






























![Requirements – Stream Processing
§ A few seconds to minutes response times.
§ Need to be able to detect trends, thresholds, etc. across profiles.
§ Quick processing more important than 100% accuracy.
By Sprocket2cog (Own work) [CC BY-SA 3.0 (http://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons](https://image.slidesharecdn.com/haafdfinal-150929113010-lva1-app6892/85/Architecting-applications-with-Hadoop-Fraud-Detection-32-320.jpg)
































































![Spark Streaming Example
1. val conf = new SparkConf().setMaster(local[2]”)
2. val ssc = new StreamingContext(conf, Seconds(1))
3. val lines = ssc.socketTextStream(localhost, 9999)
4. val words = lines.flatMap(_.split( ))
5. val pairs = words.map(word = (word, 1))
6. val wordCounts = pairs.reduceByKey(_ + _)
7. wordCounts.print()
8. SSC.start()](https://image.slidesharecdn.com/haafdfinal-150929113010-lva1-app6892/85/Architecting-applications-with-Hadoop-Fraud-Detection-97-320.jpg)
![Spark Streaming Example
1. val conf = new SparkConf().setMaster(local[2]”)
2. val sc = new SparkContext(conf)
3. val lines = sc.textFile(path, 2)
4. val words = lines.flatMap(_.split( ))
5. val pairs = words.map(word = (word, 1))
6. val wordCounts = pairs.reduceByKey(_ + _)
7. wordCounts.print()](https://image.slidesharecdn.com/haafdfinal-150929113010-lva1-app6892/85/Architecting-applications-with-Hadoop-Fraud-Detection-98-320.jpg)





![HBase-‐Spark
Module
val hbaseContext = new HBaseContext(sc, config);
hbaseContext.bulkDelete[Array[Byte]](rdd,
tableName,
putRecord = new Delete(putRecord),
4);
val hbaseContext = new HBaseContext(sc, config)
rdd.hbaseBulkDelete(hbaseContext,
tableName,
putRecord = new Delete(putRecord),
4)](https://image.slidesharecdn.com/haafdfinal-150929113010-lva1-app6892/85/Architecting-applications-with-Hadoop-Fraud-Detection-104-320.jpg)

![HBase-Spark Module
val hbaseContext = new HBaseContext(sc, config)
rdd.hbaseForeachPartition(hbaseContext, (it, conn) = {
val bufferedMutator = conn.getBufferedMutator(TableName.valueOf(t1))
...
bufferedMutator.flush()
bufferedMutator.close()
})
val getRdd = rdd.hbaseMapPartitions(hbaseContext, (it, conn) = {
val table = conn.getTable(TableName.valueOf(t1))
var res = mutable.MutableList[String]()
...
})](https://image.slidesharecdn.com/haafdfinal-150929113010-lva1-app6892/85/Architecting-applications-with-Hadoop-Fraud-Detection-106-320.jpg)











































Architecting applications with Hadoop - Fraud Detection
- 1. Hadoop Application Architectures: Fraud Detection Strata + Hadoop World, New York 2015 tiny.cloudera.com/app-arch-new-york Gwen Shapira | @gwenshap Jonathan Seidman | @jseidman Ted Malaska | @ted_malaska Mark Grover | @mark_grover
- 2. Logistics § Break at 10:30-11:00 AM § Questions at the end of each section § Slides at tiny.cloudera.com/app-arch-new-york § Code at https://github.com/hadooparchitecturebook/fraud- detection-tutorial
- 4. About the presenters § Principal Solutions Architect at Cloudera § Previously, lead architect at FINRA § Contributor to Apache Hadoop, HBase, Flume, Avro, Pig and Spark § Senior Solutions Architect/ Partner Enablement at Cloudera § Contributor to Apache Sqoop. § Previously, Technical Lead on the big data team at Orbitz, co-founder of the Chicago Hadoop User Group and Chicago Big Data Ted Malaska Jonathan Seidman
- 5. About the presenters § System Architect at Confluent § Committer on Apache Kafka, Sqoop § Contributor to Apache Flume § Software Engineer at Cloudera § Committer on Apache Bigtop, PMC member on Apache Sentry(incubating) § Contributor to Apache Spark, Hadoop, Hive, Sqoop, Pig, Flume Gwen Shapira Mark Grover
- 6. Case Study Overview Fraud Detection
- 7. Credit Card Transaction Fraud
- 10. How Do We React § Human Brain at Tennis - Muscle Memory - Fast Thought - Slow Thought
- 11. § Rejected transactions § Real time alerts § Real time dashboard § Platform for automated learning and improvement – real time and batch § Audit trail and analytics for human feedback Results:
- 12. Why is Hadoop a great fit?
