



















































Cp usched 2
- 2. Operating Systems Structure and Design CPU scheduling historical perspective CPU-I/O bursts preemptive vs. nonpreemptive scheduling scheduling criteria scheduling algorithms: FCFS, SJF, Priority, RR, multilevel multiple-processor & real-time scheduling real-world systems: BSD UNIX, Solaris, Linux, Windows NT/2K, …
- 3. Process States..revisited Instructions are being executed (mutually exclusive in time) The process is waiting for some event to occur (many processes can be waiting at one time) 3a. I/O or Event Wait 4. I/O or event completion WAITING NEW The process is being created READY The process is ready/waiting to be assigned to the CPU 1. Admitted RUNNING 2. Scheduler Dispatch 3b. Interrupt 5 TERMINATED The process has finished execution 6. Exit
- 4. Schedulers A process migrates between various scheduling queues throughout its lifetime. The process of selecting processes from these queues is carried out by a scheduler . 2 types of scheduler Long-term scheduler (job scheduler) Short-term scheduler (CPU scheduler)
- 5. Schedulers Long-term scheduler (or job scheduler) – selects which processes should be brought into the ready queue. Long-term scheduler is invoked very infrequently (seconds, minutes) thus may be slower CPU Short-Term/ CPU Scheduler (Ready Queue) Long-Term/ Job Scheduler (Job Queue) Short-term scheduler (or CPU scheduler) – selects which process should be executed next and allocates CPU Is invoked very frequently (milliseconds) – thus must be fast
- 6. Short-Term Scheduling selects from among the processes that are ready to execute and allocates the CPU to one of them must select a new process for the CPU frequently must be very fast. Determines which process is going to execute next The short term scheduler is known as the dispatcher Is invoked on an event that may lead to choosing another process for execution: clock interrupts I/O interrupts operating system calls and traps signals
- 7. Long Term Schedulers There may be minutes between the creation of new process in the system The long-term scheduler controls the degree of multiprogramming Degree of multiprogramming: the number of processes in main memory Stable Degree of Multiprogramming: average rate of process creation = average departure rate of processes leaving the system Thus the LTS may need to be invoked only if a process leaves the system – because of longer intervals between executions, the LTS can afford to take more time to select the next process for execution The Long-term scheduler is also responsible for selecting a good process mix of the2 types of processes: I/O- bound process – spends more time doing I/O than computations, many short CPU bursts CPU - bound process – spends more time doing computations; few very long CPU bursts
- 9. Addition of Medium Term Scheduling The Medium Term Scheduler facilitates efficient swapping It removes processes (less priority?) from MM (from active contention of CPU) and thus reduce the DoM At some later time, the process can be reintroduced into MM and its execution can be completed where it left off – this is scheme is called swapping
- 11. How do processes behave ? First, CPU/IO burst cycle. A process will run for a while (the CPU burst), perform some IO (the IO burst), then run for a while more (the next CPU burst). How long between IO operations? Depends on the process. IO Bound processes : processes that perform lots of IO operations. Each IO operation is followed by a short CPU burst to process the IO, then more IO happens. CPU bound processes : processes that perform lots of computation and do little IO. Tend to have a few long CPU bursts. One of the things a scheduler will typically do is switch the CPU to another process when one process does IO. Why? The IO will take a long time, and don't want to leave the CPU idle while wait for the IO to finish.
