






















































![Map and Reduce
Map()
Map workers read in contents of corresponding input partition
Process a key/value pair to generate intermediate key/value pairs
Reduce()
Merge all intermediate values associated with the same key
eg. <key, [value1, value2,..., valueN]>
Output of user's reduce function is written to output file on global file system
When all tasks have completed, master wakes up user program](https://image.slidesharecdn.com/bigdata-vahidamiri-datastack-170317175916/85/-56-320.jpg)



عصر کلان داده، چرا و چگونه؟
- 1. و چرا ،داده کالن عصر چگونه؟ VAHID AMIRI VAHIDAMIRY.IR [email protected]
- 2. Big DataData Data Processing Data Gathering Data Storing
- 4. Big Data Definition No single standard definition… “Big Data” is data whose scale, diversity, and complexity require new architecture, techniques, algorithms, and analytics to manage it and extract value and hidden knowledge from it…
- 6. 12+ TBs of tweet data every day 25+ TBs of log data every day ?TBsof dataeveryday 2+ billion people on the Web by end 2011 30 billion RFID tags today (1.3B in 2005) 4.6 billion camera phones world wide 100s of millions of GPS enabled devices sold annually 76 million smart meters in 2009… 200M by 2014 Volume
- 7. Variety (Complexity) Relational Data (Tables/Transaction/Legacy Data) Text Data (Web) Semi-structured Data (XML) Graph Data Social Network, Semantic Web (RDF), … Streaming Data You can only scan the data once Big Public Data (online, weather, finance, etc) To extract knowledge all these types of data need to linked together
- 8. A Single View to the Customer Customer Social Media Gaming Entertain Bankin g Financ e Our Known History Purchase
- 9. Velocity (Speed) Data is begin generated fast and need to be processed fast Online Data Analytics Late decisions missing opportunities Social media and networks (all of us are generating data) Mobile devices (tracking all objects all the time) Sensor technology and networks (measuring all kinds of data)
- 10. Some Make it 4V’s
- 11. The Model of Generating/Consuming Data has Changed The Model Has Changed… Old Model: Few companies are generating data, all others are consuming data New Model: all of us are generating data, and all of us are consuming data
- 14. Hadoop is a software framework for distributed processing of large datasets across large clusters of computers Hadoop implements Google’s MapReduce, using HDFS MapReduce divides applications into many small blocks of work. HDFS creates multiple replicas of data blocks for reliability, placing them on compute nodes around the cluster Hadoop
- 16. Spark Stack
- 17. More than just the Elephant in the room Over 120+ types of NoSQL databases So many NoSQL options
- 18. Extend the Scope of RDBMS Caching Master/Slave Table Partitioning Federated Tables Sharding NoSql Relational database (RDBMS) technology Has not fundamentally changed in over 40 years Default choice for holding data behind many web apps Handling more users means adding a bigger server
- 19. RDBMS with Extended Functionality Vs. Systems Built from Scratch with Scalability in Mind NoSQL Movement
- 20. CAP Theorem “Of three properties of shared-data systems – data Consistency, system Availability and tolerance to network Partition – only two can be achieved at any given moment in time.”
