IMC Summit 2016 Breakout - Roman Shtykh - Apache Ignite as a Data Processing Hub
Download as PPTX, PDF4 likes1,189 views

The document discusses Apache Ignite as a robust data processing hub, highlighting its capabilities in real-time transaction and analytics on large datasets. It details integration techniques with Apache Flume and Apache Kafka for data streaming, log aggregation, and building scalable and reliable data pipelines. The emphasis is placed on the high performance, reliability, and flexibility of combining these technologies for effective data management in applications like internet ads and gaming services.






































IMC Summit 2016 Breakout - Roman Shtykh - Apache Ignite as a Data Processing Hub
- 1. APACHE IGNITE AS A DATA PROCESSING HUB ROMAN SHTYKH CYBERAGENT, INC. See all the presentations from the In-Memory Computing Summit at http://imcsummit.org
- 2. INTRODUCTION
- 3. ABOUT ME Roman Shtykh R&D Engineer at CyberAgent, Inc. Areas of focus Data streaming and NLP Committer on the Apache Ignite and MyBatis projects Judoka @rshtykh
- 4. CYBERAGENT, INC. Internet ads Games Media Investing 25% 13% 52% 3% 7% Games Media Internet ads Investing Other * As of Sep 2015
- 5. AMEBA SERVICES ・ Monthly visitors (DUB total): 6 billion* ・ Number of member users : about 39 million* CyberAgent, Inc. Ameba Services * As of Dec 2014 • Games • Community services • Content curation • Other
- 7. CONTENTS Apache Ignite Feed your data Log Aggregation with Apache Flume Integration with Apache Ignite Streaming Data with Apache Kafka Data Pipeline with Kafka and Ignite: Example
- 8. APACHE IGNITE “High-performance, integrated and distributed in-memory platform for computing and transacting on large-scale data sets in real-time, orders of magnitude faster than possible with traditional disk-based or flash-based technologies.” High performance, unlimited scalability and resiliency High-performance transactions and fast analytics Hadoop Acceleration, Apache Spark Apache project https://ignite.apache.org/
- 9. MAKING APACHE IGNITE A DATA PROCESSING HUB Question: How to feed data? A simple solution: Create a client node
- 10. MAKING APACHE IGNITE A DATA PROCESSING HUB Question: How to feed data? A simple solution: Create a client node Is it reliable? Does it scale? Ignite-only solution? Does it keep your operational costs low?
- 11. MAKING APACHE IGNITE A DATA PROCESSING HUB Question: How to feed data? A simple solution: Create a client node Is it reliable? Does it scale? Ignite-only solution? Does it keep your operational costs low?
- 13. LOG AGGREGATION WITH APACHE FLUME Flume “Distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data.” Scalable Flexible Robust and fault tolerant Declarative configuration Apache project
- 14. DATA FLOW IN FLUME Source Sink Agent ChannelIncoming data to another Agent or Destination
- 15. DATA FLOW IN FLUME (REPLICATION/MULTIPLEXING) Source Sink Agent Channel Incoming data SinkChannelChannel Selector
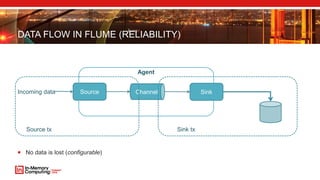
- 16. DATA FLOW IN FLUME (RELIABILITY) No data is lost (configurable) Source Sink Agent ChannelIncoming data Source tx Sink tx
- 17. LOG TRANSFER AT AMEBA Ameba Service Aggregato r Aggregato r Aggregat or Monitoring Recommend er System Elastic Search Hadoop Batch processing HBase Stream Processing (Onix) Stream Processing (HBaseSink) Ameba Service Ameba Service
