Run your queries 14X faster without any investment!
0 likes•356 views

This document discusses techniques for improving query performance on large datasets through pre-aggregation. It explains that pre-aggregating data into summary tables can speed up queries by orders of magnitude. Partitioning, bucketing, and creating aggregate tables are recommended to optimize storage. Dimensional modeling principles for designing aggregate tables are also covered, along with best practices for determining which aggregates to create and query optimization.


























![Performance
● Query: Find out the maximum item quantity, ordered for each
order placed.
>select L_ORDERKEY, max(L_QUANTITY) from lineitem group by
L_ORDERKEY
● Performance on Main Table: [Datasize: TPCH data with scale of 50gb ]
● Average: 9.384](https://image.slidesharecdn.com/run-query-faster-olap-nosql-180416054821/85/Run-your-queries-14X-faster-without-any-investment-29-320.jpg)
![Performance(cont...)
● Now let us first create a preaggregate,
● >create datamap max_order_quantity on table lineitem using
'preaggregate' as select L_ORDERKEY, max(L_QUANTITY) from
lineitem group by L_ORDERKEY
● Performance after creating pre-aggregate:
● [Datasize: TPCH data with scale of 50gb ]
● Average: 1.190](https://image.slidesharecdn.com/run-query-faster-olap-nosql-180416054821/85/Run-your-queries-14X-faster-without-any-investment-30-320.jpg)













Run your queries 14X faster without any investment!
- 1. Run your aggregation queries at a speed of 14x without spending $$$ By: Bhavya Aggarwal(CTO, Knoldus) Sangeeta Gulia(Software Consultant, Knoldus)
- 2. Agenda ● What are aggregates? ● Why are aggregates slow ● Sql Queries and Big Data ● Techniques to prevent full scan ● Partitioning and Bucketing ● What is pre-aggregation. ● Advantages of pre-aggregation ● Trade offs with Pre-aggregation ● How can we pre-aggregate data. ● Suggestions for Pre-aggregation
- 3. “The single most dramatic way to affect performance in a large data warehouse is to provide a proper set of aggregate (summary) records that coexist with the primary base records. Aggregates can have a very significant effect on performance, in some cases speeding queries by a factor of one hundred or even one thousand. No other means exist to harvest such spectacular gains.” - Ralph Kimball
- 4. Commonly Used Aggregates Function Description MIN returns the smallest value in a given column MAX returns the largest value in a given column SUM returns the sum of the numeric values in a given column AVG returns the average value of a given column COUNT returns the total number of values in a given column COUNT(*) returns the number of rows in a table
- 5. Why are Aggregates Slow ● Iteration has to be done on the whole data traversing each record. ● When data size is large this computation of aggregate functions take long time.
- 6. Interactive SQL Queries ● When it comes to extract some meaningful information from stored data. First thing that comes to our mind is SQL ● Almost everyone is comfortable in playing with the data to extract meaningful information out of it. ● Problem starts when we have to work on large data(terabytes/petabytes)
- 7. How we store data is important ● We need to analyse the application first rather than storing data ● We should understand the use cases or the data that will make sense for the Business Users ● What will be the optimized storage format (Columnar Storage) − ORC − Parquet − Carbondata
- 8. Techniques to prevent full scan ● Partitioning ● Bucketing ● Preaggregation − Compaction
- 9. Partitioning ● It divides amount of data into number of folders based on table columns value, this has performance benefit, and helps in organizing data in a logical fashion. ● Always Partition on a low cardinality column.
- 10. Understanding Partitioning ● Example: if we are dealing with a large employee table and often run queries with WHERE clauses that restrict the results to a particular country or department . create table employees (id int,name string,dob string) PARTITIONED BY (country STRING, DEPT STRING) ● For a faster query response Hive table can be partitioned . Partitioning tables changes how Hive structures the data storage and Hive will now create subdirectories reflecting the partitioning structure like .../employees/country=ABC/DEPT=XYZ.