- 12. CPU-I/O bursts process execution consists of a cycle of CPU execution and I/O wait different processes may have different distributions of bursts CPU-bound process: performs lots of computations in long bursts, very little I/O I/O-bound process: performs lots of I/O followed by short bursts of computation ideally, the system admits a mix of CPU-bound and I/O-bound processes to maximize CPU and I/O device usage
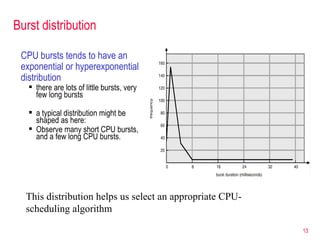
- 13. Burst distribution CPU bursts tends to have an exponential or hyperexponential distribution there are lots of little bursts, very few long bursts a typical distribution might be shaped as here: Observe many short CPU bursts, and a few long CPU bursts. This distribution helps us select an appropriate CPU-scheduling algorithm
- 14. Mechanism vs. policy a key principle of OS design: separate mechanism (how to do something) vs. policy (what to do, when to do it) an OS should provide a context-switching mechanism to allow for processes/threads to be swapped in and out a process/thread scheduling policy decides when swapping will occur in order to meet the performance goals of the system
- 15. Preemptive vs. nonpreemptive scheduling CPU scheduling decisions may take place when a process: switches from running to waiting state e.g., I/O request switches from running to ready state e.g., when interrupt or timeout occurs switches from waiting to ready e.g., completion of I/O 4. terminates scheduling under 1 and 4 is nonpreemptive once a process starts, it runs until it terminates or willingly gives up control simple and efficient to implement – few context switches examples: Windows 3.1, early Mac OS all other scheduling is preemptive process can be "forced" to give up the CPU (e.g., timeout, higher priority process) more sophisticated and powerful examples: Windows 95/98/NT/2K, Mac OS-X, UNIX
- 16. Preemptive vs Non-Preemptive Scheduling Scheduling is non-preemptive if once the CPU has been allocated to a process, the process can keep the CPU until it releases it, either by terminating or switching to the waiting state. Scheduling is preemptive if the CPU can be taken away from a process during execution.
- 17. CPU scheduling criteria CPU utilization: (time CPU is doing useful work)/(total elapsed time) keep the CPU as busy as possible in a real system, should range from 40% (light load) to 90% (heavy load) throughput: number of jobs completed per unit time. want to complete as many processes/jobs as possible actual number depends upon the lengths of processes (shorter higher throughput) turnaround time: How long does it take a job to make its way through the system? That is, once submitted, how much time elapses before the job is complete? The "complete", in this context, usually means that all computation and I/O has been done. Turnaround time is a "system" measure. That is, it measures how well everything works together … the CPU, the I/O equipment, RAM, and the Operating System.
- 18. waiting time: average time a process has spent waiting in the ready queue want to minimize time process is in the system but not running less dependent on process length turnaround time : average time taken by a process to complete Waiting time + execution time + time spent in I/O time spent to get into memory. want to minimize time it takes from origination to completion again: average depends on process lengths
- 19. response time: average time between submission of request and first response What is the time that elapses between the time a command is submitted and the system begins to respond? There are various ways to make this more precise. If the system is in a real-time application, the amount of time that the system takes to respond is extremely important. It may be that a TV camera subsystem has detected that a robot is about to crush the fender of a car on the assembly line. When the subsystem sends this information to our system, the response time is fairly important.
- 20. CPU scheduling criteria (cont.) CPU scheduling may also be characterized w.r.t. fairness want to share the CPU among users/processes in some equitable way minimal definition of fairness: freedom from starvation starvation = indefinite blocking want to ensure that every ready job will eventually run (assuming arrival rate of new jobs ≤ max throughput of the system) note: fairness is often at odds with other scheduling criteria e.g., can often improve throughput or response time by making system less fair in a batch system, throughput and turnaround time are key in an interactive system, response time is usually most important
- 21. Scheduling algorithms First-Come, First-Served (FCFS) CPU executes job that arrived earliest Shortest-Job-First (SJF) CPU executes job with shortest time remaining to completion* Priority Scheduling CPU executes process with highest priority Round Robin (RR) like FCFS, but with limited time slices Multilevel queue like RR, but with multiple queues for waiting processes (i.e., priorities) Multilevel feedback queue like multilevel queue, except that jobs can migrate from one queue to another
- 22. First-Come, First-Served (FCFS) scheduling the ready queue is a simple FIFO queue when a process enters the system, its PCB is added to the rear of the queue when a process terminates/waits, process at front of queue is selected FCFS is nonpreemptive once a process starts, it runs until it terminates or enters wait state (e.g., I/O) average waiting and turnaround times can be poor in general, nonpreemptive schedulers perform poorly in a time sharing system since there is no way to stop a CPU-intensive process (e.g., an infinite loop)
- 23. Process CPU Burst Time (ms ) P1 24 P2 3 P3 3 Suppose that processes arrive in the order: P1, P2, P3, we get the result shown in the Gantt chart below: FCFS example P1 P2 P3 0 24 27 30 Waiting time for P1 = 0; P2 = 24; P3 = 27 Ave. waiting time: (0 + 24 + 27) /3 = 17 ms.
