Ling liu part 01:big graph processing
1 like620 views

This document discusses challenges in processing large graphs and introduces an approach called GraphLego. It describes how GraphLego models large graphs as 3D cubes partitioned into slices, strips and dices to balance parallel computation. GraphLego optimizes access locality by minimizing disk access and compressing partitions. It also uses regression-based learning to optimize partitioning parameters and runtime. The document evaluates GraphLego on real-world graphs, finding it outperforms existing single-machine graph processing systems in execution efficiency and partitioning decisions.




![Scale of Big Graphs
• Social Scale: 1 billion vertices, 100 billion edges
– adjacency matrix: >108 GB
– adjacency list: >103GB
– edge list: >103GB
• Web Scale: 50 billion vertices, 1 trillion edges
– adjacency matrix: >1011 GB
– adjacency list: > 104 GB
– edge list: > 104 GB
• Brain Scale: 100 billion vertices, 100 trillion edges
– adjacency matrix: >1020 GB
– adjacency list: > 106 GB
– edge list: > 106 GB 5
1 terabyte (TB) =1,024GB ~103GB
1 petabyte (PB) =1,024TB ~ 106GB
1 exabyte (EB) =1,024PB~109GB
1 zettabyte (ZB) =1,024EB~1012GB.
1 yottabyte (YB) =1,024ZB~1015GB.
[Paul Burkhardt, Chris Waring 2013]](https://image.slidesharecdn.com/lingliu-part01biggraphprocessing-160616082617/85/Ling-liu-part-01-big-graph-processing-5-320.jpg)


![How do we store and process graphs?
• Conventional approach is to store and compute
in-memory.
– SHARED-MEMORY
• Parallel Random Access Machine (PRAM)
• data in globally-shared memory
• implicit communication by updating memory
• fast-random access
– DISTRIBUTED-MEMORY
• Bulk Synchronous Parallel (BSP)
• data distributed to local, private memory
• explicit communication by sending messages
• easier to scale by adding more machines
8
[Paul Burkhardt, Chris Waring 2013]](https://image.slidesharecdn.com/lingliu-part01biggraphprocessing-160616082617/85/Ling-liu-part-01-big-graph-processing-8-320.jpg)
![Top Super Computer
Installations
9
[Paul Burkhardt, Chris Waring 2013]](https://image.slidesharecdn.com/lingliu-part01biggraphprocessing-160616082617/85/Ling-liu-part-01-big-graph-processing-9-320.jpg)

![HPDC’15
11
Existing Graph Processing Systems
• Single PC Systems
– GraphLab [Low et al., UAI'10]
– GraphChi [Kyrola et al., OSDI'12]
– X-Stream [Roy et al., SOSP'13]
– TurboGraph [Han et al., KDD‘13]
– GraphLego [Zhou, Liu et al., ACM HPDC‘15]
• Distributed Shared Memory Systems
– Pregel [Malewicz et al., SIGMOD'10]
– Giraph/Hama – Apache Software Foundation
– Distributed GraphLab [Low et al., VLDB'12]
– PowerGraph [Gonzalez et al., OSDI'12]
– SPARK-GraphX [Gonzalez et al., OSDI'14]
– PathGraph [Yuan et.al, IEEE SC 2014]
– GraphMap [LeeLiu et al. IEEE SC 2015]](https://image.slidesharecdn.com/lingliu-part01biggraphprocessing-160616082617/85/Ling-liu-part-01-big-graph-processing-11-320.jpg)

![Parallel Graph Processing:
Opportunities
• Extend Existing Paradigms
– Vertex centric
– Edge centric
• BUILD NEW FRAMEWORKS!
– Centralized Approaches
• GraphLego [ACM HPDC 2015] / GraphTwist [VLDB2015]
– Distributed Approaches
• GraphMap [IEEE SC 2015], PathGraph [IEEE SC 2014]
13](https://image.slidesharecdn.com/lingliu-part01biggraphprocessing-160616082617/85/Ling-liu-part-01-big-graph-processing-13-320.jpg)




















![7/28/15
HPDC’15
35
Experimental Evaluation
• Computer server
– Intel Core i5 2.66 GHz, 16 GB RAM, 1 TB hard drive, Linux 64-bit
• Graph parallel systems
– GraphLab [Low et al., UAI'10]
– GraphChi [Kyrola et al., OSDI'12]
– X-Stream [Roy et al., SOSP'13]
• Graph applications](https://image.slidesharecdn.com/lingliu-part01biggraphprocessing-160616082617/85/Ling-liu-part-01-big-graph-processing-35-320.jpg)