- 11. Bucketing ● Bucketing feature of Hive can be used to distribute/ organize the table/partition data into multiple files such that similar records are present in the same file based on some logic mostly some hashing algorithm. ● Bucketing works well when the field has high cardinality and data is evenly distributed among buckets
- 12. Understanding Bucketing ● For example, suppose a table using date as the top-level partition and employee_id as the second-level partition leads to too many small partitions. ● Instead, if we bucket the employee table and use employee_id as the bucketing column, the value of this column will be hashed by a user-defined number into buckets. create table employees (id int,name string,age int) PARTITIONED BY (dob string) CLUSTERED BY(id) INTO 5 BUCKETS
- 13. Understanding Bucketing then hive will store data in a directory hierarchy like /user/hive/warehouse/mytable/dob=2001-02-01 bucketed with 5 buckets inside the above directory: 00000_0 00001_0 ........ 00004_0 Here dob=2001-02-01 is the partition and 000 files are the buckets in partition.
- 14. How Bucketing Improves Performance ● Fast Map side Joins ● Efficient Group by ● Sampling
- 15. Dimension Table ● In a Dimensional Model, context of the measurements are represented in dimension tables. You can also think of the context of a measurement as the characteristics such as who, what, where, when, how of a measurement. ● In your business process Sales, the characteristics of the ‘monthly sales number’ measurement can be a Location (Where), Time (When), Product Sold (What). ● Table that captures the information regarding each entity that is referenced in a fact table.
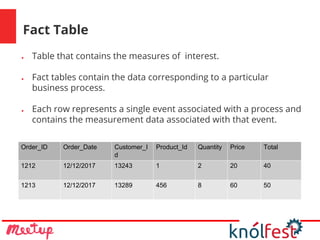
- 16. Fact Table ● Table that contains the measures of interest. ● Fact tables contain the data corresponding to a particular business process. ● Each row represents a single event associated with a process and contains the measurement data associated with that event. Order_ID Order_Date Customer_I d Product_Id Quantity Price Total 1212 12/12/2017 13243 1 2 20 40 1213 12/12/2017 13289 456 8 60 50
- 18. Dimension Aggregates ● Methods to define aggregates ● Include or leave out entire dimensions ● Include some columns of each dimension, but not others − Second approach is more common / more useful ● Example: Several versions of Date dimension − Base Date dimension ● 1 row per day − Monthly aggregate dimension ● 1 row per month − Yearly aggregate dimension ● 1 row per year
- 19. Choosing Dimension Aggregates ● Dimension aggregates often roll up along hierarchies − Day : month – year − Store : area_code - state – country ● Any subset of dimension attributes can be used − Customer aggregate might include only a few frequently-queried columns (age, gender, income, marital status) ● Goal: reduced number of distinct combinations − Results in fewer rows in aggregated fact
- 20. Pre-Aggregation ● Aggregate fact tables are simple numeric rollups of atomic fact table data built solely to accelerate query performance ● It is important to remember that aggregation is a form of data redundancy, because the aggregations are computed from other warehouse values. ● For obvious performance reasons, the aggregations are pre-calculated and loaded into the warehouse during off-hours.
- 21. Advantages of Pre-Aggregated Tables ● Reduce input/output, CPU, RAM, and swapping requirements ● Minimize the amount of data that must be aggregated and sorted at run time thereby reducing memory requirements for joins ● Move time-intensive calculations with complicated logic or significant computations into a batch routine from dynamic SQL executed at report run time
- 22. Trade-offs for Pre Aggregation ● Query Performance V/S Load Performance ● Building and updating data structures will be costly. ● Load Time will be slower. ● Pre-aggregation will improve performance of only those queries for which pre-computed data exist.
- 23. Pre Aggregation Choices ● Most (R)OLAP tools today support practical pre- aggregation − IBM DB2 uses Materialized Query Tables(MDTs) − Oracle 9iR2 uses Materialised Views − Hyperion Essbase (DB2 OLAP Services) − Carbondata Preaggregates
- 24. Creating Pre-aggregate Table (carbondata) ● Carbondata supports pre aggregating of data so that OLAP kind of queries can fetch data much faster.
