Map and Reduce
0 likes1,263 views

This document provides an overview of Map & Reduce, a programming model for processing large datasets in parallel. It describes how Map & Reduce works by applying mapping functions to each element to generate intermediate key-value pairs, shuffling and sorting the data, then applying reduction functions to aggregate the values associated with each key. As an example, it walks through how the "word count" problem can be solved using Map & Reduce. Finally, it briefly discusses Google's implementation of MapReduce and the Apache Hadoop framework.























Map and Reduce
- 1. Map & ReduceChristopher Schleiden, Christian Corsten, Michael Lottko, Jinhui Li1The slides are licensed under aCreative Commons Attribution 3.0 License
- 2. OutlineMotivationConceptParallel Map & ReduceGoogle’s MapReduceExample: Word CountDemo: HadoopSummaryWeb Technologies2
- 3. Today the web is all about data!GoogleProcessing of 20 PB/day (2008)LHCWill generate about 15PB/yearFacebook2.5 PB of data+ 15 TB/day (4/2009)3BUT: It takes ~2.5 hours to read one terabyte off a typical hard disk!
- 4. 4Solution: Going Parallel!Data DistributionHowever, parallel programming is hard! SynchronizationLoad Balancing…
- 5. Map & ReduceProgramming model and Framework Designed for large volumes of data in parallelBased on functional map and reduce concepte.g., Output of functions only depends on their input, there are no side-effects5
- 6. Functional ConceptMapApply function to each value of a sequencemap(k,v) <k’, v’>*Reduce/FoldCombine all elements of a sequence using binary operator reduce(k’, <v’>*) <k’, v’>*6
- 7. Typical problemIterate over large number of recordsExtract something interestingShuffle & sort intermediate resultsAggregate intermediate resultsWrite final output7MapReduce
- 8. Parallel Map & Reduce8
- 9. Parallel Map & ReducePublished (2004) and patented (2010) by Google IncC++ Runtime with Bindings to Java/PythonOther Implementations:Apache Hadoop/Hive project (Java)Developed at Yahoo!Used by:FacebookHuluIBMAnd many moreMicrosoft COSMOS (Scope, based on SQL and C#)Starfish (Ruby)… 9Footer Text
- 10. Parallel Map & Reduce /2Parallel execution of Map and Reduce stagesScheduling through Master/Worker patternRuntime handles:Assigning workers to map and reduce tasksData distributionDetects crashed workers10
- 11. Parallel Map & Reduce Execution11MapReduceInputOutputShuffle & SortDREASUTLTA
- 12. Components in Google’s MapReduceWeb Technologies12
- 13. Google Filesystem (GFS)Stores…Input dataIntermediate resultsFinal results…in 64MB chunks on at least three different machinesWeb Technologies13FileNodes
- 14. Scheduling (Master/Worker)One master, many workerInput data split into M map tasks (~64MB in Size; GFS)Reduce phase partitioned into R tasksTasks are assigned to workers dynamicallyMaster assigns each map task to a free workerMaster assigns each reducetask to a free workerFault handling via RedundancyMaster checks if Worker still alive via heart-beatReschedules work item if worker has diedWeb Technologies14
- 15. Scheduling Example15MapReduceInputOutputTempMasterAssign mapAssign reduceDWorkerWorkerRESAWorkerTWorkerULTWorkerA
- 16. Googles M&R vsHadoopGoogle MapReduceMain language: C++Google Filesystem (GFS)GFS MasterGFS chunkserverHadoopMapReduceMain language: JavaHadoopFilesystem (HDFS)HadoopnamenodeHadoopdatanodeWeb Technologies16
- 17. Word CountThe Map & Reduce “Hello World” example17
- 18. Word Count - InputSet of text files:Expected Output:sweet (1), this (2), is (2), the (2), foo (1), bar (1), file (1)18bar.txtThis is the bar filefoo.txtSweet, this is the foo file
- 19. Word Count - MapMapper(filename, file-contents):for each wordemit(word,1)Outputthis (1)is (1)the (1)sweet (1)this (1)the (1) is (1) foo (1) bar (1) file (1)19
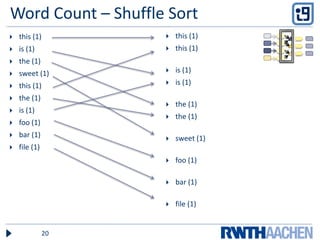
- 20. Word Count – Shuffle Sortthis (1)is (1)the (1)sweet (1)this (1)the (1) is (1) foo (1) bar (1) file (1)this (1)this (1)is (1)is (1) the (1)the (1) sweet (1)foo (1) bar (1) file (1)20
- 21. Word Count - Reducereducer(word, values):sum = 0for each value in values:sum = sum + valueemit(word,sum)Outputsweet (1)this (2)is (2)the (2)foo (1)bar (1) file (1)21
- 22. DEMOHadoop – Word Count22
- 23. SummaryLots of data processed on the web (e.g., Google)Performance solution: Go parallelInput, Map, Shuffle & Sort, Reduce, OutputGoogle File SystemScheduling: Master/WorkerWord Count exampleHadoopQuestions?Web Technologies23
- 24. ReferencesInspirations for presentationhttp://www4.informatik.uni-erlangen.de/Lehre/WS10/V_MW/Uebung/folien/05-Map-Reduce-Framework.pdfhttp://www.scribd.com/doc/23844299/Map-Reduce-Hadoop-PigRWTH Map Reduce Talk: http://bit.ly/f5oM7pPaperDean et al, MapReduce: Simplified Data Processing on Large Clusters, OSDI'04: Sixth Symposium on Operating System Design and Implementation, San Francisco, CA, December, 2004Ghemawat et al, The Google File System, 19th ACM Symposium on Operating Systems Principles, Lake George, NY, October, 2003.24
Editor's Notes
- #4: In these days the web is all about data. All major and important websites relay on huge amount of data in some form in order to provide services to users. For example Google … and Facebook …. Also facilities like the LHC will produce data measures in peta bytes each year. However, it takes about 2.5 hours in order to read one terabyte off a typical hard drive. The solution that comes immediately to mind, of course, is going parallel. KonkretesBeispiel [TODO], [Kontextzu Cloud Computing]
- #5: Parallel programming is still hard. Programmers have to deal with a lot of boilerplate code and have to manually write code for things like scheduling and load balancing. Also people want to use the company cluster in parallel, so something like a batch system is needed. As more and more companies use huge amounts of data, a some kind of standard framework or platform has emerged in recent years and that is the Map/Reduce framework.
- #7: Map Reduce known for years as functional programming concept
- #16: Actual execution and scheduling
- #25: http://www4.informatik.uni-erlangen.de/Lehre/WS10/V_MW/Uebung/folien/05-Map-Reduce-Framework.pdf