Ling liu part 01:big graph processing
- 1. Ling Liu Distributed Data Intensive Systems Lab (DiSL) School of Computer Science Georgia Institute of Technology Joint work with Yang Zhou, Kisung Lee, Qi Zhang
- 2. Why Graph Processing? Graphs are everywhere! 2.84 PB adjacency list 2.84 PB edge list Human connectome. Gerhard et al., Frontiers in Neuroinformatics 5(3), 2011 2 NA = 6.022 ⇥ 1023 mol 1 Paul Burkhardt, Chris Waring An NSA Big Graph experiment
- 3. Graphs • Real information networks are represented as graphs and analyzed using graph theory – Internet – Road networks – Utility Grids – Protein Interactions • A graph is – a collection of binary relationships, or – networks of pairwise interactions, including social networks, digital networks. 3
- 4. Why Distributed Graph Processing? They are getting bigger!
- 5. Scale of Big Graphs • Social Scale: 1 billion vertices, 100 billion edges – adjacency matrix: >108 GB – adjacency list: >103GB – edge list: >103GB • Web Scale: 50 billion vertices, 1 trillion edges – adjacency matrix: >1011 GB – adjacency list: > 104 GB – edge list: > 104 GB • Brain Scale: 100 billion vertices, 100 trillion edges – adjacency matrix: >1020 GB – adjacency list: > 106 GB – edge list: > 106 GB 5 1 terabyte (TB) =1,024GB ~103GB 1 petabyte (PB) =1,024TB ~ 106GB 1 exabyte (EB) =1,024PB~109GB 1 zettabyte (ZB) =1,024EB~1012GB. 1 yottabyte (YB) =1,024ZB~1015GB. [Paul Burkhardt, Chris Waring 2013]
- 6. Classifications of Graphs • Simple Graphs v.s. Multigraphs – Simple graph: allow only one edge per pair of vertices – Multigraph: allow multiple parallel edges between pairs of vertices • Small Graphs v.s. Big Graphs – Small graph: can fit whole graph and its processing in main memory – Big Graph: cannot fit the whole graph and its processing in main memory 6
- 7. How hard it can be? • Difficult to parallelize (data/computation) – irregular data access increases latency – skewed data distribution creates bottlenecks • giant component • high degree vertices, highly skewed edge weight distribution • Increased size imposes greater challenge . . . – Latency – resource contention (i.e. hot-spotting) • Algorithm complexity really matters! – Run-time of O(n2) on a trillion node graph is not practical! 7
- 8. How do we store and process graphs? • Conventional approach is to store and compute in-memory. – SHARED-MEMORY • Parallel Random Access Machine (PRAM) • data in globally-shared memory • implicit communication by updating memory • fast-random access – DISTRIBUTED-MEMORY • Bulk Synchronous Parallel (BSP) • data distributed to local, private memory • explicit communication by sending messages • easier to scale by adding more machines 8 [Paul Burkhardt, Chris Waring 2013]
- 9. Top Super Computer Installations 9 [Paul Burkhardt, Chris Waring 2013]
- 10. Big Data Makes Bigger Challenges to Graph Problems • Increasing volume, velocity, variety of Big Data are posting significant challenges to scalable graph algorithms. • Big Graph Challenges: – How will graph applications adapt to big data at petabyte scale? – Ability to store and process Big Graphs impacts typical data structures. • Big graphs challenge our conventional thinking on both algorithms and computing architectures 10
- 11. HPDC’15 11 Existing Graph Processing Systems • Single PC Systems – GraphLab [Low et al., UAI'10] – GraphChi [Kyrola et al., OSDI'12] – X-Stream [Roy et al., SOSP'13] – TurboGraph [Han et al., KDD‘13] – GraphLego [Zhou, Liu et al., ACM HPDC‘15] • Distributed Shared Memory Systems – Pregel [Malewicz et al., SIGMOD'10] – Giraph/Hama – Apache Software Foundation – Distributed GraphLab [Low et al., VLDB'12] – PowerGraph [Gonzalez et al., OSDI'12] – SPARK-GraphX [Gonzalez et al., OSDI'14] – PathGraph [Yuan et.al, IEEE SC 2014] – GraphMap [LeeLiu et al. IEEE SC 2015]
- 12. Parallel Graph Processing: Challenges • Structure driven computation – Storage and Data Transfer Issues • Irregular Graph Structure and Computation Model – Storage and Data/Computation Partitioning Issues – Partitioning v.s. Load/Resource Balancing 12
- 13. Parallel Graph Processing: Opportunities • Extend Existing Paradigms – Vertex centric – Edge centric • BUILD NEW FRAMEWORKS! – Centralized Approaches • GraphLego [ACM HPDC 2015] / GraphTwist [VLDB2015] – Distributed Approaches • GraphMap [IEEE SC 2015], PathGraph [IEEE SC 2014] 13
