
























![Job Configuration
Configuration conf = new Configuration();
Job job = new Job(conf, "wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
OR job.submit();
25](https://image.slidesharecdn.com/hadoopandbigdatatraining-130615235142-phpapp01/85/Hadoop-and-big-data-training-26-320.jpg)



![Shuffle and Sort
All same keys are guaranteed to end up in the same reducer,
sorted by key
Mapper output <K2,V2><‘the’,1>, <‘the’,2>, <‘cat’,1>
Reducer input <K2,[V2]><‘cat’,*1+>, <‘the’,*1,2+>
29](https://image.slidesharecdn.com/hadoopandbigdatatraining-130615235142-phpapp01/85/Hadoop-and-big-data-training-30-320.jpg)
![Reducer – Life cycle
Reducer inputs <K2, [V2]> outputs <K3, V3>
30](https://image.slidesharecdn.com/hadoopandbigdatatraining-130615235142-phpapp01/85/Hadoop-and-big-data-training-31-320.jpg)














Hadoop and big data training
- 1. Hadoop and Big Data Training Lessons learned 0
- 2. What’s Cloudera? Leading company in the NoSQL and cloud computing space Most popular Hadoop distribution Ex-es from Google, Facebook, Oracle and other leading tech companies Sample Bn$ companies client list: eBay,JPMorganChase,Experian,Groupon,MorganStanley,Nokia ,Orbitz,NationalCancerInstitute,RIM,TheWaltDisney Company Consulting and training services 1
- 3. Why this training? MongoDB is great for OLTP Not an OLAP DB, not really aspiring to become one Big Data coming in, need for more advanced analysis processes 2
- 4. Intended audience Software engineers and friends 3
- 5. The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models Modules: HadoopCommon Hadoop Distributed File System (HDFS™) HadoopYARN HadoopMapReduce 4 What’s Hadoop?
- 6. How does it fit in our Big Goal? MongoDB for OLTP RDBMS (MySQL) for config data Hadoop for OLAP 5
- 7. What’s Map Reduce? MapReduce is a programming model for processing large data sets, and the name of an implementation of the model by Google. MapReduce is typically used to do distributed computing on clusters of computers. © Wiki Practically? Can perform computations in a distributed fashion Highly scalable Inherently highly available By design fault tolerant 6
- 8. Bindings Native Java any language, even scripting ones, using Streaming 7
- 9. MapReduce framework vs. MapReduce functionality Several NoSQL technologies provide MR functionality 8
- 10. MR functionality Compromise…. i.e. MongoDB CouchDB select * from foo; ;; 9
- 11. MapReduce V1 vsMapReduce V2 MR V1 can not scale past 4k nodes per cluster More important to our goals, MR V1 is monolithic 10
- 12. MR V2 YARN Pluggable implementations on top of Hadoop Whole new set of problems can be solved: Graph processing MPI 11
- 14. MR V1 daemons client NameNode (HDFS) JobTracker DataNode(HDFS) + TaskTracker 13
- 16. MR V2 daemons Client Resource manager/Application manager NodeManager Application Master (resource containers) 15
- 17. Data Locality in Hadoop First replica placed in client node (or random if off cluster client) Second off-rack Third in same rack as second but different node 16
- 18. HDFS - Architecture Hot Very large files Streaming data access (seek time ~<1% transfer time) Commodity hardware (no iphones…) Not Low-latency data access Lots of small files Multiple writers, arbitrary file modification 17
- 19. HDFS – NameNode Namenode Master Filesystem tree Metadata for all files and directories Namespace image and edit log Secondary Namenode Not a backup node! Periodically merges edit log into namespace image Could take 30 mins to come back online 18
- 20. HDFS HA - NameNode 2.x Hadoop brings in HDFS HA Active-standby config for NameNodes Gotchas: Shared storage for edit log Datanodes send block reports to both NameNodes NameNode needs to be transparent to clients 19
- 21. HDFS – Read 20
- 22. HDFS - Read Client requests file from namenode (for first 10 blocks) Namenode returns addresses of datanodes Client contacts directly datanodes Blocks are read in order 21
- 23. HDFS - Write 22