- 26. How pre-aggregate tables are selected ● For the main table sales and pre-aggregate table agg_sales created above, queries of the kind: − SELECT country, sex, sum(quantity), avg(price) from sales GROUP BY country, sex − SELECT sex, sum(quantity) from sales GROUP BY sex − SELECT avg(price), country from sales GROUP BY country ● will be transformed by Query Planner to fetch data from pre-aggregate table agg_sales
- 27. How pre-aggregate tables are selected ● But queries of kind : − SELECT user_id, country, sex, sum(quantity), avg(price) from sales GROUP BY user_id, country, sex − SELECT sex, avg(quantity) from sales GROUP BY sex − SELECT country, max(price) from sales GROUP BY country ● will fetch the data from the main table sales Datamap
- 28. Queries ● Query1: Find out the maximum quantity ordered in each order placed. ● Query2: Find out the total amount spent by a customer for all the orders he has placed. ● Query3: Find out the average amount spent by a customer for a particular order
- 29. Performance ● Query: Find out the maximum item quantity, ordered for each order placed. >select L_ORDERKEY, max(L_QUANTITY) from lineitem group by L_ORDERKEY ● Performance on Main Table: [Datasize: TPCH data with scale of 50gb ] ● Average: 9.384
- 30. Performance(cont...) ● Now let us first create a preaggregate, ● >create datamap max_order_quantity on table lineitem using 'preaggregate' as select L_ORDERKEY, max(L_QUANTITY) from lineitem group by L_ORDERKEY ● Performance after creating pre-aggregate: ● [Datasize: TPCH data with scale of 50gb ] ● Average: 1.190
- 35. Pre-aggregate with Timeseries (carbondata) Datamap property Description event_time The event time column in the schema, which will be used for rollup. The column need be timestamp type. time granularity The aggregate dimension hierarchy. The property value is a key value pair specifying the aggregate granularity for the time level. Carbon support “year_granularity”, “month_granularity”, “day_granularity”, “hour_granularity”, “minute_granularity”, “second_granularity”. Granularity only support 1 when creating datamap. For example, ‘hour_granularity’=’1’ means aggregate every 1 hour. Now the value only support 1.
- 36. Understanding Datamap with Timeseries ● Query before creating aggregate: ● >select DOB, max(DOUBLE_COLUMN1) from uniqdata group by DOB ● Creating Preaggregate: ● >create datamap timeseries_agg on table uniqdata using 'timeseries' dmproperties('event_time'='DOB','year_granularity'='1') as select DOB, max(DOUBLE_COLUMN1) from uniqdata group by DOB
- 37. Understanding Datamap with Timeseries ● After Creating Preaggregate: ● >select timeseries(DOB,'year'),max(DOUBLE_COLUMN1) from uniqdata group by timeseries(DOB,'year') ● will map to aggregate, but below query will be executed using main table. ● >select timeseries(DOB,'month'),max(DOUBLE_COLUMN1) from uniqdata group by timeseries(DOB,'month')
- 38. Logical Plan of Datamap with Timeseries
- 39. Goals for Aggregation Strategy ● Do not get bogged down with too many aggregates. ● Try to cater to a wide range of user groups. ● Keep the aggregates hidden from end users. That is, the aggregate must be transparent to the end user query. The query tool must be the one to be aware of the aggregates to direct the queries for proper access.
- 40. Suggestions for Preaggregation ● Before doing any calculations, spend good time to determine what pre-aggregate you need. What will be the common queries. ● Spend good time on understanding level of hierarchies and identify the important hierarchy. ● In each dimension check the attributes required to group the fact table metrics ● The next step is to determine which of the attributes are used in combinations and what are most common combinations
- 42. References ● https://carbondata.apache.org/data-management-on-carbondat a.html ● https://www.slideshare.net/siddiqueibrahim37/aggregate-fact-ta bles ● https://www.ibm.com/support/knowledgecenter/en/SSCRW7_6.3 .0/com.ibm.redbrick.doc6.3/vista/vista20.htm ● http://myitlearnings.com/bucketing-in-hive/