artificial Intelligence, Vol. 32.
[12] Ruben Heradio, David Fernandez-Amoros, José A Galindo,
David Benavides, and Don Batory. 2022. Uniform and scalable
sampling of highly configurable systems. Empirical Software
Engineering 27, 2 (2022), 1–34.
[13] https://www.wcrp climate.org/. [n.d.]. World climat research
program (WCRP).
[14] Pooyan Jamshidi, Norbert Siegmund, Miguel Velez, Akshay
Patel, and Yuvraj Agarwal. 2017. Transfer Learning for Per-
formance Modeling of Configurable Systems: An Exploratory
Analysis. In IEEE/ACM International Conference on Automated
Software Engineering (ASE). IEEE Press, 497–508.
[15] Pooyan Jamshidi, Miguel Velez, Christian Kästner, and Nor-
bert Siegmund. 2018. Learning to Sample: Exploiting Similari-
ties Across Environments to Learn Performance Models for
Configurable Systems. In Proceedings of the 2018 26th ACM
Joint Meeting on European Software Engineering Conference
and Symposium on the Foundations of Software Engineering.
ACM, 71–82.
[16] Christian Kaltenecker, Alexander Grebhahn, Norbert Sieg-
mund, and Sven Apel. 2020. The Interplay of Sampling and
Machine Learning for Software Performance Prediction. IEEE
Softw. 37, 4 (2020), 58–66. https://doi.org/10.1109/MS.2020.
2987024
[17] Christopher G Knight, Sylvia HE Knight, Neil Massey, Tolu
Aina, Carl Christensen, Dave J Frame, Jamie A Kettleborough,
Andrew Martin, Stephen Pascoe, Ben Sanderson, et al. 2007.
Association of parameter, software, and hardware variation
with large-scale behavior across 57,000 climate models. Pro-
ceedings of the National Academy of Sciences 104, 30 (2007),
12259–12264.
[18] Dagmar Krefting, Michael Scheel, Alina Freing, Svenja Specov-
ius, Friedemann Paul, and Alexander Brandt. 2011. Relia-
bility of quantitative neuroimage analysis using freesurfer
in distributed environments. In MICCAI Workshop on High-
Performance and Distributed Computing for Medical Imag-
ing.(Toronto, ON).
[19] R. Krishna, V. Nair, P. Jamshidi, and T. Menzies. 2020. Whence
to Learn? Transferring Knowledge in Configurable Systems
using BEETLE. IEEE Transactions on Software Engineering
(2020), 1–1.
[20] Dorian Leroy, June Sallou, Johann Bourcier, and Benoit Combe-
male. 2021. When Scientific Software Meets Software En-
gineering. Computer (2021), 1–11. https://hal.inria.fr/hal-
03318348
[21] Luc Lesoil, Mathieu Acher, Arnaud Blouin, and Jean-Marc
Jézéquel. 2021. The Interaction between Inputs and Config-
urations fed to Software Systems: an Empirical Study. CoRR
abs/2112.07279 (2021). arXiv:2112.07279 https://arxiv.org/abs/
2112.07279
[22] Luc Lesoil, Mathieu Acher, Arnaud Blouin, and Jean-Marc
Jézéquel. 2021. Deep Software Variability: Towards Han-
dling Cross-Layer Configuration. In VaMoS 2021 - 15th In-
ternational Working Conference on Variability Modelling of
Software-Intensive Systems. Krems / Virtual, Austria, 1–8.
https://hal.inria.fr/hal-03084276
[23] Luc Lesoil, Mathieu Acher, Xhevahire Tërnava, Arnaud Blouin,
and Jean-Marc Jézéquel. 2021. The Interplay of Compile-time
and Run-time Options for Performance Prediction. In SPLC
2021 - 25th ACM International Systems and Software Product
Line Conference - Volume A. ACM, Leicester, United Kingdom,
1–12. https://doi.org/10.1145/3461001.3471149
[24] Luc Lesoil, Hugo Martin, Mathieu Acher, Arnaud Blouin, and
Jean-Marc Jézéquel. 2022. Transferring Performance between
Distinct Configurable Systems : A Case Study. In VaMoS ’22:
16th International Working Conference on Variability Modelling
of Software-Intensive Systems, Florence, Italy, February 23 -
25, 2022, Paolo Arcaini, Xavier Devroey, and Alessandro Fan-
techi (Eds.). ACM, 10:1–10:6. https://doi.org/10.1145/3510466.
3510486
[25] Hugo Martin, Mathieu Acher, Juliana Alves Pereira, Luc Lesoil,
Jean-Marc Jézéquel, and Djamel Eddine Khelladi. 2021. Trans-
fer Learning Across Variants and Versions: The Case of Linux
Kernel Size. IEEE Transactions on Software Engineering (2021),](https://image.slidesharecdn.com/vamoskeynotedeepvariabilityrescience-220301153546/85/Reproducible-Science-and-Deep-Software-Variability-82-320.jpg)
![Mathieu Acher
1–17. https://hal.inria.fr/hal-03358817
[26] François Massonnet, Martin Ménégoz, Mario Acosta, Xavier
Yepes-Arbós, Eleftheria Exarchou, and Francisco J Doblas-
Reyes. 2020. Replicability of the EC-Earth3 Earth system
model under a change in computing environment. Geoscien-
tific Model Development 13, 3 (2020), 1165–1178.
[27] Olivier Mesnard and Lorena A Barba. 2017. Reproducible and
replicable computational fluid dynamics: it’s harder than you
think. Computing in Science & Engineering 19, 4 (2017), 44–55.
[28] S. Mühlbauer, S. Apel, and N. Siegmund. 2020. Identifying
Software Performance Changes Across Variants and Versions.
In 2020 35th IEEE/ACM International Conference on Automated
Software Engineering (ASE). 611–622.
[29] Juliana Alves Pereira, Mathieu Acher, Hugo Martin, and Jean-
Marc Jézéquel. 2020. Sampling Effect on Performance Pre-
diction of Configurable Systems: A Case Study. In ICPE ’20:
ACM/SPEC International Conference on Performance Engineer-
ing, Edmonton, AB, Canada, April 20-24, 2020, José Nelson Ama-
ral, Anne Koziolek, Catia Trubiani, and Alexandru Iosup (Eds.).
ACM, 277–288. https://doi.org/10.1145/3358960.3379137
[30] Juliana Alves Pereira, Mathieu Acher, Hugo Martin, Jean-
Marc Jézéquel, Goetz Botterweck, and Anthony Ventresque.
