Understanding Jupyter notebooks using bioinformatics examples
Download as PPTX, PDF4 likes1,193 views

The document discusses the evolution and capabilities of Jupyter Notebooks in bioinformatics and machine learning. It highlights the various stages in the ML lifecycle supported by Jupyter, including data collection, preparation, model evaluation, and deployment. Additionally, it covers advancements in genomic analysis using tools like Variant Spark and cloud-based Jupyter services, emphasizing their role in facilitating reproducible research and collaboration in academic environments.













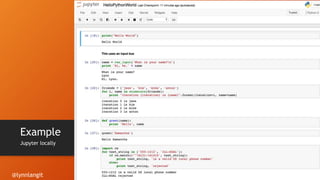







![# set up context and input parameters
spark = SparkSession(sc)
vc = VariantsContext(spark)
label = vc.load_label('dius/data/chr22-labels.csv', 'col_name')
features = vc.import_vcf('dius/data/chr22_1000.vcf')
# instantiate analysis (parameters are type-checked)
imp_analysis = features.importance_analysis(label)
# get significant factors as both a tuple list and a dataframe
imp_vars = imp_analysis.important_variables(20)
most_imp_var = imp_vars[0][0]
imp_df = imp_analysis.variable_importance()
oob_error = imp_analysis.oob_error()
# convert to work with common Python tools
pandas_imp_df = imp_df.toPandas()
New -- Python API for VariantSpark](https://image.slidesharecdn.com/jupyter-notebooks-180522173507/85/Understanding-Jupyter-notebooks-using-bioinformatics-examples-29-320.jpg)








