Discovering User's Topics of Interest in Recommender Systems
14 likes•6,569 views

The document discusses the integration of recommender systems and topic modeling to enhance user experience in corporate collaboration platforms like Smart Canvas. It covers various types of recommendation techniques, including content-based and collaborative filtering, as well as the importance of topic modeling for identifying user interests and trends. Additionally, it highlights the architecture and algorithms used to personalize content recommendations based on discovered user topics.



































![Topic Modeling example (Python / gensim)
from gensim import corpora, models, similarities
documents = ["Human machine interface for lab abc computer applications",
"A survey of user opinion of computer system response time",
"The EPS user interface management system", ...]
stoplist = set('for a of the and to in'.split())
texts = [[word for word in document.lower().split() if word not in stoplist] for document in documents]
dictionary = corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
tfidf = models.TfidfModel(corpus)
corpus_tfidf = tfidf[corpus]
lsi = models.LsiModel(corpus_tfidf, id2word=dictionary, num_topics=2)
corpus_lsi = lsi[corpus_tfidf]
lsi.print_topics(2)
topic #0(1.594): 0.703*"trees" + 0.538*"graph" + 0.402*"minors" + 0.187*"survey" + ...
topic #1(1.476): 0.460*"system" + 0.373*"user" + 0.332*"eps" + 0.328*"interface" + 0.320*"response" + ...
Example of topic modeling using LSI technique
Example of the 2 topics discovered in the corpus
1
2
3
4
5
6
7
8
9
10
11
12
13](https://image.slidesharecdn.com/tdc2016palestrasmartcanvasrecsystopicmodeling1-160707195144/85/Discovering-User-s-Topics-of-Interest-in-Recommender-Systems-36-320.jpg)
![from pyspark.mllib.clustering import LDA, LDAModel
from pyspark.mllib.linalg import Vectors
# Load and parse the data
data = sc.textFile("data/mllib/sample_lda_data.txt")
parsedData = data.map(lambda line: Vectors.dense([float(x) for x in line.strip().split(' ')]))
# Index documents with unique IDs
corpus = parsedData.zipWithIndex().map(lambda x: [x[1], x[0]]).cache()
# Cluster the documents into three topics using LDA
ldaModel = LDA.train(corpus, k=3)
Topic Modeling example (PySpark MLLib LDA)
Sometimes simpler is better!
Scikit-learn topic models worked better for us than Spark MLlib LDA distributed
implementation because we have thousands of users with hundreds of posts,
and running scikit-learn on workers for each person was much quicker than
running distributed Spark LDA for each person.
1
2
3
4
5
6
7
8
9](https://image.slidesharecdn.com/tdc2016palestrasmartcanvasrecsystopicmodeling1-160707195144/85/Discovering-User-s-Topics-of-Interest-in-Recommender-Systems-37-320.jpg)
![Cosine similarity
Similarity metric between two vectors is cosine among the angle between them
from sklearn.metrics.pairwise import cosine_similarity
cosine_similarity(tfidf_matrix[0:1], tfidf_matrix)
Example with scikit-learn](https://image.slidesharecdn.com/tdc2016palestrasmartcanvasrecsystopicmodeling1-160707195144/85/Discovering-User-s-Topics-of-Interest-in-Recommender-Systems-38-320.jpg)















![Gremlin traversals
g.V().has('CONTENT','id', 'Post:123')
.outE('IS SIMILAR TO')
.has('strength', gte(0.1)).as('e').inV().as('v')
.select('e','v')
.map{['id': it.get().v.values('id').next(),
'strength': it.get().e.values('strength').next()]}
.limit(10)
Querying similar contents
[{‘id’: ‘Post:456’, ‘strength’: 0.672},
{‘id’: ‘Post:789’, ‘strength’: 0.453},
{‘id’: ‘Post:333’, ‘strength’: 0.235},
...]
Example output:
Content Content
IS SIMILAR TO
1
2
3
4
5
6
7](https://image.slidesharecdn.com/tdc2016palestrasmartcanvasrecsystopicmodeling1-160707195144/85/Discovering-User-s-Topics-of-Interest-in-Recommender-Systems-55-320.jpg)
![Gremlin traversals
g.V().has('PERSON','id','Person:gabrielpm@ciandt.com')
.out('IS ABOUT').has('number', 1)
.inE('IS RECOMMENDED TO').filter{ it.get().value('strength') >= 0.1}
.order().by('strength',decr).as('tc').outV().as('c')
.select('tc','c')
.map{ ['contentId': it.get().c.value('id'),
'recommendationStrength': it.get().tc.value('strength') *
getTimeDecayFactor(it.get().c.value('updatedOn')) ] }
Querying recommended contents for a person
[{‘contentId’: ‘Post:456’, ‘strength’: 0.672},
{‘contentId’: ‘Post:789’, ‘strength’: 0.453},
{‘contentId’: ‘Post:333’, ‘strength’: 0.235},
...]