- 14. Parallel Graph Processing • Part I: Singe Machine Approaches • Can big graphs be processed on a single machine? • How to effectively maximize sequential access and minimize random access? • Part II: Distributed Approaches • How to effectively partition a big graph for graph computation? • Are large clusters always better for big graphs? 14
- 15. Part I: Parallel Graph Processing (single machine) Human connectome. Gerhard et al., Frontiers in Neuroinformatics 5(3), 2011 2 NA = 6.022 ⇥ 1023 mol 1 Paul Burkhardt, Chris Waring An NSA Big Graph experiment
- 16. 7/28/15 HPDC’15 16 Vertex-centric Computation Model • Think like a vertex • vertex_scatter(vertex v) – send updates over outgoing edges of v • vertex_gather(vertex v) – apply updates from inbound edges of v • repeat the computation iterations – for all vertices v • vertex_scatter(v) – for all vertices v • vertex_gather(v)
- 17. 7/28/15 HPDC’15 17 Edge-centric Computation Model (X-Stream) • Think like an edge (source vertex and destination vertex) • edge_scatter(edge e) – send update over e (from source vertex to destination vertex) • update_gather(update u) – apply update u to u.destination • repeat the computation iterations – for all edges e • edge_scatter(e) – for all updates u • update_gather(u)
- 18. 7/28/15 HPDC’15 18 Challenges of Big Graphs • Graph size v.s. limited resource – Handling big graphs with billions of vertices and edges in memory may require hundreds of gigabytes of DRAM • High-degree vertices – In uk-union with 133.6M vertices: the maximum indegree is 6,366,525 and the maximum outdegree is 22,429 • Skewed vertex degree distribution – In Yahoo web with 1.4B vertices: the average vertex degree is 4.7, 49% of the vertices have degree zero and the maximum indegree is 7,637,656 • Skewed edge weight distribution – In DBLP with 0.96M vertices: among 389 coauthors of Elisa Bertino, she has only one coauthored paper with 198 coauthors, two coauthored papers with 74 coauthors, three coauthored papers with 30 coauthors, and coauthored paper larger than 4 with 87 coauthors
- 20. 7/28/15 HPDC’15 20 Graph Processing Systems: Challenges • Diverse types of processed graphs – Simple graph: not allow for parallel edges (multiple edges) between a pair of vertices – Multigraph: allow for parallel edges between a pair of vertices • Different kinds of graph applications – Matrix-vector multiplication and graph traversal with the cost of O(n2) – Matrix-matrix multiplication with the cost of O(n3) • Random access – It is inefficient for both access and storage. A bunch of random accesses are necessary but would hurt the performance of graph processing systems • Workload imbalance – The time of computing on a vertex and its edges is much faster than the time to access to the vertex state and its edge data in memory or on disk – The computation workloads on different vertices are significantly imbalanced due to the highly skewed vertex degree distribution.
- 21. 7/28/15 HPDC’15 21 GraphLego: Our Approach • Flexible multi-level hierarchical graph parallel abstractions – Model a large graph as a 3D cube with source vertex, destination vertex and edge weight as the dimensions – Partitioning a big graph by: slice, strip, dice based graph partitioning • Access Locality Optimization – Dice-based data placement: store a large graph on disk by minimizing non- sequential disk access and enabling more structured in-memory access – Construct partition-to-chunk index and vertex-to-partition index to facilitate fast access to slices, strips and dices – implement partition-level in-memory gzip compression to optimize disk I/Os • Optimization for Partitioning Parameters – Build a regression-based learning model to discover the latent relationship between the number of partitions and the runtime
- 22. 7/28/15 HPDC’15 22 Modeling a Graph as a 3D Cube • Model a directed graph G=(V,E,W) as a 3D cube I=(S,D,E,W) with source vertices (S=V), destination vertices (D=V) and edge weights (W) as the three dimensions
- 23. 7/28/15 HPDC’15 23 Multi-level Hierarchical Graph Parallel Abstractions
- 24. 7/28/15 HPDC’15 24 Slice Partitioning: DBLP Example
- 25. 7/28/15 HPDC’15 25 Strip Partitioning of DB Slice
- 26. 7/28/15 HPDC’15 26 Dice Partitioning: An Example SVP: v1,v2,v3, v5,v6,v7, v11, v12, v15 DVP: v2,v3,v4,v5,v6, v7,v8,v9,v10,v11, v12,v13,v14,v15.v16
- 27. 7/28/15 HPDC’15 27 Dice Partition Storage (OEDs)
