Using druid for interactive count distinct queries at scale @ nmc

This document discusses Nielsen's use of Druid for interactive count-distinct queries at scale. It describes Nielsen's need to calculate unique devices encountered over date ranges and attributes in real time from large volumes of streaming data. Previous attempts using Elasticsearch were slow and inefficient. Druid uses sketch algorithms like ThetaSketch to approximate distinct counts quickly while balancing speed and accuracy. It has a columnar data store that allows fast roll-up queries of pre-aggregated sketches. Nielsen was able to reduce query times from hours to milliseconds and costs from $80k to $55k per month by ingesting data into Druid instead of Elasticsearch. The document provides guidelines for setting up, monitoring, modeling data, optimizing queries, and batch ingest




















Using druid for interactive count distinct queries at scale @ nmc
- 1. Yakir Buskilla + Itai Yaffe Nielsen USING DRUID FOR INTERACTIVE COUNT-DISTINCT QUERIES AT SCALE
- 2. Introduction Yakir Buskilla Itai Yaffe ● Software Architect ● Focusing on Big Data and Machine Learning problems ● Big Data Infrastructure Developer ● Dealing with Big Data challenges for the last 5 years
- 3. Nielsen Marketing Cloud (NMC) ● eXelate was acquired by Nielsen 2 years ago ● A leader in the Ad Tech and Marketing Tech industry ● What do we do ? ○ Data as a Service (DaaS) ○ Software as a Service (SaaS)
- 5. The need ● Nielsen Marketing Cloud business question ○ How many unique devices we have encountered: ■ over a given date range ■ for a given set of attributes (segments, regions, etc.) ● Find the number of distinct elements in a data stream which may contain repeated elements in real time
- 6. The need
- 7. The need
- 8. ● Store everything ● Store only 1 bit per device ○ 10B Devices-1.25 GB/day ○ 10B Devices*80K attributes - 100 TB/day ● Approximate Possible solutions Naive Bit VectorApprox.
- 9. Our journey ● Elasticsearch ○ Indexing data ■ 250 GB of daily data, 10 hours ■ Affect query time ○ Querying ■ Low concurrency ■ Scans on all the shards of the corresponding index
- 10. What we tried ● Preprocessing ● Statistical algorithms (e.g HyperLogLog)
- 11. ● K Minimum Values (KMV) ● Estimate set cardinality ● Supports set-theoretic operations X Y ● ThetaSketch mathematical framework - generalization of KMV X Y ThetaSketch
- 12. KMV intuition
- 13. Number of Std Dev 1 2 Confidence Interval 68.27% 95.45% 16,384 0.78% 1.56% 32,768 0.55% 1.10% 65,536 0.39% 0.78% ThetaSketch error
- 14. “Very fast highly scalable columnar data-store” DRUID
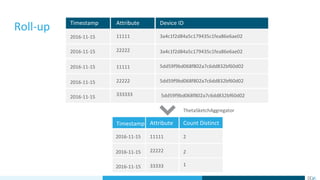
- 15. Roll-up ThetaSketchAggregator 2016-11-15 Timestamp Attribute Device ID 11111 3a4c1f2d84a5c179435c1fea86e6ae02 2016-11-15 22222 3a4c1f2d84a5c179435c1fea86e6ae02 2016-11-15 11111 5dd59f9bd068f802a7c6dd832bf60d02 2016-11-15 22222 5dd59f9bd068f802a7c6dd832bf60d02 2016-11-15 333333 5dd59f9bd068f802a7c6dd832bf60d02 Timestamp Attribute Count Distinct 2016-11-15 2016-11-15 2016-11-15 11111 22222 33333 2 2 1
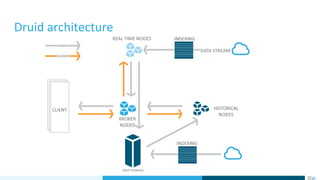
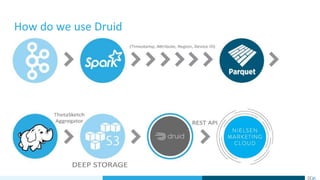
- 17. How do we use Druid
- 18. Guidelines and pitfalls ● Setup is not easy
- 19. Guidelines and pitfalls ● Monitoring your system
- 20. Guidelines and pitfalls ● Data modeling ○ Reduce the number of intersections ○ Different datasources for different use cases 2016-11-15 2016-11-15 2016-11-15 Timestamp Attribute Count Distinct Timestamp Attribute Region Count Distinct US XXXXXX US Porsche Intent XXXXXX Porsche Intent ... ...... XXXXXX ...