- 21. “Of three properties of shared-data systems – data Consistency, system Availability and tolerance to network Partition – only two can be achieved at any given moment in time.” CA Highly-available consistency CP Enforced consistency AP Eventual consistency CAP Theorem
- 22. Flavors of NoSQL
- 23. Schema-less State (Persistent or Volatile) Example: Redis Amazon DynamoDB Key / Value Database
- 24. Wide, sparse column sets Schema-light Examples: Cassandra HBase BigTable GAE HR DS Column Database
- 25. Use for data that is document-oriented (collection of JSON documents) w/semi structured data Encodings include XML, YAML, JSON & BSON binary forms PDF, Microsoft Office documents -- Word, Excel…) Examples: MongoDB, CouchDB Document Database
- 26. Graph Database Use for data with a lot of many-to-many relationships when your primary objective is quickly finding connections, patterns and relationships between the objects within lots of data Examples: Neo4J, FreeBase (Google)
- 27. So which type of NoSQL? Back to CAP… CP = noSQL/column Hadoop Big Table HBase MemCacheDB AP = noSQL/document or key/value DynamoDB CouchDB Cassandra Voldemort CA = SQL/RDBMS SQL Sever / SQL Azure Oracle MySQL
- 30. Apache Hadoop A framework for storing & processing Petabyte of data using commodity hardware and storage Apache project Implemented in Java Community of contributors is growing Yahoo: HDFS and MapReduce Powerset: HBase Facebook: Hive and FairShare scheduler IBM: Eclipse plugins
- 31. Briefing history of Hadoop
- 33. Hadoop System Principles Scale-Out rather than Scale-Up Bring code to data rather than data to code Deal with failures – they are common Abstract complexity of distributed and concurrent applications
- 34. Scale-Out Instead of Scale-Up It is harder and more expensive to scale-up Add additional resources to an existing node (CPU, RAM) New units must be purchased if required resources can not be added Also known as scale vertically Scale-Out Add more nodes/machines to an existing distributed application Software Layer is designed for node additions or removal Hadoop takes this approach - A set of nodes are bonded together as a single distributed system Very easy to scale down as well
- 35. Code to Data Traditional data processing architecture Nodes are broken up into separate processing and storage nodes connected by high-capacity link Many data-intensive applications are not CPU demanding causing bottlenecks in network
- 36. Code to Data Hadoop co-locates processors and storage Code is moved to data (size is tiny, usually in KBs) Processors execute code and access underlying local storage
- 37. Failures are Common Given a large number machines, failures are common Large warehouses may see machine failures weekly or even daily Hadoop is designed to cope with node failures Data is replicated Tasks are retried
- 38. Abstract Complexity Hadoop abstracts many complexities in distributed and concurrent applications Defines small number of components Provides simple and well defined interfaces of interactions between these components Frees developer from worrying about system level challenges processing pipelines, data partitioning, code distribution Allows developers to focus on application development and business logic
- 39. Distribution Vendors Cloudera Distribution for Hadoop (CDH) MapR Distribution Hortonworks Data Platform (HDP) Apache BigTop Distribution
- 40. Components Distributed File System HDFS Distributed Processing Framework Map/Reduce
- 41. The Storage: Hadoop Distributed File System
- 42. HDFS is Good for... Storing large files Terabytes, Petabytes, etc... Millions rather than billions of files 100MB or more per file Streaming data Write once and read-many times patterns Optimized for streaming reads rather than random reads “Cheap” Commodity Hardware No need for super-computers, use less reliable commodity hardware
- 43. HDFS Daemons
- 44. Files and Blocks
- 46. REPLICA MANGEMENT A common practice is to spread the nodes across multiple racks A good replica placement policy should improve data reliability, availability, and network bandwidth utilization Namenode determines replica placement
- 47. NETWORK TOPOLOGY AND HADOOP
- 48. The Execution Engine: Apache Yarn
- 49. Apache Yarn
- 50. Yarn Components RescourceManager: Arbitrates resources among all the applications in the system NodeManager: the per-machine slave, which is responsible for launching the applications’ containers, monitoring their resource usage ApplicationMaster: Negotiate appropriate resource containers from the Scheduler, tracking their status and monitoring for progress Container: Unit of allocation incorporating resource elements such as memory, cpu, disk, network etc., to execute a specific task of the application (similar to map/reduce slots in MRv1)
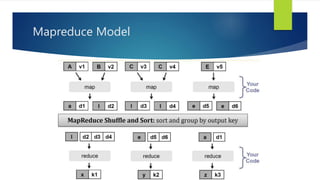
- 54. What is MapReduce? Parallel programming model for large clusters User implements Map() and Reduce() Parallel computing framework Libraries take care of EVERYTHING else Parallelization Fault Tolerance Data Distribution Load Balancing MapReduce library does most of the hard work for us! Takes care of distributed processing and coordination Scheduling Task Localization with Data Error Handling Data Synchronization
- 56. Map and Reduce Map() Map workers read in contents of corresponding input partition Process a key/value pair to generate intermediate key/value pairs Reduce() Merge all intermediate values associated with the same key eg. <key, [value1, value2,..., valueN]> Output of user's reduce function is written to output file on global file system When all tasks have completed, master wakes up user program
- 57. Distributed Processing Word count on a huge file
- 58. Mapreduce Model