- 13. Hadoop § In traditional sense - HDFS (append-only file system) - MapReduce (really slow but robust execution engine) § Is not a great fit
- 14. Why is Hadoop a Great Fit? § But the Hadoop ecosystem is! § More than just MapReduce + YARN + HDFS
- 15. Volume § Have to maintain millions of profiles § Retain transaction history § Make and keep track of automated rule changes
- 16. Velocity § Events arriving concurrently and at high velocity § Make decisions in real-time
- 17. Variety § Maintain simple counters in profile (e.g. purchase thresholds) § Iris or finger prints that need to be matched
- 18. Challenges of Hadoop Implementation
- 19. Challenges of Hadoop Implementation
- 20. Challenges - Architectural Considerations § Storing state (for real-time decisions): - Local Caching? Distributed caching (e.g. Memcached)? Distributed storage (e.g. HBase)? § Profile Storage - HDFS? HBase? § Ingestion frameworks (for events): - Flume? Kafka? Sqoop? § Processing engines (for background processing): - Storm? Spark? Trident? Flume interceptors? § Data Modeling § Orchestration - Do we still need it for real-time systems?
- 22. But First… Real-Time? Near Real-Time? Stream Processing?
- 23. Some Definitions § Real-time – well, not really. Most of what we’re talking about here is… § Near real-time: - Stream processing – continual processing of incoming data. - Alerting – immediate (well, as fast as possible) responses to incoming events. Getting closer to real-time. Data Sources Extract Transform Load Stream Processing millisecondsseconds Alerts ! Typical Hadoop Processing – Minutes to Hours Fraud Detection
- 24. Requirements – Storage/Modeling § Need long term storage for large volumes of profile, event, transaction, etc. data.
- 25. Requirements – Storage/Modeling § Need to be able to quickly retrieve specific profiles and respond quickly to incoming events.
- 26. Requirements – Storage/Modeling § Need to store sufficient data to analyze whether or not fraud is present.
- 27. Requirements – Alerts § Need to be able to respond to incoming events quickly (milliseconds). § Need high throughput and low latency. § Processing requirements are minimal.
- 29. Requirements – Ingestion § Reliable – we don’t want to lose events. event event,event,event,event,event,event… event event event event
- 30. Requirements – Ingestion § Support for multiple targets. Storage Data Sources
- 31. Requirements – Ingestion § Needs to support high throughput of large volumes of events.
- 32. Requirements – Stream Processing § A few seconds to minutes response times. § Need to be able to detect trends, thresholds, etc. across profiles. § Quick processing more important than 100% accuracy. By Sprocket2cog (Own work) [CC BY-SA 3.0 (http://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons
- 33. Requirements – Batch Processing § Non real-time, “off-line”, exploratory processing and reporting. § Data needs to be available for analysts and users to analyze with tools of choice – SQL, MapReduce, etc. § Results need to be able to feed back into NRT processing to adjust rules, etc. "Parmigiano reggiano factory". Licensed under CC BY-SA 3.0 via Commons - https://commons.wikimedia.org/wiki/File:Parmigiano_reggiano_factory.jpg#/media/File:Parmigiano_reggiano_factory.jpg
- 35. Hadoop Cluster II Storage Batch Processing Hadoop Cluster I Flume (Sink) HBase and/or Memory Store HDFS HBase Impala Map/Reduce Spark Automated & Manual Analytical Adjustments and Pattern detection Fetching & Updating Profiles/Rules Batch Time Adjustments NRT/Stream Processing Spark Streaming Adjusting NRT stats Kafka Events Reporting Flume (Source) Interceptor(Rules) Flume (Source) Flume (Source) Interceptor (Rules) Kafka Alerts/Events Flume Channel Events Alerts Hadoop Cluster I HBase and/or Memory Store
- 37. Storage Layer Considerations § Two likely choices for long-term storage of data:
- 38. Data Storage Layer Choices § Stores data directly as files § Fast scans § Poor random reads/writes § Stores data as Hfiles on HDFS § Slow scans § Fast random reads/writes
- 39. Storage Considerations § Batch processing and reporting requires access to all raw and processed data. § Stream processing and alerting requires quickly fetching and saving profiles.