Example output:
Person Topic
IS ABOUT
Content
IS RECOMMENDED TO
1
2
3
4
5
6
7
8](https://image.slidesharecdn.com/tdc2016palestrasmartcanvasrecsystopicmodeling1-160707195144/85/Discovering-User-s-Topics-of-Interest-in-Recommender-Systems-56-320.jpg)



Discovering User's Topics of Interest in Recommender Systems
- 1. Discovering Users’ Topics of Interest in Recommender Systems Gabriel Moreira - @gspmoreira Gilmar Souza - @gilmarsouza Track: Data Science 2016
- 2. Agenda ● Recommender Systems ● Topic Modeling ● Case: Smart Canvas - Corporative Collaboration ● Wrap up
- 4. Life is too short!
- 6. Recommendations by interaction What should I watch today? What do you like, my son?
- 7. "A lot of times, people don’t know what they want until you show it to them." Steve Jobs "We are leaving the Information Age and entering the Recommendation Age.". Cris Anderson, "The long tail"
- 8. 38% of sales 2/3 movie rentals Recommendations are responsible for... 38% of top news visualization
- 9. What else may I recommend?
- 10. What can a Recommender Systems do? Prediction Given an item, what is its relevance for each user? Recommendation Given a user, produce an ordered list matching the user needs
- 11. How it works
- 12. Content-Based Filtering Similar content (e.g. actor) Likes Recommends
- 13. Advantages ● Does not depend upon other users ● May recommend new and unpopular items ● Recommendations can be easily explained Drawbacks ● Overspecialization ● May not recommend to new users May be difficult to extract attributes from audio, movies or images Content-Based Filtering
- 14. User-Based Collaborative Filtering Similar interests Likes Recommends
- 15. Item-Based Collaborative Filtering Likes Recommends Who likes A also likes B Likes Likes
- 16. Collaborative Filtering Advantages ● Works to any item kind (ignore attributes) Drawbacks ● Cannot recommend items not already rated/consumed ● Usually recommends more popular items ● Needs a minimum amount of users to match similar users (cold start)
- 17. Hybrid Recommender Systems Composite Iterates by a chain of algorithm, aggregating recommendations. Weighted Each algorithm has as a weight and the final recommendations are defined by weighted averages. Some approaches
- 18. UBCF Example (Java / Mahout) // Loads user-item ratings DataModel model = new FileDataModel(new File("input.csv")); // Defines a similarity metric to compare users (Person's correlation coefficient) UserSimilarity similarity = new PearsonCorrelationSimilarity(model); // Threshold the minimum similarity to consider two users similar UserNeighborhood neighborhood = new ThresholdUserNeighborhood(0.1, similarity, model); // Create a User-Based Collaborative Filtering recommender UserBasedRecommender recommender = new GenericUserBasedRecommender (model, neighborhood, similarity); // Return the top 3 recommendations for userId=2 List recommendations = recommender.recommend(2, 3); User,Item,Rating1, 15,4.0 1,16,5.0 1,17,1.0 1,18,5.0 2,10,1.0 2,11,2.0 2,15,5.0 2,16,4.5 2,17,1.0 2,18,5.0 3,11,2.5 input.csv User-Based Collaborative Filtering example (Mahout) 1 2 3 4 5 6
- 19. Frameworks - Recommender Systems Python Python / ScalaJava .NET Java
- 20. Books
- 22. Topic Modeling A simple way to analyze topics of large text collections (corpus). What is this data about? What are the main topics?
- 23. Topic A Cluster of words that generally occur together and are related. Example 2D topics visualization with pyLDAviz (topics are the circles in the left, main terms of selected topic are shown in the right)
- 24. Topics evolution Visualization of topics evolution during across time
- 25. Topic Modeling applications ● Detect trends in the market and customer challenges of a industry from media and social networks. ● Marketing SEO: Optimization of search keywords to improve page ranking in searchers ● Identify users preferences to recommend relevant content, products, jobs, …
- 26. ● Documents are composed by many topics ● Topics are composed by many words (tokens) Topic Modeling Documents Topics Words (Tokens) Observable Latent Observable Unsupervised learning technique, which does not require too much effort on pre- processing (usually just Text Vectorization). In general, the only parameter is the number of topics (k).