Understanding Jupyter notebooks using bioinformatics examples
- 1. The next terminal – Jupyter With examples from Bioinformatics @lynnlangit
- 2. “ ” How often do you use the terminal? @lynnlangit
- 3. Terminal Customizations Prompt Output Aesthetics Code Comments Graphics @lynnlangit
- 6. What does this Code do? @lynnlangit
- 7. “ ” But it’s not good enough Why not? @lynnlangit
- 8. Machine Learning Too much data to process? Or too much code? Can you ‘see’ what is happening? @lynnlangit
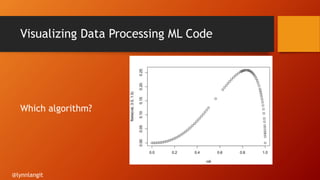
- 9. What does this Code do? Which algorithm? @lynnlangit
- 10. Visualizing Data Processing ML Code Which algorithm? @lynnlangit
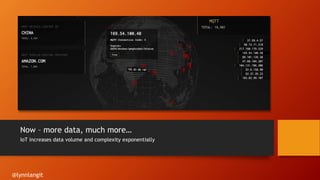
- 11. Now – more data, much more… IoT increases data volume and complexity exponentially @lynnlangit
- 12. “ ” Inspired by Mathematica Thanks Steven Wolfram If you can SEE it (your data and code), you can work with it better @lynnlangit
- 13. Next terminal -> a better Python REPL • Fernando Perez in 2001 • IPython (interactive) • Modeled - Mathematica Notebooks • IP(y): Notebook -> in a browser • 2012 IPython -> Jupyter Notebook @lynnlangit
- 15. Jupyter Notebooks supports ML Lifecycle 1. Collect Data Retrieve Files Query SQL Databases Call Web Services “Scrape” Web Pages 2. Prepare Data Explore Data Validate Data Clean Data Features / Data 4. Evaluate Model Test Performance Compare Models Validate Model Visualize 5. Deploy Model Export Model File Prepare Job Deploy Container Re-package Model Execute code blocks: - Python, R… code - SQL queries - Shell commands 3. Train Model Prepare Training Set Experiment Test Model Visualize Write Documentation: - Markdown language Visualize Data - Viz tools…
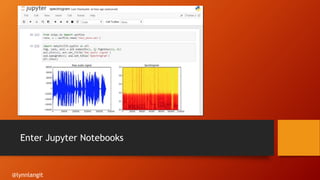
- 16. Jupyter Visualizations – so many possibilities
- 17. Notebook Customizations Multiple Runtimes Languages Share output Code or Equations LaTex Math Comments Markdown Wiki-like Graphics Visualizations Charting Results LIVE DOCUMENTATION Reproducible Research @lynnlangit
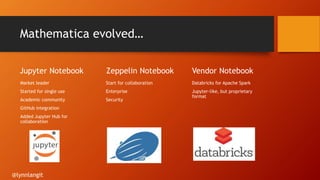
- 19. Mathematica evolved… Jupyter Notebook Market leader Started for single use Academic community GitHub integration Added Jupyter Hub for collaboration Zeppelin Notebook Start for collaboration Enterprise Security Vendor Notebook Databricks for Apache Spark Jupyter-like, but proprietary format @lynnlangit
- 20. Running Notebooks Desktop Install and run Local Server Can use Jupyter Hub for groups Cloud Large number of options @lynnlangit
- 21. Extending, Refactoring Open Notebooks • Write functions in one notebook • Link to another notebook • Write extensions (nbextensions.com)
- 22. Up the bar Personalized medicine via genomic analysis @lynnlangit
- 23. Reproducible Research – Experiments as Code @lynnlangit
- 24. Bioinformatics | Denis C. Bauer | @allPowerde| GT-Scan2 How can genome engineering be made more effective? Variant Spark How to find disease genes in population-size cohorts? Genomic Research Tools Two Examples
- 25. Transformational Bioinformatics | Denis C. Bauer | @allPowerde Machine learning… on 1.7 Trillion data points https://www.projectmine.com/about/
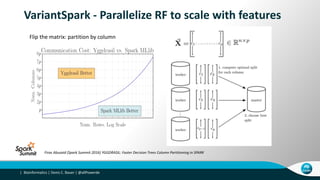
- 26. Bioinformatics | Denis C. Bauer | @allPowerde| VariantSpark - Parallelize Random Forest for scalability • Spark ML’s RF was designed for ‘Big’ low dimensional data. • The full genome-wide profile does NOT fit into the executors memory “Cursed” BigData: e.g. Genomics Moderate number of samples with many features Feature set too large to be handled by single executer
- 27. Bioinformatics | Denis C. Bauer | @allPowerde| Firas Abuzaid (Spark Summit 2016) YGGDRASIL: Faster Decision Trees Column Partitioning in SPARK Flip the matrix: partition by column VariantSpark - Parallelize RF to scale with features
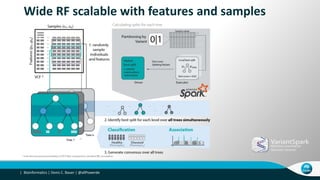
- 28. Bioinformatics | Denis C. Bauer | @allPowerde| Wide RF scalable with features and samples
- 29. # set up context and input parameters spark = SparkSession(sc) vc = VariantsContext(spark) label = vc.load_label('dius/data/chr22-labels.csv', 'col_name') features = vc.import_vcf('dius/data/chr22_1000.vcf') # instantiate analysis (parameters are type-checked) imp_analysis = features.importance_analysis(label) # get significant factors as both a tuple list and a dataframe imp_vars = imp_analysis.important_variables(20) most_imp_var = imp_vars[0][0] imp_df = imp_analysis.variable_importance() oob_error = imp_analysis.oob_error() # convert to work with common Python tools pandas_imp_df = imp_df.toPandas() New -- Python API for VariantSpark
- 30. Demo VariantSpark Jupyter for Genomics Research @lynnlangit
- 32. Cloud-based Jupyter PaaS • AWS SageMaker • Azure Notebooks • Others… @lynnlangit
- 33. Example - GT-Scan2 Jupyter for Genomics Research @lynnlangit
- 35. Tools for Jupyter • Binder for GitHub • Point to your GitHub Repo • Jupyter Notebooks • Requirements.txt • It builds a Docker image • You can run your Notebooks @lynnlangit
- 37. Future of Jupyter for Research Academic Institutions and Research Labs UC Berkeley, Davis, San Diego Cal Poly San Luis Obispo Clemson University UC Boulder U of Illinois, Minnesota, Missouri, Rochester, Texas MIT Michigan State U Texas A & M @lynnlangit
Editor's Notes
- #5: http://www.omgubuntu.co.uk/2017/06/terminus-modern-highly-configurable-terminal-app-windows-mac-linux
- #6: telnet towel.blinkenlights.nl
- #11: Left-skewed, negative distribution
- #14: History talk from Cristian Prieto (NDC Oslo 2016) -- https://vimeo.com/223984769 http://blog.fperez.org/2012/01/ipython-notebook-historical.html
- #20: Local install pip install –iPython all -OR- can use anaconda, which installs Jupyter notebooks by default pip install jupyter[all] and you can pip install R You can use Docker – 2.1 GB image contains all libraries or you can use Azure Notebooks or AWS SageMaker Notebooks Only Python2 is installed by default, you can install other runtimes Start and run in local browser (no database, uses local .json files) IPython notebook -> localhost:8888/tree Use GitHub-flavor Markdown (by default) https://dwhsys.com/2017/03/25/apache-zeppelin-vs-jupyter-notebook/
- #22: https://github.com/ipython-contrib/jupyter_contrib_nbextensions pip install jupyter_contrib_nbextensions –OR- conda install -c conda-forge jupyter_contrib_nbextensions
- #24: https://github.com/Microsoft/Elevation/blob/master/notebooks/aggregation.ipynb https://www.microsoft.com/en-us/research/project/crispr/
- #26: Using this instead?
- #27: Less conclusion, more implementation
- #32: https://www.gt-scan.net/ --AND- AMA with Dr, Bauer -- https://www.reddit.com/r/science/comments/5fiicm/science_ama_series_im_denis_bauer_a_team_leader/
- #33: https://medium.com/@lynnlangit/aws-sagemaker-for-bioinformatics-b8e8a96479d8 Jupyter on GCE VM -- https://towardsdatascience.com/running-jupyter-notebook-in-google-cloud-platform-in-15-min-61e16da34d52
- #36: https://mybinder.org/ -ALSO- https://nbviewer.jupyter.org/ - allows you to run notebooks stored in GitHub
- #38: http://jupyterhub-tutorial.readthedocs.io/en/latest/ https://github.com/jupyterhub/jupyterhub-tutorial/blob/master/JupyterHub.pdf http://jupyterhub.readthedocs.io/en/latest/gallery-jhub-deployments.html