- 40. Data Storage Layer Choices § For ingesting raw data. § Batch processing, also some stream processing. § For reading/writing profiles. § Fast random reads and writes facilitates quick access to large number of profiles.
- 41. But… Is HBase fast enough for fetching profiles? HBase and/or Memory StoreFetching & Updating Profiles/Rules Flume (Source) Interceptor(Rules) Flume (Source) Flume (Source) Interceptor (Rules) Hadoop Cluster I HBase and/or Memory Store
- 43. Caching Options § Local in-memory cache (on-heap, off-heap). § Remote cache - Distributed cache (Memcached, Oracle Coherence, etc.) - HBase BlockCache
- 44. § Allows us to keep recently used data blocks in memory. § Note that this will require recent versions of HBase and specific configurations on our cluster. Caching – HBase BlockCache
- 45. Hadoop Cluster II Storage Batch Processing Hadoop Cluster I Flume (Sink) HBase and/or Memory Store HDFS HBase Impala Map/Reduce Spark Automated & Manual Analytical Adjustments and Pattern detection Fetching & Updating Profiles/Rules Batch Time Adjustments NRT/Stream Processing Spark Streaming Adjusting NRT stats Kafka Events Reporting Flume (Source) Interceptor(Rules) Flume (Source) Flume (Source) Local Cache (Profiles) Kafka Alerts/Events Flume Channel Events Alerts Hadoop Cluster I HBase and/or Memory Store Our Storage Choices
- 47. Tables HBase Data Modeling Considerations Row Key ColumnValues
- 48. HBase Data Modeling Considerations § Tables - Minimize # of Tables - Reduce/Remove Joins - # Region - Split policy
- 49. HBase Data Modeling Considerations § RowKeys - Location Location Location - Salt is good for you
- 50. HBase Data Modeling Considerations
- 51. What is a Salt # # # # Date Time Date Time Math.asb(DateTime.hash() % numOfSplits)
- 52. Scan a Salted Table Mapper Region Server Region Mapper Region Mapper Region Server Region Mapper Region
- 53. Scan a Salted Table Mapper RegionServer Region Filter Mapper Region 0001 0001 0002 0002 0002 … Filtering on Client
- 54. Scan a Salted Table Region 0001 Filtered Needed Filtered Filtered Filtered Filtered 0002 Filtered Needed Filtered Filtered Filtered Filtered … Filtered Needed Filtered Filtered Filtered Filtered 0060 Filtered Needed Filtered Filtered Filtered Filtered Mapper (One Big Scan)
- 55. Scan a Salted Table Region 0001 Filtered Needed Filtered Filtered Filtered Filtered 0002 Filtered Needed Filtered Filtered Filtered Filtered … Filtered Needed Filtered Filtered Filtered Filtered 0060 Filtered Needed Filtered Filtered Filtered Filtered Mapper (Scan Per Salt)
- 56. HBase Data Modeling Considerations § Columns - Mega Columns - Single Value Columns - Millions of Columns - Increment Values
- 57. Ingest and Near Real- Time Alerting Considerations
- 58. Where does data come from? § Device profile database – IP address, access attempts… § Device history – previous access attempts, remote IP’s… § Transaction stream Our Application
- 59. The basic workflow Network Device Network Events Queue Event Handler Data Store Fetch & Update Profiles Here is an event. Is is authorized? Queue
- 60. The Queue § What makes Apache Kafka a good choice? - Low latency - High throughput - Partitioned and replicated - Easy to plug to applications
- 61. The Basics § Messages are organized into topics § Producers push messages § Consumers pull messages § Kafka runs in a cluster. Nodes are called brokers
- 62. Topics, Partitions and Logs
- 63. Each partition is a log