- 27. Topics in a document
- 28. Topics example from NYT Topic analysis (LDA) from 1.8 millions of New York Times articles
- 29. How it works
- 30. Text vectorization Represent each document as a feature vector in the vector space, where each position represents a word (token) and the contained value is its relevance in the document. ● BoW (Bag of words) ● TF-IDF (Term Frequency - Inverse Document Frequency) Document Term Matrix - Bag of Words
- 32. TF-IDF example with scikit-learn from sklearn.feature_extraction.text import TfidfVectorizer vectorizer = TfidfVectorizer(max_df=0.5, max_features=1000, min_df=2, stop_words='english') tfidf_corpus = vectorizer.fit_transform(text_corpus) face person guide lock cat dog sleep micro pool gym 0 1 2 3 4 5 6 7 8 9 D1 0.05 0.25 D2 0.02 0.32 0.45 ... ... tokens documents TF-IDF sparse matrix example
- 33. Text vectorization “Did you ever wonder how great it would be if you could write your jmeter tests in ruby ? This projects aims to do so. If you use it on your project just let me now. On the Architecture Academy you can read how jmeter can be used to validate your Architecture. definition | architecture validation | academia de arquitetura” Example Tokens (unigrams and bigrams) Weight jmeter 0.466 architecture 0.380 validate 0.243 validation 0.242 definition 0.239 write 0.225 academia arquitetura 0.218 academy 0.216 ruby 0.213 tests 0.209 Relevant keywords (TF-IDF)
- 34. Visualization of the average TF-IDF vectors of posts at Google+ for Work (CI&T) Text vectorization See the more details about this social and text analytics at http://bit.ly/python4ds_nb
- 35. Main techniques ● Latent Dirichlet Allocation (LDA) -> Probabilistic ● Latent Semantic Indexing / Analysis (LSI / LSA) -> Matrix Factorization ● Non-Negative Matrix Factorization (NMF) -> Matrix Factorization
- 36. Topic Modeling example (Python / gensim) from gensim import corpora, models, similarities documents = ["Human machine interface for lab abc computer applications", "A survey of user opinion of computer system response time", "The EPS user interface management system", ...] stoplist = set('for a of the and to in'.split()) texts = [[word for word in document.lower().split() if word not in stoplist] for document in documents] dictionary = corpora.Dictionary(texts) corpus = [dictionary.doc2bow(text) for text in texts] tfidf = models.TfidfModel(corpus) corpus_tfidf = tfidf[corpus] lsi = models.LsiModel(corpus_tfidf, id2word=dictionary, num_topics=2) corpus_lsi = lsi[corpus_tfidf] lsi.print_topics(2) topic #0(1.594): 0.703*"trees" + 0.538*"graph" + 0.402*"minors" + 0.187*"survey" + ... topic #1(1.476): 0.460*"system" + 0.373*"user" + 0.332*"eps" + 0.328*"interface" + 0.320*"response" + ... Example of topic modeling using LSI technique Example of the 2 topics discovered in the corpus 1 2 3 4 5 6 7 8 9 10 11 12 13
- 37. from pyspark.mllib.clustering import LDA, LDAModel from pyspark.mllib.linalg import Vectors # Load and parse the data data = sc.textFile("data/mllib/sample_lda_data.txt") parsedData = data.map(lambda line: Vectors.dense([float(x) for x in line.strip().split(' ')])) # Index documents with unique IDs corpus = parsedData.zipWithIndex().map(lambda x: [x[1], x[0]]).cache() # Cluster the documents into three topics using LDA ldaModel = LDA.train(corpus, k=3) Topic Modeling example (PySpark MLLib LDA) Sometimes simpler is better! Scikit-learn topic models worked better for us than Spark MLlib LDA distributed implementation because we have thousands of users with hundreds of posts, and running scikit-learn on workers for each person was much quicker than running distributed Spark LDA for each person. 1 2 3 4 5 6 7 8 9
- 38. Cosine similarity Similarity metric between two vectors is cosine among the angle between them from sklearn.metrics.pairwise import cosine_similarity cosine_similarity(tfidf_matrix[0:1], tfidf_matrix) Example with scikit-learn
- 39. Example of relevant keywords for a person and people with similar interests People similarity
- 40. Frameworks - Topic Modeling Python Java Stanford Topic Modeling Toolbox (Excel plugin) http://nlp.stanford.edu/software/tmt/tmt-0.4/ Python / Scala
- 41. Smart Canvas© Corporate Collaboration http://www.smartcanvas.com/ Powered by Recommender Systems and Topic Modeling techniques Case
- 42. Content recommendations Discover channel - Content recommendations with personalized explanations, based on user’s topics of interest (discovered from their contributed content and reads)
- 43. Person topics of interest User profile - Topics of interest of users are from the content that they contribute and are presented as tags in their profile.
- 44. Searching people interested in topics / experts... User discovered tags are searchable, allowing to find experts or people with specific interests.
- 45. Similar people People recommendation - Recommends people with similar interests, explaining which topics are shared.
