PySpark on Kubernetes @ Python Barcelona March Meetup
3 likes15,427 views

The document outlines a presentation by Holden Karau on utilizing Apache Spark with Kubernetes for big data processing, highlighting Spark's advantages, advancements in Kubernetes, and how to transition workflows to Kubernetes. It covers technical aspects, integration with Python, and offers resources for further learning and support in this area. Additionally, there are links to recorded demos and upcoming events related to Spark and Kubernetes.



















![How to change to running on Kubernetes?
In theory “just”:
--master yarn to --master k8s://[...]
In practice:
● Build a container with your dependencies
● Possibly change your storage (HDFS to S3 or GCS)
● Change your cluster manager
● Re-do your tuning work
Hisashi](https://image.slidesharecdn.com/pythonbcn-sparkonkubernetes3-190321173149/85/PySpark-on-Kubernetes-Python-Barcelona-March-Meetup-22-320.jpg)












PySpark on Kubernetes @ Python Barcelona March Meetup
- 1. Big Data w/Python On Kubernetes & Apache Spark with @holdenkarau
- 2. Slides will be at: http://bit.ly/2FifqdM CatLoversShow
- 3. Holden: ● My name is Holden Karau ● Prefered pronouns are she/her ● Developer Advocate at Google ● Apache Spark PMC ● co-author of Learning Spark & High Performance Spark ● Twitter: @holdenkarau ● Slide share http://www.slideshare.net/hkarau ● Code review livestreams: https://www.twitch.tv/holdenkarau / https://www.youtube.com/user/holdenkarau ● Spark Talk Videos http://bit.ly/holdenSparkVideos ● Talk feedback (if you are so inclined): http://bit.ly/holdenTalkFeedback
- 5. What is going to be covered: ● What is Spark ● What is Kubernetes ● How it’s different from YARN and other similar systems we use Spark on ● How “simple” it is to switch cluster managers ○ Plus the not so simple (where’s my HDFS and auto-scaling?) ● Links to recorded demos because I'm tired ● A brief detour in Kubeflow ● Future work and directions Andrew
- 6. What is Spark? ● General purpose distributed system ○ With a really nice API including Python :) ● Apache project (one of the most active) ● Must faster than Hadoop Map/Reduce ● Good when too big for a single machine ● Built on top of two abstractions for distributed data: RDDs & Datasets
- 7. Why people come to Spark: Well this MapReduce job is going to take 16 hours - how long could it take to learn Spark? dougwoods
- 8. Why people come to Spark: My DataFrame won’t fit in memory on my cluster anymore, let alone my MacBook Pro :( Maybe this Spark business will solve that... brownpau
- 9. Part of what lead to the success of Spark ● Integrated different tools which traditionally required different systems ○ Mahout, hive, etc. ● e.g. can use same system to do ML and SQL *Often written in Python! Apache Spark SQL, DataFrames & Datasets Structured Streaming Scala, Java, Python, & R Spark ML bagel & Graph X MLLib Scala, Java, PythonStreaming Graph Frames Paul Hudson
- 10. PySpark: ● The Python interface to Spark ● Fairly mature, integrates well-ish into the ecosystem, less a Pythonrific API ● Has some serious performance hurdles from the design ● Same general technique used as the bases for the other non JVM implementations in Spark ○ C# ○ R ○ Julia ○ Javascript - surprisingly different
- 11. Yes, we have wordcount! :p lines = sc.textFile(src) words = lines.flatMap(lambda x: x.split(" ")) word_count = (words.map(lambda x: (x, 1)) .reduceByKey(lambda x, y: x+y)) word_count.saveAsTextFile(output) No data is read or processed until after this line This is an “action” which forces spark to evaluate the RDD These are still combined and executed in one python executor Trish Hamme
- 12. So what does that look like? Driver py4j Worker 1 Worker K pipe pipe
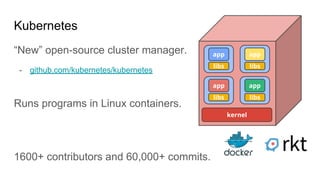
- 13. Kubernetes “New” open-source cluster manager. - github.com/kubernetes/kubernetes Runs programs in Linux containers. 1600+ contributors and 60,000+ commits.
- 14. Kubernetes “New” open-source cluster manager. - github.com/kubernetes/kubernetes libs app kernel libs app libs app libs app Runs programs in Linux containers. 1600+ contributors and 60,000+ commits.
- 15. More isolation is good Kubernetes provides each program with: ● a lightweight virtual file system -- Docker image ○ an independent set of S/W packages ● a virtual network interface ○ a unique virtual IP address ○ an entire range of ports Aleksei I
- 16. Other isolation layers ● Separate process ID space ● Max memory limit ● CPU share throttling ● Mountable volumes ○ Config files -- ConfigMaps ○ Credentials -- Secrets ○ Local storages -- EmptyDir, HostPath ○ Network storages -- PersistentVolumes Jarek Reiner