- 64. Each Broker has many partitions Partition 0 Partition 0 Partition 1 Partition 1 Partition 2 Partition 1 Partition 0 Partition 2 Partion 2
- 65. Producers load balance between partitions Partition 0 Partition 1 Partition 2 Partition 1 Partition 0 Partition 2 Partition 0 Partition 1 Partion 2 Client
- 66. Producers load balance between partitions Partition 0 Partition 1 Partition 2 Partition 1 Partition 0 Partition 2 Partition 0 Partition 1 Partion 2 Client
- 67. Consumers Consumer Group Y Consumer Group X Consumer Kafka Cluster Topic Partition A (File) Partition B (File) Partition C (File) Consumer Consumer Consumer Order retained within partition Order retained with in partition but not over partitions OffSetX OffSetX OffSetX OffSetYOffSetYOffSetY Offsets are kept per consumer group
- 68. In our use-case § Topic for profile updates § Topic for current events § Topic for alerts § Topic for rule updates Partitioned by device ID
- 69. The event handler § Very basic pattern: - Consume a record - “do something to it” - Produce zero, one, or more results Kafka Processor Pattern
- 70. Easier than you think § Kafka provides load balancing and availability - Add processes when needed – they will get their share of partitions - You control partition assignment strategy - If a process crashes, partitions will get automatically reassigned - You control when an event is “done” - Send events safely and asynchronously § So you focus on the use-case, not the framework
- 71. Inside The Processor Flume Source Flume Source Kafka Events Topic Flume Source Flume Interceptor Event Processing Logic Local Memory HBase Client Kafka Alerts Topic KafkaConsumer KafkaProducer HBase Kafka Profile/Rules Updates Topic Kafka Rules Topic
- 72. Scaling the Processor Flume Source Flume Source Kafka Initial Events Topic Flume Source Flume Interceptor Event Processing Logic Local Memory HBase Client Kafka Alerts Topic HBase KafkaConsumer KafkaProducer Events Topic Partition A Partition B Partition C Producer Partitioner Producer Partitioner Producer Partitioner Better use of local memory Kafka Profile/Rules Topic Profile/Rules Topic Partition A
- 73. Processor Deployment Simple and Scalable
- 74. Choosing Processor Deployment Flume • Part of Hadoop • Easy to configure • Not so easy to scale Yarn • Part of Hadoop • Implement processor inside Yarn app • Add resources as needed - Scalable • Not easy. Chef / Puppet / Ansible • Part of Devops • Easy to configure • Somewhat easy to scale • Can be dockerized Our choice for this example Solid choiceAdvanced users
- 75. Ingest – Gateway to deep analytics § Data needs to end up in: - SparkStreaming - Can read directly from Kafka - HBase - HDFS
- 76. Considerations for Ingest § Async – nothing can slow down the immediate reaction - Always ingest the data from a queue in separate thread or process to avoid write-latency § Useful end-points – integrates with variety of data sources and sinks § Supports standard formats and possibly some transformations - Data format inside the queue can be different than in the data store For example Avro - Parquet § Cross data center
- 77. More considerations - Safety § Reliable – data loss is not acceptable - Either “at-least-once” or “exactly-once” - When is “exactly-once” possible? § Error handling – reasonable reaction to unreasonable data § Security – Authentication, authorization, audit, lineage
- 78. Anti-Pattern Using complex event processing framework for ingest Don’t do that. Ingest is different.
