Resilient Distributed Datasets
9 likes2,165 views

This document presents Resilient Distributed Datasets (RDDs), a fault-tolerant abstraction for in-memory cluster computing introduced by Spark. RDDs allow programmers to perform iterative and interactive computations over large datasets in a fault-tolerant manner. RDDs are distributed immutable collections of records that can be operated on through transformations and actions. They track the lineage of transformations to allow recovering lost data partitions. This provides an efficient abstraction for iterative algorithms compared to MapReduce.






























































Resilient Distributed Datasets
- 1. RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING MATEI ZAHARIA, MOSHARAF CHOWDHURY, TATHAGATA DAS, ANKUR DAVE, JUSTIN MA, MURPHY MCCAULEY, MICHAEL J. FRANKLIN, SCOTT SHENKER, ION STOICA. NSDI'12 PROCEEDINGS OF THE 9TH USENIX CONFERENCE ON NETWORKED SYSTEMS DESIGN AND IMPLEMENTATION PAPERS WE LOVE AMSTERDAM AUGUST 13, 2015 @gabriele_modena
- 2. (C) PRESENTATION BY GABRIELE MODENA, 2015 About me • CS.ML • Data science & predictive modelling • with a sprinkle of systems work • Hadoop & c. for data wrangling & crunching numbers • … and Spark
- 3. (C) PRESENTATION BY GABRIELE MODENA, 2015
- 4. (C) PRESENTATION BY GABRIELE MODENA, 2015 We present Resilient Distributed Datasets (RDDs), a distributed memory abstraction that lets programmers perform in-memory computations on large clusters in a fault- tolerant manner. RDDs are motivated by two types of applications that current computing frameworks handle inefficiently: iterative algorithms and interactive data mining tools.
- 5. (C) PRESENTATION BY GABRIELE MODENA, 2015 How • Review (concepts from) key related work • RDD + Spark • Some critiques
- 6. (C) PRESENTATION BY GABRIELE MODENA, 2015 Related work • MapReduce • Dryad • Hadoop Distributed FileSystem (HDFS) • Mesos
- 7. (C) PRESENTATION BY GABRIELE MODENA, 2015 What’s an iterative algorithm anyway? data = input data w = <target vector> for i in num_iterations: for item in data: update(w) Multiple input scans At each iteration, do something Update a shared data structure
- 8. (C) PRESENTATION BY GABRIELE MODENA, 2015 HDFS • GFS paper (2003) • Distributed storage (with replication) • Block ops • NameNode hashes file locations (blocks) Data Node Data Node Data Node Name Node
- 9. (C) PRESENTATION BY GABRIELE MODENA, 2015 HDFS • GFS paper (2003) • Distributed storage (with replication) • Block ops • NameNode hashes file locations (blocks) Data Node Data Node Data Node Name Node
- 10. (C) PRESENTATION BY GABRIELE MODENA, 2015 HDFS • GFS paper (2003) • Distributed storage (with replication) • Block ops • NameNode hashes file locations (blocks) Data Node Data Node Data Node Name Node
- 11. (C) PRESENTATION BY GABRIELE MODENA, 2015 MapReduce • Google paper (2004) • Apache Hadoop (~2007) • Divide and conquer functional model • Goes hand-in-hand with HDFS • Structure data as (key, value) 1. Map(): filter and project emit (k, v) pairs 2. Reduce(): aggregate and summarise group by key and count Map Map Map Reduce Reduce HDFS (blocks) HDFS
- 12. (C) PRESENTATION BY GABRIELE MODENA, 2015 MapReduce • Google paper (2004) • Apache Hadoop (~2007) • Divide and conquer functional model • Goes hand-in-hand with HDFS • Structure data as (key, value) 1. Map(): filter and project emit (k, v) pairs 2. Reduce(): aggregate and summarise group by key and count Map Map Map Reduce Reduce HDFS (blocks) HDFS This is a test Yes it is a test …