2021. Learning software configuration spaces: A system-
atic literature review. J. Syst. Softw. 182 (2021), 111044.
https://doi.org/10.1016/j.jss.2021.111044
[31] Quentin Plazar, Mathieu Acher, Gilles Perrouin, Xavier De-
vroey, and Maxime Cordy. 2019. Uniform Sampling of SAT
Solutions for Configurable Systems: Are We There Yet?. In
12th IEEE Conference on Software Testing, Validation and Verifi-
cation, ICST 2019, Xi’an, China, April 22-27, 2019. IEEE, 240–251.
https://doi.org/10.1109/ICST.2019.00032
[32] Georges Aaron Randrianaina, Djamel Eddine Khelladi, Olivier
Zendra, and Mathieu Acher. 2022. Towards Incremental
Build of Software Configurations. In ICSE-NIER 2022 - 44th
International Conference on Software Engineering – New Ideas
and Emerging Results. Pittsburgh, PA, United States, 1–5.
https://doi.org/10.1145/3510455.3512792
[33] Georges Aaron Randrianaina, Xhevahire Tërnava, Djamel Ed-
dine Khelladi, and Mathieu Acher. 2022. On the Benefits and
Limits of Incremental Build of Software Configurations: An
Exploratory Study. In ICSE 2022 - 44th International Confer-
ence on Software Engineering. Pittsburgh, Pennsylvania / Vir-
tual, United States, 1–12. https://hal.archives-ouvertes.fr/hal-
03547219
[34] Nicolas P. Rougier and Konrad Hinsen. 2019. ReScience C: A
Journal for Reproducible Replications in Computational Sci-
ence. In Reproducible Research in Pattern Recognition, Bertrand
Kerautret, Miguel Colom, Daniel Lopresti, Pascal Monasse,
and Hugues Talbot (Eds.). Springer International Publishing,
Cham, 150–156.
[35] Nicolas P. Rougier, Konrad Hinsen, Frédéric Alexandre,
Thomas Arildsen, Lorena Barba, Fabien C. Y. Benureau, C. Ti-
tus Brown, Pierre De Buyl, Ozan Caglayan, Andrew P. Davi-
son, Marc André Delsuc, Georgios Detorakis, Alexandra K.
Diem, Damien Drix, Pierre Enel, Benoît Girard, Olivia Guest,
Matt G. Hall, Rafael Neto Henriques, Xavier Hinaut, Kamil S
Jaron, Mehdi Khamassi, Almar Klein, Tiina Manninen, Pietro
Marchesi, Dan McGlinn, Christoph Metzner, Owen L. Petchey,
Hans Ekkehard Plesser, Timothée Poisot, Karthik Ram, Yoav
Ram, Etienne Roesch, Cyrille Rossant, Vahid Rostami, Aaron
Shifman, Joseph Stachelek, Marcel Stimberg, Frank Stollmeier,
Federico Vaggi, Guillaume Viejo, Julien Vitay, Anya Vostinar,
Roman Yurchak, and Tiziano Zito. 2017. Sustainable computa-
tional science: the ReScience initiative. PeerJ Computer Science
3 (Dec. 2017), e142. https://doi.org/10.7717/peerj-cs.142 8
pages, 1 figure.
[36] Mohammed Sayagh, Noureddine Kerzazi, Bram Adams, and
Fabio Petrillo. 2018. Software Configuration Engineering in
Practice: Interviews, Survey, and Systematic Literature Review.
IEEE Transactions on Software Engineering (2018).
[37] Raphael Silberzahn, Eric L Uhlmann, Daniel P Martin,
Pasquale Anselmi, Frederik Aust, Eli Awtrey, Štěpán Bahník,
Feng Bai, Colin Bannard, Evelina Bonnier, et al. 2018. Many
analysts, one data set: Making transparent how variations
in analytic choices affect results. Advances in Methods and
Practices in Psychological Science 1, 3 (2018), 337–356.
[38] Sara Steegen, Francis Tuerlinckx, Andrew Gelman, and Wolf
Vanpaemel. 2016. Increasing transparency through a mul-
tiverse analysis. Perspectives on Psychological Science 11, 5
(2016), 702–712.
[39] Pavel Valov, Jean-Christophe Petkovich, Jianmei Guo, Sebas-
tian Fischmeister, and Krzysztof Czarnecki. 2017. Transferring
Performance Prediction Models Across Different Hardware
Platforms. In Proceedings of the 8th ACM/SPEC on International
Conference on Performance Engineering, ICPE 2017, L’Aquila,
Italy, April 22-26, 2017. 39–50. https://doi.org/10.1145/3030207.
3030216
[40] Mahsa Varshosaz, Mustafa Al-Hajjaji, Thomas Thüm, Tobias
Runge, Mohammad Reza Mousavi, and Ina Schaefer. 2018. A
classification of product sampling for software product lines.
In Proceeedings of the 22nd International Conference on Systems
and Software Product Line - Volume 1, SPLC 2018, Gothenburg,
Sweden, September 10-14, 2018. 1–13. https://doi.org/10.1145/
3233027.3233035
[41] Max Weber, Sven Apel, and Norbert Siegmund. 2021. White-
Box Performance-Influence models: A profiling and learning
approach. In 2021 IEEE/ACM 43rd International Conference on
Software Engineering (ICSE). IEEE, 1059–1071.
[42] Greg Wilson, Dhavide A Aruliah, C Titus Brown, Neil P Chue
Hong, Matt Davis, Richard T Guy, Steven HD Haddock,
Kathryn D Huff, Ian M Mitchell, Mark D Plumbley, et al. 2014.
Best practices for scientific computing. PLoS biology 12, 1
(2014), e1001745.](https://image.slidesharecdn.com/vamoskeynotedeepvariabilityrescience-220301153546/85/Reproducible-Science-and-Deep-Software-Variability-83-320.jpg)
Reproducible Science and Deep Software Variability
- 1. Reproducible Science and Deep Software Variability Mathieu Acher @acherm Special thanks to Luc Lesoil, Jean-Marc Jézéquel, Arnaud Blouin, and Benoit Combemale
- 2. VaMoS keynote, 24 february 2022 https://hal.inria.fr/hal-03528889 Abstract : Biology, medicine, physics, astrophysics, chemistry: all these scientific domains need to process large amount of data with more and more complex software systems. For achieving reproducible science, there are several challenges ahead involving multidisciplinary collaboration and socio-technical innovation with software at the center of the problem. Despite the availability of data and code, several studies report that the same data analyzed with different software can lead to different results. I am seeing this problem as a manifestation of deep software variability: many factors (operating system, third-party libraries, versions, workloads, compile-time options and flags, etc.) themselves subject to variability can alter the results, up to the point it can dramatically change the conclusions of some scientific studies. In this keynote, I argue that deep software variability is a threat and also an opportunity for reproducible science. I first outline some works about (deep) software variability, reporting on preliminary evidence of complex interactions between variability layers. I then link the ongoing works on variability modelling and deep software variability in the quest for reproducible science. References at the ~end of the slides!