- 79. Good Patterns § Ingest all things. Events, evidence, alerts - It has potential value - Especially when troubleshooting - And for data scientists § Make sure you take your schema with you - Yes, your data probably has a schema - Everyone accessing the data (web apps, real time, stream, batch) will need to know about it - So make it accessible in a centralized schema registry
- 80. Choosing Ingest Flume • Part of Hadoop • Key-value based • Supports HDFS and HBase • Easy to configure • Serializers provide conversions • At-least once delivery guarantee • Proven in huge production environments Copycat • Part of Apache Kafka • Schema preserving • Supports HDFS + Hive • Well integrated support for Parquet, Avro and JSON • Exactly-once delivery guarantee • Easy to manage and scale • Provides back-pressure Our choice for this example
- 81. Ingestion - Flume Flume HDFS Sink Kafka Cluster Topic Partition A Partition B Partition C Sink Sink Sink HDFS Flume SolR Sink Sink Sink Sink SolR Flume HBase Sink Sink Sink Sink HBase
- 82. Ingestion - Copycat Kafka Cluster Topic Partition A Partition B Partition C Offsets Configuration Schemata Copycat Worker Convertalizer Connector HDFS Copycat Worker Convertalizer Connector Copycat Worker Convertalizer Connector
- 84. Do we really need HBase? § What if… Kafka would store all information used for real-time processing? Network Device Network Events Queue Event handler Fetch Update Profiles Here is an event. Is is authorized?
- 85. Log Compaction in Kafka § Kafka stores a “change log” of profiles § But we want the latest state § log.cleanup.policy = {delete / compact}
- 86. Do we really need Spark Streaming? § What if… we could do low-latency single event processing and complex stream processing analytics in the same system? Network Device Network Events Queue Event handler Data StoreQueue Spark Streaming Adjust rules and statistics Do we really need two of these?
- 87. Is complex processing of single events possible? § The challenge: - Low latency vs high throughput - No data loss - Windows, aggregations, joins - Late data
- 88. Solutions? § Apache Flink - Process each event, checkpoint in batches - Local and distributed state, also checkpointed § Apache Samza - State is persisted to Kafka (Change log pattern) - Local state cached in RocksDB § Kafka Streams - Similar to Samza - But in simple library that is part of Apache Kafka. - Late data as updates to state
- 89. You Probably Don’t Need Orchestration
- 91. Hadoop Cluster II Storage Batch Processing Hadoop Cluster I Flume (Sink) HBase and/or Memory Store HDFS HBase Impala Map/Reduce Spark Automated Manual Analytical Adjustments and Pattern detection Fetching Updating Profiles/Rules Batch Time Adjustments NRT/Stream Processing Spark Streaming Adjusting NRT stats Kafka Events Reporting Flume (Source) Interceptor(Rules) Flume (Source) Flume (Source) Interceptor (Rules) Kafka Alerts/Events Flume Channel Events Alerts Hadoop Cluster I HBase and/or Memory Store Reminder: Full Architecture
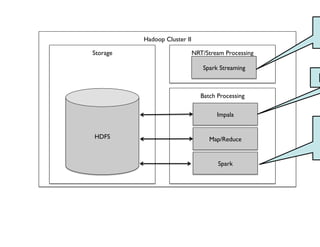
- 92. Processing Hadoop Cluster II Storage Batch Processing HDFS Impala Map/Reduce Spark NRT/Stream Processing Spark Streaming
- 93. Two Kinds of Processing Streaming Batch NRT/Stream Processing Spark Streaming Batch Processing Impala Map/Reduce Spark
- 95. Stream Processing Options 1. Storm 2. Spark Streaming
- 96. Why Spark Streaming? § There’s one engine to know. § Micro-batching helps you scale reliably. § Exactly once counting § Hadoop ecosystem integration is baked in. § No risk of data loss. § It’s easy to debug and run. § State management § Huge eco-system backing § You have access to ML libraries. § You can use SQL where needed.