- 13. (C) PRESENTATION BY GABRIELE MODENA, 2015 MapReduce • Google paper (2004) • Apache Hadoop (~2007) • Divide and conquer functional model • Goes hand-in-hand with HDFS • Structure data as (key, value) 1. Map(): filter and project emit (k, v) pairs 2. Reduce(): aggregate and summarise group by key and count Map Map Map Reduce Reduce HDFS (blocks) HDFS This is a test Yes it is a test … (This,1), (is, 1), (a, 1), (test., 1), (Yes, 1), (it, 1), (is, 1)
- 14. (C) PRESENTATION BY GABRIELE MODENA, 2015 MapReduce • Google paper (2004) • Apache Hadoop (~2007) • Divide and conquer functional model • Goes hand-in-hand with HDFS • Structure data as (key, value) 1. Map(): filter and project emit (k, v) pairs 2. Reduce(): aggregate and summarise group by key and count Map Map Map Reduce Reduce HDFS (blocks) HDFS This is a test Yes it is a test … (This,1), (is, 1), (a, 1), (test., 1), (Yes, 1), (it, 1), (is, 1) (This, 1), (is, 2), (a, 2), (test, 2), (Yes, 1), (it, 1)
- 15. (C) PRESENTATION BY GABRIELE MODENA, 2015 (c) Image from Apache Tez http://tez.apache.org
- 16. (C) PRESENTATION BY GABRIELE MODENA, 2015 Critiques to MR and HDFS • Great when records (and jobs) are independent • In reality expect data to be shuffled across the network • Latency measured in minutes • Performance hit for iterative methods • Composability monsters • Meant for batch workflows
- 17. (C) PRESENTATION BY GABRIELE MODENA, 2015 Dryad • Microsoft paper (2007) • Inspired Apache Tez • Generalisation of MapReduce via I/O pipelining • Applications are (direct acyclic) graphs of tasks
- 18. (C) PRESENTATION BY GABRIELE MODENA, 2015 Dryad DAG dag = new DAG("WordCount"); dag.addVertex(tokenizerVertex) .addVertex(summerVertex) .addEdge(new Edge(tokenizerVertex, summerVertex, edgeConf.createDefaultEdgeProperty()) );
- 19. (C) PRESENTATION BY GABRIELE MODENA, 2015 MapReduce and Dryad SELECT a.country, COUNT(b.place_id) FROM place a JOIN tweets b ON (a. place_id = b.place_id) GROUP BY a.country; (c) Image from Apache Tez http://tez.apache.org. Modified.
- 20. (C) PRESENTATION BY GABRIELE MODENA, 2015 Critiques to Dryad • No explicit abstraction for data sharing • Must express data reps as DAG • Partial solution: DryadLINQ • No notion of a distributed filesystem • How to handle large inputs? • Local writes / remote reads?
- 21. (C) PRESENTATION BY GABRIELE MODENA, 2015 Resilient Distributed Datasets Read-only, partitioned collection of records => a distributed immutable array accessed via coarse-grained transformations => apply a function (scala closure) to all elements of the array Obj Obj Obj Obj Obj Obj Obj Obj Obj Obj Obj Obj
- 22. (C) PRESENTATION BY GABRIELE MODENA, 2015 Resilient Distributed Datasets Read-only, partitioned collection of records => a distributed immutable array accessed via coarse-grained transformations => apply a function (scala closure) to all elements of the array Obj Obj Obj Obj Obj Obj Obj Obj Obj Obj Obj Obj
- 23. (C) PRESENTATION BY GABRIELE MODENA, 2015 Spark • Transformations - lazily create RDDs wc = dataset.flatMap(tokenize) .reduceByKey(add) • Actions - execute computation wc.collect() Runtime and API
- 24. (C) PRESENTATION BY GABRIELE MODENA, 2015 Applications Driver Worker Worker Worker input data input data input data RAM RAM results tasks RAM
- 25. (C) PRESENTATION BY GABRIELE MODENA, 2015 Applications • Driver code defines RDDs and invokes actions Driver Worker Worker Worker input data input data input data RAM RAM results tasks RAM
- 26. (C) PRESENTATION BY GABRIELE MODENA, 2015 Applications • Driver code defines RDDs and invokes actions • Submit to long lived workers, that store partitions in memory Driver Worker Worker Worker input data input data input data RAM RAM results tasks RAM