- 3. Reproducible Science and (Deep) Software (Variability) Deep Software Variability Evidence of Deep Software Variability in Science Threats and Opportunities AGENDA
- 4. SOFTWARE VARIANTS ARE EATING THE WORLD 4
- 5. SOFTWARE IS EATING SCIENCE 5
- 6. Computational science depends on software and its engineering 6 design of mathematical model mining and analysis of data executions of large simulations problem solving executable paper from a set of scripts to automate the deployment to… a comprehensive system containing several features that help researchers exploring various hypotheses
- 7. Computational science depends on software and its engineering 7 from a set of scripts to automate the deployment to… a comprehensive system containing several features that help researchers exploring various hypotheses multi-million line of code base multi-dependencies multi-systems multi-layer multi-version multi-person multi-variant
- 8. Computational science depends on software and its engineering 8 Dealing with software collapse: software stops working eventually Konrad Hinsen 2019 Configuration failures represent one of the most common types of software failures Sayagh et al. TSE 2018 multi-million line of code base multi-dependencies multi-systems multi-layer multi-version multi-person multi-variant
- 9. “Insanity is doing the same thing over and over again and expecting different results” 9 http://throwgrammarfromthetrain.blogspot.com/2010/10/definition-of-insanity.html
- 10. Reproducibility 10 “Authors provide all the necessary data and the computer codes to run the analysis again, re-creating the results.” (Claerbout/Donoho/Peng definition) “The actual scholarship is the complete software development environment and the complete set of instructions which generated the figures.” (~executable paper)
- 11. Reproducibility and Replicability 11 Reproducible: Authors provide all the necessary data and the computer codes to run the analysis again, re-creating the results. Replication: A study that arrives at the same scientific findings as another study, collecting new data (possibly with different methods) and completing new analyses. “Terminologies for Reproducible Research”, Lorena A. Barba, 2018
- 12. Reproducibility and Replicability 12 Reproducible: Authors provide all the necessary data and the computer codes to run the analysis again, re-creating the results. Replication: A study that arrives at the same scientific findings as another study, collecting new data (possibly with different methods) and completing new analyses. “Terminologies for Reproducible Research”, Lorena A. Barba, 2018
- 13. Reproducibility and Replicability 13 Methods Reproducibility: A method is reproducible if reusing the original code leads to the same results. Results Reproducibility: A result is reproducible if a reimplementation of the method generates statistically similar values. Inferential Reproducibility: A finding or a conclusion is reproducible if one can draw it from a different experimental setup. “Unreproducible Research is Reproducible”, Bouthillier et al., ICML 2019
- 14. Reproducible science 14 “Authors provide all the necessary data and the computer codes to run the analysis again, re-creating the results.” Socio-technical issues: open science, open source software, multi-disciplinary collaboration, incentives/rewards, initiatives, etc. with many challenges related to data acquisition, knowledge organization/sharing, etc.
- 15. Reproducible science 15 “Authors provide all the necessary data and the computer codes to run the analysis again, re-creating the results.” Socio-technical issues: open science, open source software, multi-disciplinary collaboration, incentives/rewards, initiatives, etc. with many challenges related to data acquisition, knowledge organization/sharing, etc. https://github.com/emsejournal/openscience https://rescience.github.io/ https://reproducible-research.inria.fr/
- 16. Reproducible science 16 “Authors provide all the necessary data and the computer codes to run the analysis again, re-creating the results.” Socio-technical issues: open science, open source software, multi-disciplinary collaboration, incentives/rewards, initiatives, etc. with many challenges related to data acquisition, knowledge organization/sharing, etc.
- 17. Reproducible science 17 “Authors provide all the necessary data and the computer codes to run the analysis again, re-creating the results.” Despite the availability of data and code, several studies report that the same data analyzed with different software can lead to different results. from a set of scripts to automate the deployment to… a comprehensive system containing several features that help researchers exploring various hypotheses
- 18. 18 Despite the availability of data and code, several studies report that the same data analyzed with different software can lead to different results Many layers (operating system, third-party libraries, versions, workloads, compile-time options and flags, etc.) themselves subject to variability can alter the results. Reproducible science and deep software variability: a threat and opportunity for scientific knowledge! hardware variability operating system variability compiler variability build variability hypervisor variability software application variability v e r s i o n v a r i a b i l i t y input data variability container variability deep software variability
- 19. Reproducible Science and (Deep) Software (Variability) Deep Software Variability Evidence of Deep Software Variability in Science Threats and Opportunities AGENDA
- 20. 15,000+ options thousands of compiler flags and compile-time options dozens of preferences 100+ command-line parameters 1000+ feature toggles 20 hardware variability deep software variability
- 21. Deep software variability: does it matter? i.e. Are layers/features orthogonal or are there interactions? Luc Lesoil, Mathieu Acher, Arnaud Blouin, Jean-Marc Jézéquel: Deep Software Variability: Towards Handling Cross-Layer Configuration.
- 22. Configuration is hard: numerous options, informal knowledge ?????
- 23. Hardware Operating System Software Input Data 10.4 x264 --mbtree ... x264 --no-mbtree ... x264 --no-mbtree ... x264 --mbtree ... 20.04 Dell latitude 7400 Raspberry Pi 4 model B vertical animation vertical animation vertical animation vertical animation Duration (s) 22 25 73 72 6 6 351 359 Size (MB) 28 34 33 21 33 21 28 34 A B 2 1 2 1 REAL WORLD Example (x264)
- 24. REAL WORLD Example (x264) Hardware Operating System Software Input Data 10.4 x264 --mbtree ... x264 --no-mbtree ... x264 --no-mbtree ... x264 --mbtree ... 20.04 Dell latitude 7400 Raspberry Pi 4 model B vertical animation vertical animation vertical animation vertical animation Duration (s) 22 25 73 72 6 6 351 359 Size (MB) 28 34 33 21 33 21 28 34 A B 2 1 2 1
- 25. Hardware Operating System Software Input Data 10.4 x264 --mbtree ... x264 --no-mbtree ... x264 --no-mbtree ... x264 --mbtree ... 20.04 Dell latitude 7400 Raspberry Pi 4 model B vertical animation vertical animation vertical animation vertical animation Duration (s) 22 25 73 72 6 6 351 359 Size (MB) 28 34 33 21 33 21 28 34 A B 2 1 2 1 ≈*16 ≈*12 REAL WORLD Example (x264)
- 26. Age # Cores GPU SOFTWARE Variant Compil. Version Version Option Distrib. Size Length Res. Hardware Operating System Software Input Data Bug Perf. ↗ Perf. ↘ deep variability L. Lesoil, M. Acher, A. Blouin and J.-M. Jézéquel, “Deep Software Variability: Towards Handling Cross-Layer Configuration” in VaMoS 2021 The “best”/default software variant might be a bad one. Influential software options and their interactions vary. Performance prediction models and variability knowledge may not generalize
- 27. Transferring Performance Prediction Models Across Different Hardware Platforms Valov et al. ICPE 2017 “Linear model provides a good approximation of transformation between performance distributions of a system deployed in different hardware environments” what about variability of input data? compile-time options? version?