- 17. Dependencies ● Spark alone isn’t enough ● Think: spacy, sci-kit learn, tensorflow, etc. ● YARN: Shared conda env, but supporting different version is hard Fuzzy Gerdes
- 18. Kubernetes architecture node A node B Pod 1 Pod 2 Pod 3 10.0.0.2 196.0.0.5 196.0.0.6 10.0.0.3 10.0.1.2 Pod, a unit of scheduling and isolation. ● runs a user program in a primary container ● holds isolation layers like a virtual IP in an infra container Robbt
- 19. Big Data on Kubernetes Since Spark 2.3, the community has been working on a few important new features that make Spark on Kubernetes more usable and ready for a broader spectrum of use cases: ● non-JVM binding support and memory customization ● client-mode support for running interactive apps ● Kerberos support ● large framework refactors: rm init-container; scheduler The Last Cookie
- 20. Spark on Kubernetes Spark Core Kubernetes Scheduler Backend Kubernetes Clusternew executors remove executors configuration • Resource Requests • Authnz • Communication with K8s babbagecabbage
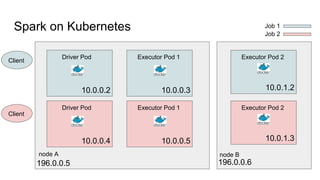
- 21. Spark on Kubernetes node A node B Driver Pod Executor Pod 1 Executor Pod 2 10.0.0.2 196.0.0.5 196.0.0.6 10.0.0.3 10.0.1.2 Client Client Driver Pod Executor Pod 1 Executor Pod 2 10.0.0.4 10.0.0.5 10.0.1.3 Job 1 Job 2
- 22. How to change to running on Kubernetes? In theory “just”: --master yarn to --master k8s://[...] In practice: ● Build a container with your dependencies ● Possibly change your storage (HDFS to S3 or GCS) ● Change your cluster manager ● Re-do your tuning work Hisashi
- 23. Demo: Everyone loves wordcount! It’s big data which means we have to do WordCount Recorded demo - https://youtu.be/jaIU2VCTv88 Hisashi
- 24. Demo #2: Wordcount in client mode on K8s Recorded demo - https://youtu.be/s2aU81Zyq9E Luxus M
- 25. Demo #3: Wordcount in a notebook on K8s Everyone loves notebooks, except ops, qa and your very stressed out data engineers. Recorded demo - https://youtu.be/eMj0Pv1-Nfo Tim (Timothy) Pearce
- 26. What do we need to do next? ● Support dynamic scaling ● Storage? ● Better auth integration ● Better documentation (ugh client mode) ● Want to help? Check out my slides on how to contribute: http://bit.ly/2OeQl7w Hisashi
- 27. Dynamic Scaling: ● Need a seperate shuffle service ● We could do smart scale down maybe - https://github.com/apache/spark/pull/19045 Jennifer C.
- 28. Related talks & blog posts ● Running custom Spark on GKE and Azure - https://www.oreilly.com/ideas/how-to-run-a-custom-version-of-spark-on-hoste d-kubernetes ● Deploying Spark on Kubernetes - http://spark.apache.org/docs/latest/running-on-kubernetes.html ● Getting PySpark 2.4 working on GKE recorded livestream - https://www.youtube.com/watch?v=3j9D7B6PE60 Interested in OSS (especially Spark)? ● Check out my Twitch & Youtube for livestreams - http://twitch.tv/holdenkarau & https://www.youtube.com/user/holdenkarau Becky Lai
- 29. Unrelated: Kubeflow workshop ● Kubeflow is a tool for building end-to-end machine learning workflows on Kubernetes. It supports Spark* ● Trevor & I are doing a workshop @ Strata SF and we'd love to trick offer the option to do a self-guided to try a self-guided version free of charge of course and provide us feedback. I can get cloud credits for you to try ● What you will might learn: ○ Installing Kubeflow ○ Setting up a project ○ Deploying that project to GCP / Azure / IBM ○ Monkeying around with a project and still having it work ● Please come and talk to me if interested. I'm wearing a dress with unicorns *in the master branch as of February fionasjournal
- 30. Learning Spark Fast Data Processing with Spark (Out of Date) Fast Data Processing with Spark (2nd edition) Advanced Analytics with Spark Spark in Action High Performance SparkLearning PySpark
- 31. High Performance Spark! Available today, nothing on Kubernetes, but that should not stop you from buying several copies (if you have an expense account). Cat’s love it! Amazon sells it: http://bit.ly/hkHighPerfSpark :D
- 32. Sign up for the mailing list @ http://www.distributedcomputing4kids.com
- 33. And some upcoming talks: ● March ○ Strata San Francisco -- next week ● April ○ Spark Summit ● May ○ KiwiCoda Mania ● June ○ Scala Days EU ● July ○ OSCON Portland ○ Skills Matter in London
- 34. Sparkling Pink Panda Scooter group photo by Kenzi k thnx bye! (or questions…) If you want to fill out a survey: http://bit.ly/holdenTestingSpark Give feedback on this presentation http://bit.ly/holdenTalkFeedback I'll be in the hallway or you can email me: [email protected]