- 24. FCFS Scheduling, cont. If the processes arrive in the order: P2, P3, P1, then the Gantt chart is as follows: P1 P2 P3 0 3 6 30 Waiting time for P1 = 6; P2 = 0; P3 = 3 Ave. waiting time : (6 + 0 + 3)/3 = 3 Much better than the previous case, where we had a Convoy Effect : short process behind long process. Results in lower CPU utilization
- 25. Shortest-Job-First Scheduling When the CPU is available, it is assigned to the process that has the smallest next CPU burst. If two processes have the same length next CPU burst, FCFS scheduling is used to break the tie Use these lengths to schedule the process with the shortest time. 2 schemes: Non-preemptive - once CPU is given to the process, it cannot be preempted until it completes its CPU burst. Preemptive - if a new process arrives with CPU burst length less than remaining time of of current executing process, preempt.
- 26. Nonpreemptive SJF example Example of non-preemptive SJF: Process CPU burst time P1 6 P2 8 P3 7 P4 3 P1 P2 P3 0 3 9 16 24 P4 Average waiting time = (0 + 3 + 9 + 16)/4 = 7 ms
- 27. SJF Scheduling, cont. Example of Preemptive SJF (Shortest-Remaining-Time-First) Process Arrival Time Burst Time P1 0 8 P2 1 4 P3 2 9 P4 3 5 P2 P1 P4 P1 P3 0 1 5 10 17 26 When process P2 arrives, the remaining time for P1 (7 ms) is larger than the time required for P2 (4 ms), so process P1 is preempted and P2 is scheduled. Average waiting time is : ((10-1) + (1-1) + (17-2) + (5-3)) / 4 = 6.5 ms.
- 28. The SJF algorithm gives the minimum average waiting time for a given set of processes. The difficulty with SJF is knowing the length of the next CPU request. For long-term scheduling in a batch system, an estimate of the burst time can be acquired from the job description. For short-term scheduling, we have to predict the value of the next burst time.
- 29. SJF: predicting the future in reality, can't know precisely how long the next CPU burst will be consider the Halting Problem can estimate the length of the next burst simple: same as last CPU burst more effective in practice: exponential average of previous CPU bursts where: n = predicted value for nth CPU burst t n = actual length for nth CPU burst = weight parameter (0 ≤ ≤ 1, larger emphasizes last burst)
- 30. Exponential averaging consider the following example, with = 0.5 and 0 = 10
- 31. Priority scheduling each process is assigned a numeric priority CPU is allocated to the process with the highest priority priorities can be external (set by user/admin) or internal (based on resources/history) SJF is priority scheduling where priority is the predicted next CPU burst time priority scheduling may be preemptive or nonpreemptive priority scheduling is not fair starvation is possible – low priority processes may never execute can be made fair using aging – as time progresses, increase the priority Aging is a technique of gradually increasing the priority of processes that wait in the system for a long time
- 32. Priority scheduling example Process Burst Time Priority P 1 10 3 P 2 1 1 P 3 2 4 P 4 1 5 P 5 5 2 assuming processes all arrived at time 0, Gantt Chart for the schedule is: average waiting time: (6 + 0 + 16 + 18 + 1)/5 = 8.2 average turnaround time: (16 + 1 + 18 + 19 + 6)/5 = 12 P 5 P 3 P 2 6 1 16 0 P 4 18 19 P 1
- 33. Round-Robin (RR) scheduling RR = FCFS with preemption time slice or time quantum is used to preempt an executing process timed out process is moved to rear of the ready queue some form of RR scheduling is used in virtually all operating systems if there are n processes in the ready queue and the time quantum is q each process gets 1/ n of the CPU time in chunks of at most q time units at once no process waits more than ( n -1) q time units. performance if q is too large, response time suffers (reduces to FCFS) if q is too small, throughput suffers (spend all of CPU's time context switching) in practice, quantum of 10-100 msec, context-switch of 0.1-1msec CPU spends 1% of its time on context-switch overhead
- 34. RR example Process Arrival Time Burst Time P 1 0 24 P 2 2 3 P 3 4 3 assuming q = 4, Gantt Chart for the schedule is: average waiting time: (6 + 2 + 3)/3 = 3.67 average turnaround time: (30 + 5 + 6)/3 = 13.67 P 1 P 1 P 1 22 26 30 0 4 7 10 14 18 P 1 P 2 P 3 P 1 P 1
- 35. A multi-level queue-scheduling (MLQ) A multi-level queue-scheduling (MLQ) algorithm partitions the ready queue into several separate queues. Created for situations in which processes are easily classified into groups. For e.g. foreground (interactive) processes and background (batch) processes). These two types of processes have different response-time requirements, and thus, different scheduling needs. The processes are permanently assigned to one queue, based on some property of the process. (e.g. memory size, priority, or type). Each queue has its own scheduling algorithm. For e.g. the foreground queue might be scheduled by an RR algorithm, while the background queue is scheduled by a FCFS algorithm.