- 18. LOG TRANSFER AT AMEBA Web Hosts More than 1600 Size 5.0 TB/day (raw) Traffic at peak 160Mbps (compressed)
- 19. IGNITE SINK Reads Flume events from a channel With a user-implemented pluggable transformer converts them into cacheable entries Adding it requires no modification to the existing architecture
- 20. FLUME ⇒ IGNITE (1) Source Ignite Sink Agent ChannelIncoming data new connection
- 21. FLUME ⇒ IGNITE (2) Source Ignite Sink Agent ChannelIncoming data Sink tx start tx
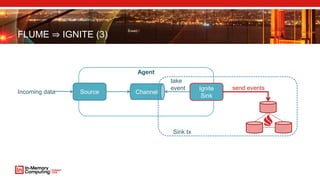
- 22. FLUME ⇒ IGNITE (3) Source Ignite Sink Agent ChannelIncoming data Sink tx take event send events
- 23. ENABLING FLUME SINK Steps 1. Implement EventTransformer convert Flume events into cacheable entries (java.util.Map<K, V>) 2. Put transformer’s jar to ${FLUME_HOME}/plugins.d/ignite/lib 3. Put IgniteSink and Ignite core jar files to ${FLUME_HOME}/plugins.d/ignite/libext 4. Set up a Flume agent Sink setup a1.sinks.k1.type = org.apache.ignite.stream.flume.IgniteSink a1.sinks.k1.igniteCfg = /some-path/ignite.xml a1.sinks.k1.cacheName = testCache a1.sinks.k1.eventTransformer = my.company.MyEventTransformer a1.sinks.k1.batchSize = 100
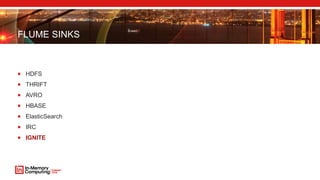
- 24. FLUME SINKS HDFS THRIFT AVRO HBASE ElasticSearch IRC IGNITE
- 25. APACHE FLUME & APACHE IGNITE If you do data aggregation with Flume Adding an Ignite cluster is as simple as writing a simple data transformer and deploying a new Flume agent If you store your data (and do computations) in Ignite Improving data injection becomes easy with Flume sink Combining Apache Flume and Ignite makes/keeps your data pipeline (both aggregation and processing) Scalable Reliable Highly-Performant
- 26. STREAMING DATA WITH APACHE KAFKA
- 27. APACHE KAFKA “Publish-subscribe messaging rethought as a distributed commit log” Low latency High Throughput Partitioned and Replicated Kafka is an essential component of any data pipeline today http://kafka.apache.org/
- 28. APACHE KAFKA Messages are grouped in topics Each partition is a log Each partition is managed by a broker (when replicated, one broker is the partition leader) Producers & consumers (consumer groups) Used for Log aggregation Activity tracking Monitoring Stream processing http://kafka.apache.org/documentation.html
- 29. KAFKA CONNECT Designed for large scale stream data integration using Kafka Provides an abstraction from communication with your Kafka cluster Offset management Delivery semantics Fault tolerance Monitoring, etc. Worker (scalability & fault tolerance) Connector (task config) Task (thread) Standalone & Distributed execution models http://www.confluent.io/blog/apache-kafka-0.9-is-released
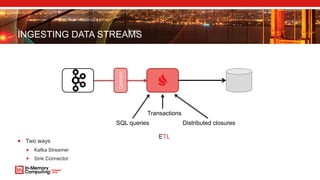
- 30. INGESTING DATA STREAMS Two ways Kafka Streamer Sink Connector SQL queries Distributed closures Transactions Connect ETL
- 31. STREAMING VIA SINK CONNECTOR Configure your connector Configure Kafka Connect worker Start your connector # connector name=my-ignite-connector connector.class=IgniteSinkConnector tasks.max=2 topics=someTopic1,someTopic2 # cache cacheName=myCache cacheAllowOverwrite=true igniteCfg=/some-path/ignite.xml $ bin/connect-standalone.sh myconfig/connect-standalone.properties myconfig/ignite-connector.properties