- 27. (C) PRESENTATION BY GABRIELE MODENA, 2015 Applications • Driver code defines RDDs and invokes actions • Submit to long lived workers, that store partitions in memory • Scala closures are serialised as Java objects and passed across the network over HTTPDriver Worker Worker Worker input data input data input data RAM RAM results tasks RAM
- 28. (C) PRESENTATION BY GABRIELE MODENA, 2015 Applications • Driver code defines RDDs and invokes actions • Submit to long lived workers, that store partitions in memory • Scala closures are serialised as Java objects and passed across the network over HTTP • Variables bound to the closure are saved in the serialised object Driver Worker Worker Worker input data input data input data RAM RAM results tasks RAM
- 29. (C) PRESENTATION BY GABRIELE MODENA, 2015 Applications • Driver code defines RDDs and invokes actions • Submit to long lived workers, that store partitions in memory • Scala closures are serialised as Java objects and passed across the network over HTTP • Variables bound to the closure are saved in the serialised object • Closures are deserialised on each worker and applied to the RDD (partition) Driver Worker Worker Worker input data input data input data RAM RAM results tasks RAM
- 30. (C) PRESENTATION BY GABRIELE MODENA, 2015 Applications • Driver code defines RDDs and invokes actions • Submit to long lived workers, that store partitions in memory • Scala closures are serialised as Java objects and passed across the network over HTTP • Variables bound to the closure are saved in the serialised object • Closures are deserialised on each worker and applied to the RDD (partition) • Mesos takes care of resource management Driver Worker Worker Worker input data input data input data RAM RAM results tasks RAM
- 31. (C) PRESENTATION BY GABRIELE MODENA, 2015 Data persistance 1. in memory as deserialized java object 2. in memory as serialized data 3. on disk RDD Checkpointing Memory management via LRU eviction policy .persist() RDD for future reuse
- 32. (C) PRESENTATION BY GABRIELE MODENA, 2015 Lineage lines = spark.textFile(“hdfs://...") errors = lines.filter(_.startsWith("ERROR")) errors.persist() errors.filter(_.contains("HDFS")) .map(_.split(’t’)(3)) .collect()
- 33. (C) PRESENTATION BY GABRIELE MODENA, 2015 Lineage lines lines = spark.textFile(“hdfs://...") errors = lines.filter(_.startsWith("ERROR")) errors.persist() errors.filter(_.contains("HDFS")) .map(_.split(’t’)(3)) .collect()
- 34. (C) PRESENTATION BY GABRIELE MODENA, 2015 Lineage lines lines = spark.textFile(“hdfs://...") errors = lines.filter(_.startsWith("ERROR")) errors.persist() errors.filter(_.contains("HDFS")) .map(_.split(’t’)(3)) .collect() filter(_.startsWith("ERROR"))
- 35. (C) PRESENTATION BY GABRIELE MODENA, 2015 Lineage lines errors lines = spark.textFile(“hdfs://...") errors = lines.filter(_.startsWith("ERROR")) errors.persist() errors.filter(_.contains("HDFS")) .map(_.split(’t’)(3)) .collect() filter(_.startsWith("ERROR"))
- 36. (C) PRESENTATION BY GABRIELE MODENA, 2015 Lineage lines errors lines = spark.textFile(“hdfs://...") errors = lines.filter(_.startsWith("ERROR")) errors.persist() errors.filter(_.contains("HDFS")) .map(_.split(’t’)(3)) .collect() filter(_.startsWith("ERROR")) filter(_.contains(“HDFS”))
- 37. (C) PRESENTATION BY GABRIELE MODENA, 2015 Lineage lines errors hdfs errors lines = spark.textFile(“hdfs://...") errors = lines.filter(_.startsWith("ERROR")) errors.persist() errors.filter(_.contains("HDFS")) .map(_.split(’t’)(3)) .collect() filter(_.startsWith("ERROR")) filter(_.contains(“HDFS”))