- 36. Multilevel queue combination of priority scheduling and other algorithms (often RR) ready queue is partitioned into separate queues each queue holds processes of a specified priority each queue may have its own scheduling algorithm (e.g., RR for interactive processes, FCFS for batch processes) must be scheduling among queues absolute priorities (uneven) time slicing
- 37. Multilevel feedback queue similar to multilevel queue but processes can move between the queues e.g., a process gets lower priority if it uses a lot of CPU time process gets a higher priority if it has been ready a long time (aging) example: three queues Q 0 – time quantum 8 milliseconds Q 1 – time quantum 16 milliseconds Q 2 – FCFS scheduling new job enters queue Q 0 which is served RR when it gains CPU, job receives 8 milliseconds if it does not finish in 8 milliseconds, job is moved to queue Q 1 . at Q 1 job is again served RR and receives 16 additional milliseconds if it still does not complete, it is preempted and moved to queue Q 2 .
- 38. Multiprocessor scheduling CPU scheduling is more complex when multiple CPUs are available symmetric multiprocessing: when all the processors are the same, can attempt to do real load sharing 2 common approaches: separate queues for each processor, processes are entered into the shortest ready queue one ready queue for all the processes, all processors retrieve their next process from the same spot asymmetric multiprocessing: can specialize, e.g., one processor for I/O, another for system data structures, … alleviates the need for data sharing
- 39. Real-time scheduling hard real time systems requires completion of a critical task within a guaranteed amount of time soft real-time systems requires that critical processes receive priority over less fortunate ones note: delays happen! when event occurs, OS must: handle interrupt save current process load real-time process execute for hard real-time systems, may have to reject processes as impossible
- 40. Scheduling algorithm evaluation various techniques exist for evaluating scheduling algorithms Deterministic model use predetermined workload, evaluate each algorithm using it this is what we have done with the Gantt charts Process Arrival Time Burst Time P 1 0 24 P 2 2 3 P 3 4 3 FCFS: average waiting time: (0 + 22 + 23)/3 = 15 average turnaround time: (24 + 25 + 26)/3 = 25 RR (q = 4): average waiting time: (6 + 2 + 3)/3 = 3.67 average turnaround time: (30 + 5 + 6)/3 = 13.67 P 1 P 2 P 3 24 27 30 0 P 1 P 1 P 1 22 26 30 0 4 7 10 14 18 P 1 P 2 P 3 P 1 P 1
- 41. Scheduling algorithm evaluation (cont.) Simulations use statistical data or trace data to drive the simulation expensive but often provides the best information this is what we did with HW1 and HW2
- 42. Scheduling algorithm evaluation (cont.) Queuing models statistically based, utilizes mathematical methods collect data from a real system on CPU bursts, I/O bursts, and process arrival times Little’s formula: N = L * W where N is number of processes in the queue L is the process arrival rate W is the wait time for a process under simplifying assumptions (randomly arriving jobs, random lengths): response_time = service_time/(1-utilization) powerful methods, but real systems are often too complex to model neatly
- 43. Scheduling example: BSD UNIX BSD UNIX utilizes 32 multilevel feedback queues system processes use queues 0-7, user processes use queues 8-31 dispatcher selects from the highest priority queue within a queue, RR scheduling is used (time quanta vary, but < 100 sec) every process has an external nice priority, used to determine its queue default priority is 0, but can be changed using the nice system call (highest priority) -20 … 20 (lowest priority) approximately once per quantum, the scheduler recomputes each process's priority if recent CPU demand was high, priority is lowered user-mode processes are preemptive, kernel-mode processes are not
