DataEngConf: Parquet at Datadog: Fast, Efficient, Portable Storage for Big Data
1 like1,485 views

The document outlines Datadog's use of Parquet for efficiently collecting and processing vast amounts of metrics data from cloud applications. It highlights key aspects such as their data pipeline, the benefits of using Parquet, and some production insights related to storage efficiency and read performance. The discussion emphasizes the importance of separate compute and storage as well as a standard data format for optimal performance.





























DataEngConf: Parquet at Datadog: Fast, Efficient, Portable Storage for Big Data
- 1. Parquet at Datadog How we use Parquet for tons of metrics data Doug Daniels, Director of Engineering
- 2. Outline • Monitor everything • Our data / why we chose Parquet • A bit about Parquet • Our pipeline • What we see in production
- 3. Datadog is a monitoring service for large scale cloud applications
- 4. Collect Everything Integrations for 100+ components
- 6. Alert on Critical Issues Collaborate to Fix them Together Monitor Everything
- 7. We collect a lot of data
- 8. We collect a lot of data… the biggest and most important of which is
- 9. Metric timeseries data timestamp 1447020511 metric system.cpu.idle value 98.16687
- 10. We collect hundreds of billions of these per day …and growing every week
- 11. And we do massive computation on them
- 12. • Statistical analysis • Machine learning • Ad-hoc queries • Reporting and aggregation • Metering and billing
- 13. One size does not fit all.
- 14. ETL and aggregation Pig / Hive ML and iterative algorithms Spark Interactive SQL Presto We want the best framework for each job
- 15. How do we do that? Duplicating data storage Writing redundant glue code Copying data definitions and schema
- 16. 1. Separate Compute and Storage • Amazon S3 as data system-of-record • Ephemeral, job-specific clusters • Write storage once, read everywhere
- 17. 2. Standard Data Format • Supported by major frameworks • Schema-aware • Fast to read • Strong community
- 19. Parquet is a column-oriented data storage format
- 20. What we love about Parquet • Interoperable! • Stores our data super efficiently • Proven at scale on S3 • Strong community
- 21. Quick Parquet primer Column A Row Group 0 Page 0 Page 1 Page 2 Column B Page 0 Page 1 File Meta Data Footer Row Group 0 Metadata Column B Metadata … Column A Metadata
- 22. Efficient storage and fast reads • Space efficiencies (per page) • Type-specific encodings: run-length, delta, … • Compression • Query efficiencies (support varies by framework) • Projection pushdown (skip columns) • Predicate pushdown (skip row groups) • Vectorized read (many rows at a time)
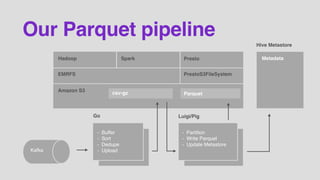
- 24. Our Parquet pipeline Kafka - Buffer - Sort - Dedupe - Upload Go Hadoop Spark Presto PrestoS3FileSystemEMRFS - Partition - Write Parquet - Update Metastore Luigi/Pig Metadata Hive Metastore csv-gz Amazon S3 Parquet
- 25. What we see in production
- 26. Excellent storage efficiency • For just 5 columns: • 3.5X less storage than gz-compressed CSV • 2.5X less than internal query-optimized columnar format
- 27. …a little too efficient • One 80MB parquet file with 160M rows / row group • Creates long-running map tasks • Added PARQUET-344 to limit rows per row group • Want to switch this to limit by uncompressed size
- 28. Slower read performance with AvroParquet Runtime for our test job (mins) 0 min 10 min 20 min 30 min 40 min C SV + gz AvroParquet+ gz AvroParquet+ snappy Parquet+ gz • Tried reading schema w/ AvroReader • Saw 3x slower reads with AvroParquet (YMMV) on jobs • Using HCatalog reader + hive metastore for schema in production
- 29. Our Parquet configuration • Parquet block size (and dfs block size): 128 MB • Page size: 1 MB • Compression: gzip • Schema Metadata: pig (we actually use hive metastore)
- 30. Thanks! Want to work with us on Spark, Hadoop, Kafka, Parquet, Presto, and more? DM me @ddaniels888 or [email protected]