- 38. (C) PRESENTATION BY GABRIELE MODENA, 2015 Lineage lines errors hdfs errors lines = spark.textFile(“hdfs://...") errors = lines.filter(_.startsWith("ERROR")) errors.persist() errors.filter(_.contains("HDFS")) .map(_.split(’t’)(3)) .collect() filter(_.startsWith("ERROR")) filter(_.contains(“HDFS”)) map(_.split(’t’)(3))
- 39. (C) PRESENTATION BY GABRIELE MODENA, 2015 Lineage lines errors hdfs errors time fields lines = spark.textFile(“hdfs://...") errors = lines.filter(_.startsWith("ERROR")) errors.persist() errors.filter(_.contains("HDFS")) .map(_.split(’t’)(3)) .collect() filter(_.startsWith("ERROR")) filter(_.contains(“HDFS”)) map(_.split(’t’)(3))
- 40. (C) PRESENTATION BY GABRIELE MODENA, 2015 Lineage lines errors hdfs errors time fields lines = spark.textFile(“hdfs://...") errors = lines.filter(_.startsWith("ERROR")) errors.persist() errors.filter(_.contains("HDFS")) .map(_.split(’t’)(3)) .collect() filter(_.startsWith("ERROR")) filter(_.contains(“HDFS”)) map(_.split(’t’)(3))
- 41. (C) PRESENTATION BY GABRIELE MODENA, 2015 Lineage lines errors hdfs errors time fields lines = spark.textFile(“hdfs://...") errors = lines.filter(_.startsWith("ERROR")) errors.persist() errors.filter(_.contains("HDFS")) .map(_.split(’t’)(3)) .collect() filter(_.startsWith("ERROR")) filter(_.contains(“HDFS”)) map(_.split(’t’)(3))
- 42. (C) PRESENTATION BY GABRIELE MODENA, 2015 Lineage Fault recovery If a partition is lost, derived it back from the lineage lines errors hdfs errors time fields lines = spark.textFile(“hdfs://...") errors = lines.filter(_.startsWith("ERROR")) errors.persist() errors.filter(_.contains("HDFS")) .map(_.split(’t’)(3)) .collect() filter(_.startsWith("ERROR")) filter(_.contains(“HDFS”)) map(_.split(’t’)(3))
- 43. (C) PRESENTATION BY GABRIELE MODENA, 2015 Representation Challenge: track lineage across transformations 1. Partitions 2. Data locality for partition p 3. List dependencies 4. Iterator function to compute a dataset based on its parents 5. Metadata for the partitioner scheme
- 44. (C) PRESENTATION BY GABRIELE MODENA, 2015 Narrow dependencies pipelined execution on one cluster node map, filter union
- 45. (C) PRESENTATION BY GABRIELE MODENA, 2015 Wide dependencies require data from all parent partitions to be available and to be shuffled across the nodes using a MapReduce-like operation groupByKey join with inputs not co-partitioned
- 46. (C) PRESENTATION BY GABRIELE MODENA, 2015 Scheduling Task are allocated based on data locality (delayed scheduling) 1. Action is triggered => compute the RDD 2. Based on lineage, build a graph of stages to execute 3. Each stage contains as many pipelined transformations with narrow dependencies as possible 4. Launch tasks to compute missing partitions from each stage until it has computed the target RDD 5. If a task fails => re-run it on another node as long as its stage’s parents are still available.
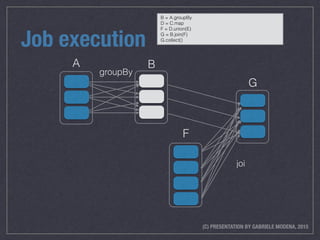
- 47. (C) PRESENTATION BY GABRIELE MODENA, 2015 Job execution union map groupBy join B C D E F G Stage 3Stage 2 A Stage 1
- 48. (C) PRESENTATION BY GABRIELE MODENA, 2015 Job execution union map groupBy join B C D E F G Stage 3Stage 2 A Stage 1 B = A.groupBy D = C.map F = D.union(E) G = B.join(F) G.collect()
- 49. (C) PRESENTATION BY GABRIELE MODENA, 2015 Job execution G B = A.groupBy D = C.map F = D.union(E) G = B.join(F) G.collect()
- 50. (C) PRESENTATION BY GABRIELE MODENA, 2015 Job execution join B F G B = A.groupBy D = C.map F = D.union(E) G = B.join(F) G.collect()
- 51. (C) PRESENTATION BY GABRIELE MODENA, 2015 Job execution join B F G groupBy A B = A.groupBy D = C.map F = D.union(E) G = B.join(F) G.collect()