- 28. Transfer Learning for Software Performance Analysis: An Exploratory Analysis Jamshidi et al. ASE 2017
- 29. mixing deep variability: hard to assess the specific influence of each layer very few hardware, version, and input data… but lots of runtime configurations (variants) Let’s go deep with input data! Transfer Learning for Software Performance Analysis: An Exploratory Analysis Jamshidi et al. ASE 2017
- 30. Let’s go deep with input data! Intuition: video encoder behavior (and thus runtime configurations) hugely depends on the input video (different compression ratio, encoding size/type etc.) Is the best software configuration still the best? Are influential options always influential? Does the configuration knowledge generalize? ? YouTube User General Content dataset: 1397 videos Measurements of 201 soft. configurations (with same hardware, compiler, version, etc.): encoding time, bitrate, etc.
- 31. Do x264 software performances stay consistent across inputs? ●Encoding time: very strong correlations ○ low input sensitivity ●FPS: very strong correlations ○ low input sensitivity ●CPU usage : moderate correlation, a few negative correlations ○ medium input sensitivity ●Bitrate: medium-low correlation, many negative correlations ○ High input sensitivity ●Encoding size: medium-low correlation, many negative correlations ○ High input sensitivity ? 1397 videos x 201 software configurations
- 32. Are there some configuration options more sensitive to input videos? (bitrate)
- 33. Are there some configuration options more sensitive to input videos? (bitrate)
- 34. Threats to variability knowledge for performance property bitrate ● optimal configuration is specific to an input; a good configuration can be a bad one ● some options’ values have an opposite effect depending on the input ● effectiveness of sampling strategies (random, 2-wise, etc.) is input specific (somehow confirming Pereira et al. ICPE 2020) ● predicting, tuning, or understanding configurable systems without being aware of inputs can be inaccurate and… pointless Practical impacts for users, developers, scientists, and self-adaptive systems
- 35. Practical impacts for users, developers, scientists, and self-adaptive systems Threats to variability knowledge: predicting, tuning, or understanding configurable systems without being aware of inputs can be inaccurate and… pointless Opportunities: for some performance properties (P) and subject systems, some stability is observed and performance remains consistent! L. Lesoil, M. Acher, A. Blouin and J.-M. Jézéquel “The Interaction between Inputs and Configurations fed to Software Systems: an Empirical Study” https://arxiv.org/abs/2112.07279
- 36. x264 video encoder (compilation/build) compile-time options
- 37. Is there an interplay between compile-time and runtime options? L. Lesoil, M. Acher, X. Tërnava, A. Blouin and J.-M. Jézéquel “The Interplay of Compile- time and Run-time Options for Performance Prediction” in SPLC ’21
- 38. Key results (for x264) Worth tuning software at compile-time: gain about 10 % of execution time with the tuning of compile-time options (compared to the default compile-time configuration). The improvements can be larger for some inputs and some runtime configurations. Stability of variability knowledge: For all the execution time distributions of x264 and all the input videos, the worst correlation is greater than 0.97. If the compile-time options change the scale of the distribution, they do not change the rankings of run-time configurations (i.e., they do not truly interact with the run-time options). Reuse of configuration knowledge: ● Linear transformation among distributions ● Users can also trust the documentation of run-time options, consistent whatever the compile-time configuration is. L. Lesoil, M. Acher, X. Tërnava, A. Blouin and J.-M. Jézéquel “The Interplay of Compile- time and Run-time Options for Performance Prediction” in SPLC ’21
- 39. Key results (for x264) First good news: Worth tuning software at compile-time! Second good news: For all the execution time distributions of x264 and all the input videos, the worst correlation is greater than 0.97. If the compile-time options change the scale of the distribution, they do not change the rankings of run-time configurations (i.e., they do not truly interact with the run-time options). It has three practical implications: 1. Reuse of configuration knowledge: transfer learning of prediction models boils down to apply a linear transformation among distributions. Users can also trust the documentation of run-time options, consistent whatever the compile-time configuration is. 2. Tuning at lower cost: finding the best compile-time configuration among all the possible ones allows one to immediately find the best configuration at run time. We can remove away one dimension! 3. Measuring at lower cost: do not use a default compile-time configuration, use the less costly once since it will generalize! Did we recommend to use two binaries? YES, one for measuring, another for reaching optimal performances! interplay between compile-time and runtime options and even input! L. Lesoil, M. Acher, X. Tërnava, A. Blouin and J.-M. Jézéquel “The Interplay of Compile- time and Run-time Options for Performance Prediction” in SPLC ’21
- 40. ● Linux as a subject software system (not as an OS interacting with other layers) ● Targeted non-functional, quantitative property: binary size ○ interest for maintainers/users of the Linux kernel (embedded systems, cloud, etc.) ○ challenging to predict (cross-cutting options, interplay with compilers/build systems, etc/.) ● Dataset: version 4.13.3 (september 2017), x86_64 arch, measurements of 95K+ random configurations ○ paranoiac about deep variability since 2017, Docker to control the build environment and scale ○ diversity of binary sizes: from 7Mb to 1.9Gb ○ 6% MAPE errors: quite good, though costly… 2 40 H. Martin, M. Acher, J. A. Pereira, L. Lesoil, J. Jézéquel and D. E. Khelladi, “Transfer learning across variants and versions: The case of linux kernel size” Transactions on Software Engineering (TSE), 2021
- 41. 4.13 version (sep 2017): 6%. What about evolution? Can we reuse the 4.13 Linux prediction model? No, accuracy quickly decreases: 4.15 (5 months after): 20%; 5.7 (3 years after): 35% 3 41
- 42. Transfer learning to the rescue ● Mission Impossible: Saving variability knowledge and prediction model 4.13 (15K hours of computation) ● Heterogeneous transfer learning: the feature space is different ● TEAMS: transfer evolution-aware model shifting 5 42 H. Martin, M. Acher, J. A. Pereira, L. Lesoil, J. Jézéquel and D. E. Khelladi, “Transfer learning across variants and versions: The case of linux kernel size” Transactions on Software Engineering (TSE), 2021 3 42
- 43. Age # Cores GPU SOFTWARE Variant Compil. Version Version Option Distrib. Size Length Res. Hardware Operating System Software Input Data Bug Perf. ↗ Perf. ↘ deep variability Sometimes, variability is consistent/stable and knowledge transfer is immediate. But there are also interactions among variability layers and variability knowledge may not generalize
- 44. Reproducible Science and (Deep) Software (Variability) Deep Software Variability Evidence of Deep Software Variability in Computational Science Threats and Opportunities AGENDA
- 45. It’s all about software… Where is (computational) science? 45 from a set of scripts to automate the deployment to… a comprehensive system containing several features that help researchers exploring various hypotheses
- 46. “Neuroimaging pipelines are known to generate different results depending on the computing platform where they are compiled and executed.” Significant differences were revealed between FreeSurfer version v5.0.0 and the two earlier versions. [...] About a factor two smaller differences were detected between Macintosh and Hewlett-Packard workstations and between OSX 10.5 and OSX 10.6. The observed differences are similar in magnitude as effect sizes reported in accuracy evaluations and neurodegenerative studies. see also Krefting, D., Scheel, M., Freing, A., Specovius, S., Paul, F., and Brandt, A. (2011). “Reliability of quantitative neuroimage analysis using freesurfer in distributed environments,” in MICCAI Workshop on High-Performance and Distributed Computing for Medical Imaging.