- 21. Guidelines and pitfalls ● Query optimization ○ Combine multiple queries into single query ○ Use filters
- 22. Guidelines and pitfalls ● Batch Ingestion ○ EMR Tuning ■ 140-nodes cluster ● 85% spot instances => ~80% cost reduction ○ Druid input file format - Parquet vs CSV ■ Reduced indexing time by X4 ■ Reduced used storage by X10
- 23. Guidelines and pitfalls ● Community
- 24. Summary 10TB/day 4 Hours/day 15GB/day 280ms-350ms $55K/month DRUID 250GB/day 10 Hours/day 2.5TB (total) 500ms-6000ms $80K/month ES
- 25. THANK YOU!
Editor's Notes
- #3: Intro of us + NMC
- #4: Daas = marketplace for device level data connecting buyers and sellers Saas - Nielsen Marketing cloud platform which help brands to connect with their customers by using our big data sets and our analytics tools
- #5: Our serving layer(Front End) aggregates data from various online + offline sources We aggregate around 10B events per day
- #6: Past… Mention “cardinality” and “real-time dashboard” Explain the need to union and intersect
- #9: -Bit vector - Elastic search /Redis is an example of such system
- #10: We tried to introduce new cluster dedicated for indexing only and then use backup and restore to the second cluster This method was very expensive and was partially helpful Tuning for better performance also didn’t help too much
- #11: Preprocessing - Too many combinations - The formula length is not bounded (show some numbers) HyperLogLog -Implementation in ElasticSearch was too slow (done on query time) - Set operations increase the error dramatically
- #12: Unions and Intersections increase the error The problematic case is intersection of very small set with very big set
- #14: The larger the K the smaller the Error However larger K means more memory & storage needed
- #15: So we talked about statistical algorithms, which is nice, but we needed a practical solution… OOTB supports ThetaSketch algorithm
- #16: Timeseries database - first thing you need to know about Druid Column types : Timestamp Dimensions Metrics Together they comprise a Datasource Agg is done on ingestion time (outcome is much smaller in size) In query time, it’s closer to a key-value search
- #17: We have 3 types of processes - ingestion, querying, management All processes are decoupled and scalable Ingestion (real time - e.g from Kafka, batch - talk about deep storage, how data is aggregated in ingestion time) Querying (brokers, historicals, query performance during ingestion) Lambda architecture
- #18: Explain the tuple and what is happening during the aggregation
- #19: Setup is not easy Separate config/servers/tuning Caused the deployment to take a few months Use the Druid recommendation for Production configuration
- #20: Monitoring Your System Druid has built in support for Graphite ( exports many metrics )
- #21: Data Modeling If using Theta sketch - reduce the number of intersections (show a slide of the old and new data model). It didn’t solve all use-cases, but it gives you an idea of how you can approach the problem Different datasources - e.g lower accuracy for faster queries VS higher accuracy with a bit slower queries
- #22: Combine multiple queries over the REST API There can be billions of rows, so filter the data as part of the query
- #23: EMR tuning (spot instances (80% cost reduction), druid MR prod config) Use Parquet The picture here - maybe money??
- #25: Ingestion doesn’t affect query + sub-second response for even 100s or 1000s of concurrent queries Cost is for the entire solution (Druid cluster, EMR, etc.) With Druid and ThetaSketch, we’ve improved our ingestion volume and query performance and concurrency by an order of magnitude with a lesser cost, compared to our old solution (We’ve achieved a more performant, scalable, cost-effective solution)