- 97. Spark Streaming Example 1. val conf = new SparkConf().setMaster(local[2]”) 2. val ssc = new StreamingContext(conf, Seconds(1)) 3. val lines = ssc.socketTextStream(localhost, 9999) 4. val words = lines.flatMap(_.split( )) 5. val pairs = words.map(word = (word, 1)) 6. val wordCounts = pairs.reduceByKey(_ + _) 7. wordCounts.print() 8. SSC.start()
- 98. Spark Streaming Example 1. val conf = new SparkConf().setMaster(local[2]”) 2. val sc = new SparkContext(conf) 3. val lines = sc.textFile(path, 2) 4. val words = lines.flatMap(_.split( )) 5. val pairs = words.map(word = (word, 1)) 6. val wordCounts = pairs.reduceByKey(_ + _) 7. wordCounts.print()
- 99. DStream DStream DStream Spark Streaming Single Pass Source Receiver RDD Source Receiver RDD RDD Filter Count Print Source Receiver RDD RDD RDD Single Pass Filter Count Print First Batch Second Batch
- 100. DStream DStream DStream Single Pass Source Receiver RDD Source Receiver RDD RDD Filter Count Print Source Receiver RDD partitions RDD Parition RDD Single Pass Filter Count Pre-first Batch First Batch Second Batch Stateful RDD 1 Print Stateful RDD 2 Stateful RDD 1 Spark Streaming
- 101. HBase-Spark Module • HBASE-‐13992 -‐ Integrate SparkOnHBase into HBase • HBASE-‐14150 -‐ Add BulkLoad func:onality to HBase-‐Spark Module • HBASE-‐14158 -‐ Add documenta:on for Ini:al Release for HBase-‐Spark Module integra:on • HBASE-‐14159 -‐ Resolve warning introduced by HBase-‐Spark module • HBASE-‐14181 -‐ Add Spark DataFrame DataSource to HBase-‐Spark Module • HBASE-‐14184 -‐ Fix inden:on and type-‐o in JavaHBaseContext • HBASE-‐14340 -‐ Add second bulk load op:on to Spark Bulk Load to send puts as the value • Many more coming
- 102. Spark Streaming and HBase Driver Configs Executor Static Space HConnection Tasks Tasks Tasks Tasks Executor Static Space HConnection Tasks Tasks Tasks Tasks
- 103. HBase-Spark Module • BulkPut • BulkDelete • BulkGet • BulkLoad (Wide and Tail) • ForeachParFFon(It, Conn) • MapParFFon(it, Conn) • Spark SQL
- 104. HBase-‐Spark Module val hbaseContext = new HBaseContext(sc, config); hbaseContext.bulkDelete[Array[Byte]](rdd, tableName, putRecord = new Delete(putRecord), 4); val hbaseContext = new HBaseContext(sc, config) rdd.hbaseBulkDelete(hbaseContext, tableName, putRecord = new Delete(putRecord), 4)
- 105. HBase-Spark Module val hbaseContext = new HBaseContext(sc, config) rdd.hbaseBulkDelete(tableName)
- 106. HBase-Spark Module val hbaseContext = new HBaseContext(sc, config) rdd.hbaseForeachPartition(hbaseContext, (it, conn) = { val bufferedMutator = conn.getBufferedMutator(TableName.valueOf(t1)) ... bufferedMutator.flush() bufferedMutator.close() }) val getRdd = rdd.hbaseMapPartitions(hbaseContext, (it, conn) = { val table = conn.getTable(TableName.valueOf(t1)) var res = mutable.MutableList[String]() ... })
- 107. HBase-Spark Module rdd.hbaseBulkLoad (tableName, t = { Seq((new KeyFamilyQualifier(t.rowKey, t.family, t.qualifier), t.value)). iterator }, stagingFolder)
- 108. HBase-Spark Module val df = sqlContext.load(org.apache.hadoop.hbase.spark, Map(hbase.columns.mapping - KEY_FIELD STRING :key, A_FIELD STRING c:a, B_FIELD STRING c:b,, hbase.table - t1)) df.registerTempTable(hbaseTmp) sqlContext.sql(SELECT KEY_FIELD FROM hbaseTmp + WHERE + (KEY_FIELD = 'get1' and B_FIELD '3') or + (KEY_FIELD = 'get3' and B_FIELD = '8')).foreach(r = println( - + r))
- 109. Demo Architecture Generator Kafka Spark Streaming ??? Impala SparkSQL Spark MlLib SparkSQL
- 110. New Hadoop Storage Option Use case break up Structured Data SQL + Scan Use Cases Unstructured Data Deep Storage Scan Use Cases Fixed Columns Schemas SQL + Scan Use Cases Any Type of Column Schemas Gets / Puts / Micro Scans
- 111. New Hadoop Storage Option Use case break up Structured Data SQL + Scan Use Cases Unstructured Data Deep Storage Scan Use Cases Fixed Columns Schemas SQL + Scan Use Cases Any Type of Column Schemas Gets / Puts / Micro Scans
- 112. Real-Time Analytics with Kudu Demo Generator Kafka Spark Streaming Kudu Impala SparkSQL Spark MlLib SparkSQL
- 113. Kudu and Spark hIps://github.com/tmalaska/SparkOnKudu Same Development From HBase-‐Spark is now on Kudu and Spark • Full Spark RDD integra:on • Full Spark Streaming integra:on • Ini:al SparkSQL integra:on
- 114. Processing Batch
- 115. Why batch in a NRT use case? § For background processing - To be later used for quick decision making § Exploratory analysis - Machine Learning § Automated rule changes - Based on new patterns § Analytics - Who’s attacking us?