- 24. HDFS - Write RPC initial call to create the file Permissions/file exists checks in NameNode etc As we write data, data queue in client which asks the NameNode for datanode to store data List of datanodes form a pipeline ack queue to verify all replicas have been written Close file 23
- 25. Job Configuration setInputFormatClass setOutputFormatClass setMapperClass setReducerClass Set(Map)OutputKeyClass set(Map)OutputValueClass setNumReduceTasks 24
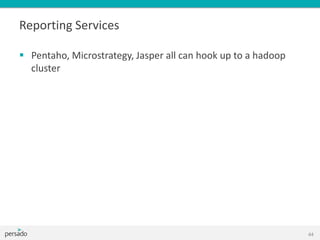
- 26. Job Configuration Configuration conf = new Configuration(); Job job = new Job(conf, "wordcount"); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); OR job.submit(); 25
- 27. Job Configuration Simple to invoke: bin/hadoop jar WordCountinputPathoutputPath 26
- 29. Mapper – Life cycle Mapper inputs <K1,V1> outputs <K2,V2> 28
- 30. Shuffle and Sort All same keys are guaranteed to end up in the same reducer, sorted by key Mapper output <K2,V2><‘the’,1>, <‘the’,2>, <‘cat’,1> Reducer input <K2,[V2]><‘cat’,*1+>, <‘the’,*1,2+> 29
- 31. Reducer – Life cycle Reducer inputs <K2, [V2]> outputs <K3, V3> 30
- 32. Hadoop interfaces and classes >=0.23 new API favoring abstract classes <0.23 old API with interfaces Packages mapred.* OLD API, mapreduce.* NEW API 31
- 33. Speculative execution At least one minute into a mapper or reducer, the Jobtracker will decide based on the progress of a task Threshold of each task progress compared to avgprogress(configurable) Relaunch task in different NameNode and have them race.. Sometimes not wanted Cluster utilization Non idempotent partial output (OutputCollector) 32
- 34. Input Output Formats InputFormat<K,V> ->FileInputFormat<K,V> ->TextInputFormat, KeyValueTextInputFormat, SequenceFileInputFormat Default TextInputFormat key=byte offset, value=line KeyValueTextInputFormat (key t value) Binary splittable format Corresponding Output formats 33
- 35. Compression The billion files problem 300B/file * 10^9 files 300G RAM Big Data storage Solutions: Containers Compression 34
- 36. Containers HAR (splittable) Sequence Files, RC files, Avro files (splittable, compressable) 35
- 37. Compression codecs LZO, LZ4, snappy codecs are best VFM in compression speed Bzip2 offers native splitting but can be slow 36
- 38. Long story short Compression + sequence files Compression that supports splitting Split file into chunks in application layer with chunk size aligned to HDFS block size Don’t bother 37
- 39. Partitioner Default is HashPartitioner Why implement our own partitioner? Sample case: Total ordering 1 reducer Multiple reducers? 38
- 40. Partitioner TotalOrderPartitioner Sample input to determine number of reducers for maximum performance 39
- 41. Hadoop Ecosystem Pig Apache Pig is a platform for analyzing large data sets. Pig's language, Pig Latin, lets you specify a sequence of data transformations such as merging data sets, filtering them, and applying functions to records or groups of records. Procedural language, lazy evaluated, pipeline split support Closer to developers (or relational algebra aficionados) than not 40
- 42. Hadoop Ecosystem Hive Access to hadoop clusters for non developers Data analysts, data scientists, statisticians, SDMs etc Subset of SQL-92 plus Hive extensions Insert overwrite, no update or delete No transactions No indexes, parallel scanning “Near” real time Only equality joins 41
- 43. Hadoop Ecosystem Mahout Collaborative Filtering User and Item based recommenders K-Means, Fuzzy K-Means clustering Mean Shift clustering Dirichlet process clustering Latent Dirichlet Allocation Singular value decomposition Parallel Frequent Pattern mining Complementary Naive Bayes classifier Random forest decision tree based classifier 42
- 44. Hadoop ecosystem Algorithmic categories: Classification Clustering Pattern mining Regression Dimension reduction Recommendation engines Vector similarity … 43
- 45. Reporting Services Pentaho, Microstrategy, Jasper all can hook up to a hadoop cluster 44
- 46. References Hadoop the definite guide 3rd edition apache.hadoop.org Hadoop in practice Cloudera Custom training slides 45