- 32. STREAMING VIA SINK CONNECTOR Easy data pipeline Records from Kafka are written to Ignite grid via high-performance IgniteDataStreamer At-least-once delivery guarantee As of 1.6, start a new connector to write to a different cache a b c d e 0 1 2 … Kafka offsets a.key, a.val b.key, b.val … a2 b2 c2 d2 e2
- 33. INGESTING DATA STREAMS Bi-directional streaming SQL queries Distributed closures Transactions Connect Events Continuous queries ConnectSin k Sourc e
- 34. STREAMING BACK TO KAFKA Listening to cache events PUT READ REMOVED EXPIRED, etc. Remote filtering can be enabled Kafka Connect offsets are ignored Currently, no delivery guarantees evt1 evt2 evt3 as records
- 35. ENABLING SOURCE CONNECTOR Configure your connector Define a remote filter if needed cacheFilterCls=MyCacheEventFilter Make sure that event listening is enabled on the server nodes Configure Kafka Connect worker Start your connector #connector name=ignite-src-connector connector.class=org.apache.ignite.stream.kafka.connect.IgniteSourceConn ector tasks.max=2 #topics, events topicNames=test cacheEvts=put,removed #cache cacheName=myCache igniteCfg=myconfig/ignite.xml key.converter=org.apache.kafka.connect.storage.StringConverter value.converter=org.apache.ignite.stream.kafka.connect.serialization.CacheEventCo nverter
- 36. APACHE KAFKA & APACHE IGNITE If you do data streaming with Kafka Adding an Ignite cluster is as simple as writing a configuration file (and creating a filter if you need it for source) If you store your data (and do computations) in Ignite Improving data injection and listening for events on data becomes easy with Kafka Connectors Combining Apache Kafka and Ignite makes/keeps your data pipeline Scalable Reliable Highly-Performant Covers a wide range of ETL contexts
- 37. DATA PIPELINE WITH KAFKA AND IGNITE EXAMPLE
- 38. DATA PIPELINE WITH KAFKA AND IGNITE Requirements instant processing and analysis scalable and resilient to failures low latency high throughput flexibility
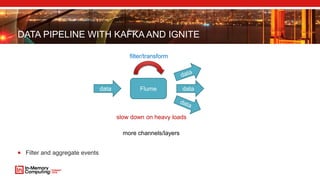
- 39. DATA PIPELINE WITH KAFKA AND IGNITE Filter and aggregate events data Flume filter/transform data slow down on heavy loads more channels/layers
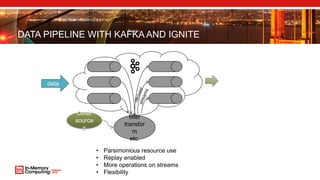
- 40. DATA PIPELINE WITH KAFKA AND IGNITE data filter transfor m etc. • Parsimonious resource use • Replay enabled • More operations on streams • Flexibility Other source s
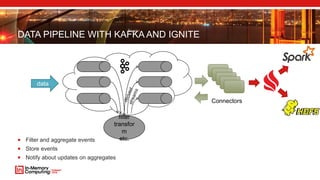
- 41. DATA PIPELINE WITH KAFKA AND IGNITE Filter and aggregate events Store events Notify about updates on aggregates data filter transfor m etc. Connectors
- 42. DATA PIPELINE WITH KAFKA AND IGNITE Filter and aggregate events Store events Notify about updates on aggregates data filter transfor m etc. Connectors
- 43. DATA PIPELINE WITH KAFKA AND IGNITE Improving ads delivery clicks impressions ads Ads delivery Ads recommender storage/ computatio n Image storage data & computation in one place
- 44. DATA PIPELINE WITH KAFKA AND IGNITE Improving ads delivery Better network utilization and reliability clicks impression s ads Ads delivery Ads recommende r storage/ computatio n Image storag e Anomaly detection
- 46. OTHER COMPLETED INTEGRATIONS CAMEL MQTT STORM FLINK SINK TWITTER
- 47. THE END