- 47. “Neuroimaging pipelines are known to generate different results depending on the computing platform where they are compiled and executed.” Reproducibility of neuroimaging analyses across operating systems, Glatard et al., Front. Neuroinform., 24 April 2015 The implementation of mathematical functions manipulating single-precision floating-point numbers in libmath has evolved during the last years, leading to numerical differences in computational results. While these differences have little or no impact on simple analysis pipelines such as brain extraction and cortical tissue classification, their accumulation creates important differences in longer pipelines such as the subcortical tissue classification, RSfMRI analysis, and cortical thickness extraction.
- 48. “Neuroimaging pipelines are known to generate different results depending on the computing platform where they are compiled and executed.” Statically building programs improves reproducibility across OSes, but small differences may still remain when dynamic libraries are loaded by static executables[...]. When static builds are not an option, software heterogeneity might be addressed using virtual machines. However, such solutions are only workarounds: differences may still arise between static executables built on different OSes, or between dynamic executables executed in different VMs. Reproducibility of neuroimaging analyses across operating systems, Glatard et al., Front. Neuroinform., 24 April 2015
- 49. We demonstrate that effects of parameter, hardware, and software variation are detectable, complex, and interacting. However, we find most of the effects of parameter variation are caused by a small subset of parameters. Notably, the entrainment coefficient in clouds is associated with 30% of the variation seen in climate sensitivity, although both low and high values can give high climate sensitivity. We demonstrate that the effect of hardware and software is small relative to the effect of parameter variation and, over the wide range of systems tested, may be treated as equivalent to that caused by changes in initial conditions. 57,067 climate model runs. These runs sample parameter space for 10 parameters with between two and four levels of each, covering 12,487 parameter combinations (24% of possible combinations) and a range of initial conditions
- 50. Can a coupled ESM simulation be restarted from a different machine without causing climate-changing modifications in the results? Using two versions of EC-Earth: one “non-replicable” case (see below) and one replicable case.
- 51. Can a coupled ESM simulation be restarted from a different machine without causing climate-changing modifications in the results? A study involving eight institutions and seven different supercomputers in Europe is currently ongoing with EC-Earth. This ongoing study aims to do the following: ● evaluate different computational environments that are used in collaboration to produce CMIP6 experiments (can we safely create large ensembles composed of subsets that emanate from different partners of the consortium?); ● detect if the same CMIP6 configuration is replicable among platforms of the EC-Earth consortium (that is, can we safely exchange restarts with EC-Earth partners in order to initialize simulations and to avoid long spin-ups?); and ● systematically evaluate the impact of different compilation flag options (that is, what is the highest acceptable level of optimization that will not break the replicability of EC-Earth for a given environment?).
- 52. Joelle Pineau “Building Reproducible, Reusable, and Robust Machine Learning Software” ICSE’19 keynote “[...] results can be brittle to even minor perturbations in the domain or experimental procedure” What is the magnitude of the effect hyperparameter settings can have on baseline performance? How does the choice of network architecture for the policy and value function approximation affect performance? How can the reward scale affect results? Can random seeds drastically alter performance? How do the environment properties affect variability in reported RL algorithm performance? Are commonly used baseline implementations comparable?
- 53. “Completing a full replication study of our previously published findings on bluff-body aerodynamics was harder than we thought. Despite the fact that we have good reproducible-research practices, sharing our code and data openly.”
- 54. Reproducible Science and (Deep) Software (Variability) Deep Software Variability Evidence of Deep Software Variability in Computational Science Threats and Opportunities AGENDA
- 55. (computational) science 55 from a set of scripts to automate the deployment to… a comprehensive system containing several features that help researchers exploring various hypotheses Deep software variability is a threat to scientific, software-based experiments
- 56. Age # Cores GPU Compil. Version Version Option Distrib. Size Length Res. Hardware Operating System Software Input Data Does deep software variability affect previous scientific, software-based studies? (a graphical template) List all details… and questions: what iF we run the experiments on different: OS? version/commit? PARAMETERS? INPUT? SOFTWARE Variant
- 57. What can we do? (#1 studies) Empirical studies about deep software variability ● more subject systems ● more variability layers, including interactions ● more quantitative (e.g., performance) properties with challenges for gathering measurements data: ● how to scale experiments? Variant space is huge! ● how to fix/isolate some layers? (eg hardware) ● how to measure in a reliable way? Expected outcomes: ● significance of deep software variability in the wild ● identification of stable layers: sources of variability that should not affect the conclusion and that can be eliminated/forgotten ● identification/quantification of sensitive layers and interactions that matter ● variability knowledge
- 58. What can we do? (#2 cost) Reducing the cost of exploring the variability spaces Many directions here (references at the end of the slides): ● learning ○ many algorithms/techniques with tradeoffs interpretability/accuracy ○ transfer learning (instead of learning from scratch) ● sampling strategies ○ uniform random sampling? t-wise? distance-based? … ○ sample of hardware? input data? ● incremental build of configurations ● white-box approaches ● …
- 59. What can we do? (#3 modelling) Modelling variability ● Abstractions are definitely needed to… ○ reason about logical constraints and interactions ○ integrate domain knowledge ○ synthesize domain knowledge ○ automate and guide the exploration of variants ○ scope and prioritize experiments ● Challenges: ○ Multiple systems, layers, concerns ○ Different kinds of variability: technical vs domain, accidental vs essential, implicit vs explicit… when to stop modelling? ○ reverse engineering
- 60. What can we do? (#4 robustness) Robustness (trustworthiness) of scientific results to sources of variability I have shown many examples of sources of variations and non-robust results… Robustness should be rigorously defined (hint: it’s not the definition as given in computer science) How to verify the effect of sources of variations on the robustness of given conclusions? ● actionable metrics? ● methodology? (eg when to stop?) ● variability can actually be leveraged to augment confidence
- 61. (computational) science 61 from a set of scripts to automate the deployment to… a comprehensive system containing several features that help researchers exploring various hypotheses Deep software variability is an opportunity to robustify and augment scientific knowledge
- 62. 62 deep software variability different methods different assumptions different analyses different data
- 63. 63 deep software variability “When you are a researcher, you want to be the first. Research is about discovery, inventing things that others have not done. It is by definition a form of competition. You have to accept that.” CNRS CEO At a time of global pandemics, global warming and unprecedented public distrust of politics and democracy, research is anything but an individualistic competition. Above all, let us value the need for reproducibility in research. Let us prefer the "discovery" that will be verified or even falsified and encourage collaboration. Deeply exploring the variability space cannot be done alone. Collaborative, distributed effort needed.