- 46. How it works
- 47. Collaboration Graph Model Smart Canvas © Graph Model: Dashed lines and bold labels are the relationships inferred by usage of RecSys and Topic Modeling techniques
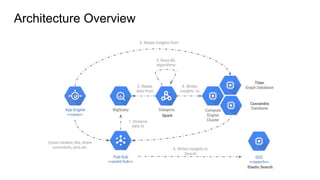
- 49. Jobs Pipeline Content Vectorization People Topic Modeling Boards Topic Modeling Contents Recommendation Boards Recommendation Similar ContentGoogle Cloud Storage Google Cloud Storage pickles pickles pickles loads loads loads loads loads Stores topics and recommendations in the graph 1 2 3 4 5 6 loads content loads touchpoints
- 50. 1. Groups all touchpoints (user interactions) by person 2. For each person a. Selects contents user has interacted b. Clusters contents TF-IDF vectors to model (e.g. LDA, NMF, Kmeans) person’ topics of interest (varying the k from a range (1-5) and selecting the model whose clusters best describe cohesive topics, penalizing large k) c. Weights clusters relevance (to the user) by summing touchpoints strength (view, like, bookmark, …) of each cluster, with a time decay on interaction age (older interactions are less relevant to current person interest) d. Returns highly relevant topics vectors for the person,labeled by its three top keywords 3. For each people topic a. Calculate the cosine similarity (optionally applying Pivoted Unique Pivoted Normalization) among the topic vector and content TF-IDF vectors b. Recommends more similar contents to person user topics, which user has not yet People Topic Modeling and Content Recommendations algorithm
- 51. Bloom Filter ● A space-efficient Probabilistic Data Structure used to test whether an element is a member of a set. ● False positive matches are possible, but false negatives are not. ● An empty Bloom filter is a bit array of m bits, all set to 0. ● Each inserted key is mapped to bits (which are all set to 1) by k different hash functions. The set {x,y,z} was inserted in Bloom Filter. w is not in the set, because it hashes to one bit equal to 0
- 52. Bloom Filter - Example Using cross_bloomfilter - Pure Python and Java compatible implementation GitHub: http://bit.ly/cross_bf
- 53. Bloom Filter - Complexity Analysis Ordered List Space Complexity: O(n) where n is the number of items in the set Check for key presence Time Complexity (binary search): O(log(n)) assuming an ordered list Example: For a list of 100,000 string keys, with an average length of 18 characters Key list size: 1,788,900 bytes Bloom filter size: 137,919 bytes (false positive rate = 0.5%) Bloom filter size: 18,043 bytes (false positive rate = 5%) (and you can gzip it!) Bloom Filter Space Complexity: O(t * ln(p)) where t is the maximum number of items to be inserted and p the accepted false positive rate Check for key presence Time Complexity: O(k) where k is a constant representing the number of hash functions to be applied to a string key
- 54. ● Distributed Graph Database ● Elastic and linear scalability for a growing data and user base ● Support for ACID and eventual consistency ● Backended by Cassandra or HBase ● Support for global graph data analytics, reporting, and ETL through integration with Spark, Hadoop, Giraph ● Support for geo and full text search (ElasticSearch, Lucene, Solr) ● Native integration with TinkerPop (Gremlin query language, Gremlin Server, ...) TinkerPop
- 55. Gremlin traversals g.V().has('CONTENT','id', 'Post:123') .outE('IS SIMILAR TO') .has('strength', gte(0.1)).as('e').inV().as('v') .select('e','v') .map{['id': it.get().v.values('id').next(), 'strength': it.get().e.values('strength').next()]} .limit(10) Querying similar contents [{‘id’: ‘Post:456’, ‘strength’: 0.672}, {‘id’: ‘Post:789’, ‘strength’: 0.453}, {‘id’: ‘Post:333’, ‘strength’: 0.235}, ...] Example output: Content Content IS SIMILAR TO 1 2 3 4 5 6 7
- 56. Gremlin traversals g.V().has('PERSON','id','Person:[email protected]') .out('IS ABOUT').has('number', 1) .inE('IS RECOMMENDED TO').filter{ it.get().value('strength') >= 0.1} .order().by('strength',decr).as('tc').outV().as('c') .select('tc','c') .map{ ['contentId': it.get().c.value('id'), 'recommendationStrength': it.get().tc.value('strength') * getTimeDecayFactor(it.get().c.value('updatedOn')) ] } Querying recommended contents for a person [{‘contentId’: ‘Post:456’, ‘strength’: 0.672}, {‘contentId’: ‘Post:789’, ‘strength’: 0.453}, {‘contentId’: ‘Post:333’, ‘strength’: 0.235}, ...] Example output: Person Topic IS ABOUT Content IS RECOMMENDED TO 1 2 3 4 5 6 7 8
- 57. Recommender Systems Topic Modeling Improvement of user experience for greater engagement Users’ interests segmentation Datasets summarization Personalized recommendations Wrap up
- 59. Thanks! Gabriel Moreira - @gspmoreira Gilmar Souza - @gilmarsouza Discovering Users’ Topics of Interest in Recommender Systems