- 52. (C) PRESENTATION BY GABRIELE MODENA, 2015 Job execution union D E join B F G groupBy A B = A.groupBy D = C.map F = D.union(E) G = B.join(F) G.collect()
- 53. (C) PRESENTATION BY GABRIELE MODENA, 2015 Job execution map C union D E join B F G groupBy A B = A.groupBy D = C.map F = D.union(E) G = B.join(F) G.collect()
- 54. (C) PRESENTATION BY GABRIELE MODENA, 2015 Job execution map C union D E join B F G groupBy A B = A.groupBy D = C.map F = D.union(E) G = B.join(F) G.collect()
- 55. (C) PRESENTATION BY GABRIELE MODENA, 2015 Job execution map C union D E join B F G groupBy A B = A.groupBy D = C.map F = D.union(E) G = B.join(F) G.collect()
- 56. (C) PRESENTATION BY GABRIELE MODENA, 2015 Job execution map C union D E join B F G groupBy A B = A.groupBy D = C.map F = D.union(E) G = B.join(F) G.collect()
- 57. (C) PRESENTATION BY GABRIELE MODENA, 2015 Job execution map C union D E join B F G groupBy A Stage 1 B = A.groupBy D = C.map F = D.union(E) G = B.join(F) G.collect()
- 58. (C) PRESENTATION BY GABRIELE MODENA, 2015 Job execution map C union D E join B F G Stage 2 groupBy A Stage 1 B = A.groupBy D = C.map F = D.union(E) G = B.join(F) G.collect()
- 59. (C) PRESENTATION BY GABRIELE MODENA, 2015 Job execution map C union D E join B F G Stage 3Stage 2 groupBy A Stage 1 B = A.groupBy D = C.map F = D.union(E) G = B.join(F) G.collect()
- 60. (C) PRESENTATION BY GABRIELE MODENA, 2015 Evaluation
- 61. (C) PRESENTATION BY GABRIELE MODENA, 2015 Some critiques (to the paper) Some critiques (to the paper) • How general is this approach? • We are still doing MapReduce • Concerns wrt iterative algorithms still stand • CPU bound workloads? • Linear Algebra? • How much tuning is required? • How does the partitioner work? • What is the cost of reconstructing an RDD from lineage? • Performance when data does not fit in memory • Eg. a join between two very large non co- partitioned RDDs
- 62. (C) PRESENTATION BY GABRIELE MODENA, 2015 References (Theory) Resilient distributed datasets: a fault-tolerant abstraction for in-memory cluster computing. Zaharia et. al, Proceedings of NSDI’12. https://www.cs.berkeley.edu/~matei/papers/2012/ nsdi_spark.pdf Spark: cluster computing with working sets. Zaharia et. al, Proceedings of HotCloud'10. http://people.csail.mit.edu/matei/papers/2010/hotcloud_spark.pdf The Google File System. Ghemawat, Gobioff, Leung, 19th ACM Symposium on Operating Systems Principles, 2003. http://research.google.com/archive/gfs.html MapReduce: Simplified Data Processing on Large Clusters. Dean, Ghemawat, OSDI'04: Sixth Symposium on Operating System Design and Implementation. http://research.google.com/archive/mapreduce.html Dryad: Distributed Data-Parallel Programs from Sequential Building Blocks Michael Isard, Mihai Budiu, Yuan Yu, Andrew Birrell, and Dennis Fetterly European Conference on Computer Systems (EuroSys), Lisbon, Portugal, March 21-23, 2007. http://research.microsoft.com/en-us/projects/dryad/eurosys07.pdf Mesos: a platform for fine-grained resource sharing in the data center, Hindman et. al, Proceedings of NSDI’11. https://www.cs.berkeley.edu/~alig/papers/mesos.pdf
- 63. (C) PRESENTATION BY GABRIELE MODENA, 2015 References (Practice) • An overview of the pyspark API through pictures https://github.com/jkthompson/ pyspark-pictures • Barry Brumitt’s presentation on MapReduce design patterns (UW CSE490) http://courses.cs.washington.edu/courses/cse490h/08au/lectures/ MapReduceDesignPatterns-UW2.pdf • The Dryad Project http://research.microsoft.com/en-us/projects/dryad/ • Apache Spark http://spark.apache.org • Apache Hadoop https://hadoop.apache.org • Apache Tez https://tez.apache.org • Apache Mesos http://mesos.apache.org