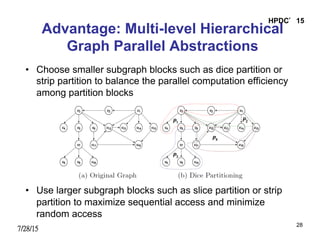
- 28. 7/28/15 HPDC’15 28 Advantage: Multi-level Hierarchical Graph Parallel Abstractions • Choose smaller subgraph blocks such as dice partition or strip partition to balance the parallel computation efficiency among partition blocks • Use larger subgraph blocks such as slice partition or strip partition to maximize sequential access and minimize random access
- 29. 7/28/15 HPDC’15 29 Partial Aggregation in Parallel • Aggregation operation – Partially scatter vertex updates in parallel – Partially gather vertex updates in parallel • Two-level Graph Computation Parallelism – Parallel partial update at the subgraph partition level (slice, strip or dice) – Parallel partial update at the vertex level Scatter Gather
- 31. 7/28/15 HPDC’15 31 Programmable Interface • vertex centric programming API, such as Scatter and Gather. • Compile iterative algorithms into a sequence of internal function (routine) calls that understand the internal data structures for accessing the graph by different types of subgraph partition blocks Gather vertex updates from neighbor vertices and incoming edges Scatter vertex updates to outgoing edges
- 32. 7/28/15 HPDC’15 32 Partition-to-chunk Index Vertex-to-partition Index • The dice-level index is a dense index that maps a dice ID and its DVP (or SVP) to the chunks on disk where the corresponding dice partition is stored physically • The strip-level index is a two level sparse index, which maps a strip ID to the dice-level index-blocks and then map each dice ID to the dice partition chunks in the physical storage • The slice level index is a three-level sparse index with slice index blocks at the top, strip index blocks at the middle and dice index blocks at the bottom, enabling fast retrieval of dices with a slice-specific condition
- 33. 7/28/15 HPDC’15 33 Partition-level Compression • Iterative computations on large graphs incur non- trivial cost for the I/O processing – The I/O processing of Twitter dataset on a PC with 4 CPU cores and 16GB memory takes 50.2% of the total running time for PageRank (5 iterations) • Apply in-memory gzip compression to transform each graph partition block into a compressed format before storing them on disk
- 34. 7/28/15 HPDC’15 34 Configuration of Partitioning Parameters • User definition • Simple estimation • Regression-based learning – Construct a polynomial regression model to model the nonlinear relationship between independent variables p, q, r (partition parameters) and dependent variable T (runtime) with latent coefficient αijk and error term ε – The goal of regression-based learning is to determine the latent αijk and ε to get the function between p, q, r and T – Select m limited samples of (pl, ql, rl, Tl) (1≤l≤m) from the existing experiment results – Solve m linear equations consisting of m selected samples to generate the concrete αijk and ε – Utilize a successive convex approximation method (SCA) to find the optimal solution (i.e., the minimum runtime T) of the above polynomial function and the optimal parameters (i.e., p, q and r) when T is minimum
- 35. 7/28/15 HPDC’15 35 Experimental Evaluation • Computer server – Intel Core i5 2.66 GHz, 16 GB RAM, 1 TB hard drive, Linux 64-bit • Graph parallel systems – GraphLab [Low et al., UAI'10] – GraphChi [Kyrola et al., OSDI'12] – X-Stream [Roy et al., SOSP'13] • Graph applications
- 36. 7/28/15 HPDC’15 36 Execution Efficiency on Single Graph
- 37. 7/28/15 HPDC’15 37 Execution Efficiency on Multiple Graphs
- 39. 7/28/15 HPDC’15 39 Efficiency of Regression-based Learning
- 40. GraphLego: Resource Aware GPS • Flexible multi-level hierarchical graph parallel abstractions – Model a large graph as a 3D cube with source vertex, destination vertex and edge weight as the dimensions – Partitioning a big graph by: slice, strip, dice based graph partitioning • Access Locality Optimization – Dice-based data placement: store a large graph on disk by minimizing non-sequential disk access and enabling more structured in-memory access – Construct partition-to-chunk index and vertex-to-partition index to facilitate fast access to slices, strips and dices – implement partition-level in-memory gzip compression to optimize disk I/ Os • Optimization for Partitioning Parameters – Build a regression-based learning model to discover the latent relationship between the number of partitions and the runtime 40