- 116. Processing Engines (Past) § Hadoop = HDFS (distributed FS) + MapReduce (Processing engine)
- 118. Processing Engines § MapReduce § Abstractions § Spark § Impala
- 119. MapReduce § Oldie but goody § Restrictive Framework / Innovative Work Arounds § Extreme Batch
- 120. MapReduce Basic High Level Mapper HDFS (Replicated) Native File System Block of Data Temp Spill Data Partitioned Sorted Data Reducer Reducer Local Copy Output File Remotereadfor allbut1node
- 121. Abstractions § SQL - Hive § Script/Code - Pig: Pig Latin - Crunch: Java/Scala - Cascading: Java/Scala
- 122. Spark § The New Kid that isn’t that New Anymore § Easily 10x less code § Extremely Easy and Powerful API § Very good for iterative processing (machine learning, graph processing, etc.) § Scala, Java, and Python support § RDDs
- 123. Spark - DAG
- 124. Spark - DAG Filter KeyBy KeyBy TextFile TextFile Join Filter Take
- 125. Spark - DAG Filter KeyBy KeyBy TextFile TextFile Join Filter Take Good Good Good Good Good Good Good-Replay Good-Replay Good-Replay Good Good-Replay Good Good-Replay Lost Block Replay Good-Replay Lost Block Good Future Future Future Future
- 126. Is Spark replacing Hadoop? § Spark is an execution engine - Much faster than MR - Easier to program § Spark is replacing MR
- 127. Impala § MPP Style SQL Engine on top of Hadoop § Very Fast § High Concurrency § Analytical windowing functions
- 128. Impala – Broadcast Join Impala Daemon Smaller Table Data Block 100% Cached Smaller Table Smaller Table Data Block Impala Daemon 100% Cached Smaller Table Impala Daemon 100% Cached Smaller Table Impala Daemon Hash Join Function Bigger Table Data Block 100% Cached Smaller Table Output Impala Daemon Hash Join Function Bigger Table Data Block 100% Cached Smaller Table Output Impala Daemon Hash Join Function Bigger Table Data Block 100% Cached Smaller Table Output
- 129. Impala – Partitioned Hash Join Impala Daemon Smaller Table Data Block ~33% Cached Smaller Table Smaller Table Data Block Impala Daemon ~33% Cached Smaller Table Impala Daemon ~33% Cached Smaller Table Hash Partitioner Hash Partitioner Impala Daemon BiggerTable Data Block Impala Daemon Impala Daemon Hash Partitioner Hash Join Function 33% Cached Smaller Table Hash Join Function 33% Cached Smaller Table Hash Join Function 33% Cached Smaller Table Output Output Output BiggerTable Data Block Hash Partitioner BiggerTable Data Block Hash Partitioner
- 130. Presto § Facebook’s SQL engine replacement for Hive § Written in Java § Doesn’t build on top of MapReduce § Very few commercial vendors supporting it
- 131. Batch processing in our use-case
- 132. Batch processing in fraud-detection § Reporting - How many events come daily? - How does it compare to last year? § Machine Learning - Automated rules changes § Complex event processing - Tracking device history and updating profiles
- 133. Reporting § Need a fast JDBC-compliant SQL framework § Impala or Hive or Presto? § We choose Impala - Fast - Highly concurrent - JDBC/ODBC support
- 134. Machine Learning § Options - MLLib (with Spark) - Oryx - H2O - Mahout § We recommend MLLib because of larger use of Spark in our architecture.
- 135. Other Batch Processing § Options: - MapReduce - Spark § We choose Spark - Much faster than MR - Easier to write applications due to higher level API - Re-use of code between streaming and batch
- 136. Do we really need HDFS? § What if… Impala, Spark, and Hive could efficiently scan and analyze data in HBase?