- 64. 64 deep software variability Are we in ivory towers? I mean: We’re studying software… for the sake of improving software engineering (and it’s nice!). But should we stay? (computational) science
- 65. 65 Deep software variability is… a threat for reproducible research “Authors provide all the necessary data and the computer codes to run the analysis again, re-creating the results.” an opportunity for replication “A study that arrives at the same scientific findings as another study, collecting new data (possibly with different methods) and completing new analyses.” “A study that refutes some scientific findings of another study, through the collection of new data (possibly with different methods) and completion of new analyses.” robustifying and augmenting scientific knowledge
- 66. Reproducible Science and Deep Software Variability
- 67. BACKUP SLIDES
- 68. (BEYOND x264) Empirical and fundamental question HOW DOES DEEP SOFTWARE VARIABILITY MANIFEST IN THE WILD? SOFTWARE SCIENTISTS should OBSERVE the JUNGLE/ GALAXY! Age # Cores GPU Variant Compil. Version Version Option Distrib. Size Length Res. Hardware Operating System Software Input Data
- 69. Deep Software Variability 4 challenges and opportunities Luc Lesoil, Mathieu Acher, Arnaud Blouin, Jean-Marc Jézéquel: Deep Software Variability: Towards Handling Cross-Layer Configuration. VaMoS 2021: 10:1-10:8
- 70. Identify the influential layers 1 Age # Cores GPU Variant Compil. Version Version Option Distrib. Size Length Res. Hardware Operating System Software Input Data Problem ≠ layers, ≠ importances on performances Challenge Estimate their effects Opportunity Leverage the useful variability layers & variables
- 71. 2 Test & Benchmark environments 0.152.2854 0.155.2917 Problem Combinatorial explosion and cost Challenge Build a representative, cheap set of environments Opportunity dimensionality reduction Hardware Operating System Software Input Data
- 72. Transfer performances across environments 10.4 20.04 Dell latitude 7400 Raspberry Pi 4 model B A B ? Problem Options’ importances change with environments Challenge Transfer performances across environments Opportunity Reduce cost of measure 3
- 73. Cross-Layer Tuning Age # Cores GPU Variant Compil. Version Version Option Distrib. Size Length Res. Hardware Operating System Software Input Data 4 Problem (Negative) interactions of layers Challenge Find & fix values to improve performances Opportunity Specialize the environment for a use case Bug Perf. ↗ Perf. ↘
- 74. CHALLENGES for Deep Software Variability Identify the influential layers Test & Benchmark environments Transfer performances across environments Cross-Layer Tuning
- 75. Wrap-up Deep software variability is a thing… miracle and smooth fit of variability layers? or subtle interactions among layers? software scientists should systematically study the phenomenon Many challenges and opportunities cross-layer tuning at affordable cost configuration knowledge that generalizes to any context and usage Dimensionality reduction and transfer learning
- 76. Impacts of deep software variability Users/developers/scientists: missed opportunities due to (accidental) variability/complexity Deep software variability can be seen as a threat to knowledge/validity Claim: Deep software variability is a threat to scientific, software-based experiments Example #1: in the results of neuroimaging studies ● applications of different analysis pipelines (Krefting et al. 2011) ● alterations in software version (Glatard et al. 2015) ● changes in operating system (Gronenschild2012 et al.) have both shown to cause variation (up to the point it can change the conclusions). Example #2: on a modest scale, our ICPE 2020 (Pereira et al.) showed that a variation in inputs could change the conclusion about the effectiveness of a sampling strategy for the same software system. Example #3: I’m reading Zakaria Ournani et al. “Taming Energy Consumption Variations In Systems Benchmarking” ICPE 2020 as an excellent inquiry to control deep variability factors Example #4: Similar observations have been made in the machine learning community (Henderson et al. 2018) version runtime options OS
- 77. Impacts of deep software variability Users/developers/scientists: missed opportunities due to (accidental) complexity Deep software variability can be seen as a threat to knowledge/validity Claim: Deep software variability is a threat to scientific, software-based experiments I propose an exercise that might be slightly disturbing: Does deep software variability affect (your|a known) previous scientific, software-based studies? (remark: it’s mainly how we’ve investigated deep software variability so far… either as a threat to our own experiments or as a threat identified in papers)
- 78. Applications of different analysis pipelines, alterations in software version, and even changes in operating system have both shown to cause variation in the results of a neuroimaging study. Example: Joelle Pineau “Building Reproducible, Reusable, and Robust Machine Learning Software” ICSE’19 keynote “[...] results can be brittle to even minor perturbations in the domain or experimental procedure” Example: DEEP SOFTWARE VARIABILITY DEEP SOFTWARE VARIABILITY Deep software variability is a threat to scientific, software-based experiments 78
- 79. Deep Questions?
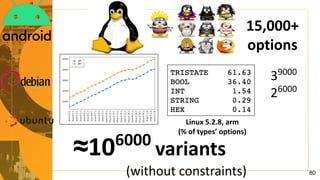
- 80. 15,000+ options Linux 5.2.8, arm (% of types’ options) 39000 26000 ≈106000 variants (without constraints) 80
- 82. Reproducible Science and Deep Software Variability REFERENCES [1] 2021. Hail, software! Nature Computational Science 1, 2 (01 Feb 2021), 89–89. https://doi.org/10.1038/s43588-021-00037-8 [2] Marc Andreessen. 2011. Why software is eating the world. Wall Street Journal 20, 2011 (2011), C2. [3] Lorena A Barba. 2018. Terminologies for reproducible re- search. arXiv preprint arXiv:1802.03311 (2018). [4] Rotem Botvinik-Nezer, Felix Holzmeister, Colin F Camerer, Anna Dreber, Juergen Huber, Magnus Johannesson, Michael Kirchler, Roni Iwanir, Jeanette A Mumford, R Alison Adcock, et al. 2020. Variability in the analysis of a single neuroimaging dataset by many teams. Nature 582, 7810 (2020), 84–88. [5] Xavier Bouthillier, César Laurent, and Pascal Vincent. 2019. Unreproducible research is reproducible. In International Con- ference on Machine Learning. PMLR, 725–734. [6] Joshua Carp. 2012. On the plurality of (methodological) worlds: estimating the analytic flexibility of FMRI experiments. Fron- tiers in neuroscience 6 (2012), 149. [7] Roberto Di Cosmo and Stefano Zacchiroli. 2017. Software heritage: Why and how to preserve software source code. In iPRES 2017-14th International Conference on Digital Preserva- tion. 1–10. [8] Steve M Easterbrook and Timothy C Johns. 2009. Engineering the software for understanding climate change. Computing in science & engineering 11, 6 (2009), 65–74. [9] Tristan Glatard, Lindsay B Lewis, Rafael Ferreira da Silva, Reza Adalat, Natacha Beck, Claude Lepage, Pierre Rioux, Marc- Etienne Rousseau, Tarek Sherif, Ewa Deelman, et al. 2015. Reproducibility of neuroimaging analyses across operating systems. Frontiers in neuroinformatics 9 (2015), 12. [10] Ed HBM Gronenschild, Petra Habets, Heidi IL Jacobs, Ron Mengelers, Nico Rozendaal, Jim Van Os, and Machteld Marcelis. 2012. The effects of FreeSurfer version, workstation type, and Macintosh operating system version on anatomical volume and cortical thickness measurements. PloS one 7, 6 (2012), e38234. [11] Peter Henderson, Riashat Islam, Philip Bachman, Joelle Pineau, Doina Precup, and David Meger. 2018. Deep reinforcement learning that matters. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 32. [12] Ruben Heradio, David Fernandez-Amoros, José A Galindo, David Benavides, and Don Batory. 2022. Uniform and scalable sampling of highly configurable systems. Empirical Software Engineering 27, 2 (2022), 1–34. [13] https://www.wcrp climate.org/. [n.d.]. World climat research program (WCRP). [14] Pooyan Jamshidi, Norbert Siegmund, Miguel Velez, Akshay Patel, and Yuvraj Agarwal. 2017. Transfer Learning for Per- formance Modeling of Configurable Systems: An Exploratory Analysis. In IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE Press, 497–508. [15] Pooyan Jamshidi, Miguel Velez, Christian Kästner, and Nor- bert Siegmund. 2018. Learning to Sample: Exploiting Similari- ties Across Environments to Learn Performance Models for Configurable Systems. In Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. ACM, 71–82. [16] Christian Kaltenecker, Alexander Grebhahn, Norbert Sieg- mund, and Sven Apel. 2020. The Interplay of Sampling and Machine Learning for Software Performance Prediction. IEEE Softw. 37, 4 (2020), 58–66. https://doi.org/10.1109/MS.2020. 2987024 [17] Christopher G Knight, Sylvia HE Knight, Neil Massey, Tolu Aina, Carl Christensen, Dave J Frame, Jamie A Kettleborough, Andrew Martin, Stephen Pascoe, Ben Sanderson, et al. 2007. Association of parameter, software, and hardware variation with large-scale behavior across 57,000 climate models. Pro- ceedings of the National Academy of Sciences 104, 30 (2007), 12259–12264. [18] Dagmar Krefting, Michael Scheel, Alina Freing, Svenja Specov- ius, Friedemann Paul, and Alexander Brandt. 2011. Relia- bility of quantitative neuroimage analysis using freesurfer in distributed environments. In MICCAI Workshop on High- Performance and Distributed Computing for Medical Imag- ing.(Toronto, ON). [19] R. Krishna, V. Nair, P. Jamshidi, and T. Menzies. 2020. Whence to Learn? Transferring Knowledge in Configurable Systems using BEETLE. IEEE Transactions on Software Engineering (2020), 1–1. [20] Dorian Leroy, June Sallou, Johann Bourcier, and Benoit Combe- male. 2021. When Scientific Software Meets Software En- gineering. Computer (2021), 1–11. https://hal.inria.fr/hal- 03318348 [21] Luc Lesoil, Mathieu Acher, Arnaud Blouin, and Jean-Marc Jézéquel. 2021. The Interaction between Inputs and Config- urations fed to Software Systems: an Empirical Study. CoRR abs/2112.07279 (2021). arXiv:2112.07279 https://arxiv.org/abs/ 2112.07279 [22] Luc Lesoil, Mathieu Acher, Arnaud Blouin, and Jean-Marc Jézéquel. 2021. Deep Software Variability: Towards Han- dling Cross-Layer Configuration. In VaMoS 2021 - 15th In- ternational Working Conference on Variability Modelling of Software-Intensive Systems. Krems / Virtual, Austria, 1–8. https://hal.inria.fr/hal-03084276 [23] Luc Lesoil, Mathieu Acher, Xhevahire Tërnava, Arnaud Blouin, and Jean-Marc Jézéquel. 2021. The Interplay of Compile-time and Run-time Options for Performance Prediction. In SPLC 2021 - 25th ACM International Systems and Software Product Line Conference - Volume A. ACM, Leicester, United Kingdom, 1–12. https://doi.org/10.1145/3461001.3471149 [24] Luc Lesoil, Hugo Martin, Mathieu Acher, Arnaud Blouin, and Jean-Marc Jézéquel. 2022. Transferring Performance between Distinct Configurable Systems : A Case Study. In VaMoS ’22: 16th International Working Conference on Variability Modelling of Software-Intensive Systems, Florence, Italy, February 23 - 25, 2022, Paolo Arcaini, Xavier Devroey, and Alessandro Fan- techi (Eds.). ACM, 10:1–10:6. https://doi.org/10.1145/3510466. 3510486 [25] Hugo Martin, Mathieu Acher, Juliana Alves Pereira, Luc Lesoil, Jean-Marc Jézéquel, and Djamel Eddine Khelladi. 2021. Trans- fer Learning Across Variants and Versions: The Case of Linux Kernel Size. IEEE Transactions on Software Engineering (2021),