- 138. Hadoop Cluster II Storage Batch Processing Hadoop Cluster I Flume (Sink) HBase and/or Memory Store HDFS HBase Impala Map/Reduce Spark Automated Manual Analytical Adjustments and Pattern detection Fetching Updating Profiles/Rules Batch Time Adjustments NRT/Stream Processing Spark Streaming Adjusting NRT stats Kafka Events Reporting Flume (Source) Interceptor(Rules) Flume (Source) Flume (Source) Interceptor (Rules) Kafka Alerts/Events Flume Channel Events Alerts Hadoop Cluster I HBase and/or Memory Store
- 139. Hadoop Cluster II Storage Batch Processing Hadoop Cluster I Flume (Sink) HBase and/or Memory Store HDFS HBase Impala Map/Reduce Spark Automated Manual Analytical Adjustments and Pattern detection Fetching Updating Profiles/Rules Batch Time Adjustments NRT/Stream Processing Spark Streaming Adjusting NRT stats Kafka Events Reporting Flume (Source) Interceptor(Rules) Flume (Source) Flume (Source) Interceptor (Rules) Kafka Alerts/Events Flume Channel Events Alerts Hadoop Cluster I HBase and/or Memory Store Storage
- 140. HDFS Raw and Processed Events HBase Profiles (Disk/Cache) Local Cache Profiles
- 141. Hadoop Cluster II Storage Batch Processing Hadoop Cluster I Flume (Sink) HBase and/or Memory Store HDFS HBase Impala Map/Reduce Spark Automated Manual Analytical Adjustments and Pattern detection Fetching Updating Profiles/Rules Batch Time Adjustments NRT/Stream Processing Spark Streaming Adjusting NRT stats Kafka Events Reporting Flume (Source) Interceptor(Rules) Flume (Source) Flume (Source) Interceptor (Rules) Kafka Alerts/Events Flume Channel Events Alerts Hadoop Cluster I HBase and/or Memory Store NRT Processing/Alerting
- 142. Flume Source Flume Source Kafka Transactions Topic Flume Source Flume Interceptor Event Processing Logic Local Memory HBase Client Kafka Replies Topic KafkaConsumer KafkaProducer HBase Kafka Updates Topic Kafka Rules Topic
- 143. Hadoop Cluster II Storage Batch Processing Hadoop Cluster I Flume (Sink) HBase and/or Memory Store HDFS HBase Impala Map/Reduce Spark Automated Manual Analytical Adjustments and Pattern detection Fetching Updating Profiles/Rules Batch Time Adjustments NRT/Stream Processing Spark Streaming Adjusting NRT stats Kafka Events Reporting Flume (Source) Interceptor(Rules) Flume (Source) Flume (Source) Interceptor (Rules) Kafka Alerts/Events Flume Channel Events Alerts Hadoop Cluster I HBase and/or Memory Store Ingestion
- 144. Flume HDFS Sink Kafka Cluster Topic Partition A Partition B Partition C Sink Sink Sink HDFS Flume SolR Sink Sink Sink Sink SolR Flume Hbase Sink Sink Sink Sink HBase
- 145. Hadoop Cluster II Storage Batch Processing Hadoop Cluster I Flume (Sink) HBase and/or Memory Store HDFS HBase Impala Map/Reduce Spark Automated Manual Analytical Adjustments and Pattern detection Fetching Updating Profiles/Rules Batch Time Adjustments NRT/Stream Processing Spark Streaming Adjusting NRT stats Kafka Events Reporting Flume (Source) Interceptor(Rules) Flume (Source) Flume (Source) Interceptor (Rules) Kafka Alerts/Events Flume Channel Events Alerts Hadoop Cluster I HBase and/or Memory Store Processing
- 146. Hadoop Cluster II Storage Batch Processing HDFS Impala Map/Reduce Spark NRT/Stream Processing Spark Streaming Reporting Stream Processing Batch, ML, etc.
- 147. Demo!
- 148. Where else to find us?
- 149. Other Batch Processing § Ask Us Anything session – Thursday, 11:20 – noon § Book signing – Wednesday, 6:05pm
- 150. Thank you! @hadooparchbook tiny.cloudera.com/app-arch-new-york Gwen Shapira | @gwenshap Jonathan Seidman | @jseidman Ted Malaska | @ted_malaska Mark Grover | @mark_grover