- 83. Mathieu Acher 1–17. https://hal.inria.fr/hal-03358817 [26] François Massonnet, Martin Ménégoz, Mario Acosta, Xavier Yepes-Arbós, Eleftheria Exarchou, and Francisco J Doblas- Reyes. 2020. Replicability of the EC-Earth3 Earth system model under a change in computing environment. Geoscien- tific Model Development 13, 3 (2020), 1165–1178. [27] Olivier Mesnard and Lorena A Barba. 2017. Reproducible and replicable computational fluid dynamics: it’s harder than you think. Computing in Science & Engineering 19, 4 (2017), 44–55. [28] S. Mühlbauer, S. Apel, and N. Siegmund. 2020. Identifying Software Performance Changes Across Variants and Versions. In 2020 35th IEEE/ACM International Conference on Automated Software Engineering (ASE). 611–622. [29] Juliana Alves Pereira, Mathieu Acher, Hugo Martin, and Jean- Marc Jézéquel. 2020. Sampling Effect on Performance Pre- diction of Configurable Systems: A Case Study. In ICPE ’20: ACM/SPEC International Conference on Performance Engineer- ing, Edmonton, AB, Canada, April 20-24, 2020, José Nelson Ama- ral, Anne Koziolek, Catia Trubiani, and Alexandru Iosup (Eds.). ACM, 277–288. https://doi.org/10.1145/3358960.3379137 [30] Juliana Alves Pereira, Mathieu Acher, Hugo Martin, Jean- Marc Jézéquel, Goetz Botterweck, and Anthony Ventresque. 2021. Learning software configuration spaces: A system- atic literature review. J. Syst. Softw. 182 (2021), 111044. https://doi.org/10.1016/j.jss.2021.111044 [31] Quentin Plazar, Mathieu Acher, Gilles Perrouin, Xavier De- vroey, and Maxime Cordy. 2019. Uniform Sampling of SAT Solutions for Configurable Systems: Are We There Yet?. In 12th IEEE Conference on Software Testing, Validation and Verifi- cation, ICST 2019, Xi’an, China, April 22-27, 2019. IEEE, 240–251. https://doi.org/10.1109/ICST.2019.00032 [32] Georges Aaron Randrianaina, Djamel Eddine Khelladi, Olivier Zendra, and Mathieu Acher. 2022. Towards Incremental Build of Software Configurations. In ICSE-NIER 2022 - 44th International Conference on Software Engineering – New Ideas and Emerging Results. Pittsburgh, PA, United States, 1–5. https://doi.org/10.1145/3510455.3512792 [33] Georges Aaron Randrianaina, Xhevahire Tërnava, Djamel Ed- dine Khelladi, and Mathieu Acher. 2022. On the Benefits and Limits of Incremental Build of Software Configurations: An Exploratory Study. In ICSE 2022 - 44th International Confer- ence on Software Engineering. Pittsburgh, Pennsylvania / Vir- tual, United States, 1–12. https://hal.archives-ouvertes.fr/hal- 03547219 [34] Nicolas P. Rougier and Konrad Hinsen. 2019. ReScience C: A Journal for Reproducible Replications in Computational Sci- ence. In Reproducible Research in Pattern Recognition, Bertrand Kerautret, Miguel Colom, Daniel Lopresti, Pascal Monasse, and Hugues Talbot (Eds.). Springer International Publishing, Cham, 150–156. [35] Nicolas P. Rougier, Konrad Hinsen, Frédéric Alexandre, Thomas Arildsen, Lorena Barba, Fabien C. Y. Benureau, C. Ti- tus Brown, Pierre De Buyl, Ozan Caglayan, Andrew P. Davi- son, Marc André Delsuc, Georgios Detorakis, Alexandra K. Diem, Damien Drix, Pierre Enel, Benoît Girard, Olivia Guest, Matt G. Hall, Rafael Neto Henriques, Xavier Hinaut, Kamil S Jaron, Mehdi Khamassi, Almar Klein, Tiina Manninen, Pietro Marchesi, Dan McGlinn, Christoph Metzner, Owen L. Petchey, Hans Ekkehard Plesser, Timothée Poisot, Karthik Ram, Yoav Ram, Etienne Roesch, Cyrille Rossant, Vahid Rostami, Aaron Shifman, Joseph Stachelek, Marcel Stimberg, Frank Stollmeier, Federico Vaggi, Guillaume Viejo, Julien Vitay, Anya Vostinar, Roman Yurchak, and Tiziano Zito. 2017. Sustainable computa- tional science: the ReScience initiative. PeerJ Computer Science 3 (Dec. 2017), e142. https://doi.org/10.7717/peerj-cs.142 8 pages, 1 figure. [36] Mohammed Sayagh, Noureddine Kerzazi, Bram Adams, and Fabio Petrillo. 2018. Software Configuration Engineering in Practice: Interviews, Survey, and Systematic Literature Review. IEEE Transactions on Software Engineering (2018). [37] Raphael Silberzahn, Eric L Uhlmann, Daniel P Martin, Pasquale Anselmi, Frederik Aust, Eli Awtrey, Štěpán Bahník, Feng Bai, Colin Bannard, Evelina Bonnier, et al. 2018. Many analysts, one data set: Making transparent how variations in analytic choices affect results. Advances in Methods and Practices in Psychological Science 1, 3 (2018), 337–356. [38] Sara Steegen, Francis Tuerlinckx, Andrew Gelman, and Wolf Vanpaemel. 2016. Increasing transparency through a mul- tiverse analysis. Perspectives on Psychological Science 11, 5 (2016), 702–712. [39] Pavel Valov, Jean-Christophe Petkovich, Jianmei Guo, Sebas- tian Fischmeister, and Krzysztof Czarnecki. 2017. Transferring Performance Prediction Models Across Different Hardware Platforms. In Proceedings of the 8th ACM/SPEC on International Conference on Performance Engineering, ICPE 2017, L’Aquila, Italy, April 22-26, 2017. 39–50. https://doi.org/10.1145/3030207. 3030216 [40] Mahsa Varshosaz, Mustafa Al-Hajjaji, Thomas Thüm, Tobias Runge, Mohammad Reza Mousavi, and Ina Schaefer. 2018. A classification of product sampling for software product lines. In Proceeedings of the 22nd International Conference on Systems and Software Product Line - Volume 1, SPLC 2018, Gothenburg, Sweden, September 10-14, 2018. 1–13. https://doi.org/10.1145/ 3233027.3233035 [41] Max Weber, Sven Apel, and Norbert Siegmund. 2021. White- Box Performance-Influence models: A profiling and learning approach. In 2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). IEEE, 1059–1071. [42] Greg Wilson, Dhavide A Aruliah, C Titus Brown, Neil P Chue Hong, Matt Davis, Richard T Guy, Steven HD Haddock, Kathryn D Huff, Ian M Mitchell, Mark D Plumbley, et al. 2014. Best practices for scientific computing. PLoS biology 12, 1 (2014), e1001745.