- 44. Scheduling example: Solaris 2 utilizes 4 priority classes each with priorities & scheduling algorithms time-sharing is default utilizes multilevel feedback queue, dynamically altered priorities, inverse relationship between priorities & time slices interactive class same as time-sharing windowing apps high priorities system class runs kernel processes static priorities, FCFS real-time class provides highest priority
- 45. Scheduling example: Linux Linux provides 2 separate processing scheduling algorithms for time-sharing processes , it uses a prioritized, credit-based algorithm each process starts with a certain number of credits scheduler chooses the process with the most credits when a timer-interrupt occurs, active process loses a credit (if no credits, then the process is suspended) if all ready processes are out of credits, all processes are recredited: credits = credits/2 + initial_priority note: processes that spend lots of time suspended accumulate credits interactive processes are given high priority for (soft) real-time processes , it provides priority-based FCFS and RR classes each process has a priority in addition to its scheduling class scheduler select process with highest priority if RR is indicated, processes of equal priority will time share among selves note: since user-mode process can never preempt kernel-mode process, no guarantees
- 46. Windows 2000/NT similar to BSD, Windows 2000/NT utilizes a multilevel feedback queue 32 priority levels (0 is for idle thread, 1-15 are variable class, 16-31 are real-time class) scheduler selects thread from highest numbered queue, utilizes RR thread priorities are dynamic reduced when quantum expires, boosted when unblocked & foreground window fully preemptive – whenever a thread becomes ready, it is entered into priority queue and can preempt active thread
- 47. Summary CPU scheduling is the task of selecting a waiting process from the ready queue and allocating the CPU to it. The CPU is allocated to the selected process by the dispatcher. FCFS is the simplest scheduling algorithm but it can cause short processes to wait very long. SJF provides the shortest average waiting time. Implementing SJF is difficult, due to the difficulty in predicting the length of the next CPU burst.
- 48. SJF is a special case of the general priority scheduling algorithm, which allocates the CPU to the highest-priority process. Both SJF and priority may suffer from starvation. Aging is a technique to prevent starvation. RR scheduling is appropriate for time-sharing systems. RR allocates the CPU to the first process in the ready queue for q time units. The major problem is the selection of the time quantum. If the quantum is too large, RR degenerates to FCFS; if q is too small, overhead due to context switching becomes excessive.
- 49. The FCFS algorithm is non-preemptive The RR algorithm is preemptive. The SJF and priority algorithms may be either preemptive or non-preemptive. Multi-level queue algorithm allows different algorithms to be used for various classes of processes. The most common is a foreground interactive queue which uses RR scheduling, and a background batch queue which uses FCFS scheduling. Multi-level feedback queues allow processes to move from one queue to another. **************
- 50. Next week Process synchronization critical section problem synchronization hardware semaphores high-level constructs: critical regions, monitors synchronization in Solaris 2 & Windows 2000
- 51. Review Questions for Chapter 1-3 What are Programmed I/O, Interrupt-Driven I/O, DMA? Why Interrupt-Driven I/O and DMA improve CPU utilization? What is multiprogramming? What is the main advantage of multiprogramming? What does “the degree of multiprogramming” mean? For memory system with cache, what is hit ratio? How to calculate the average access time? What are the operating system objectives and functions? Draw the five-state and the seven-state process models. Explain the meaning of each state. What common events lead to the creation of a process? What does it mean to preempt a process? What is swapping and what is its purpose?
- 52. For what types of entities does the OS maintain tables of information for management purposes? List three general categories of information in a process control block Why are two modes (user and kernel) needed? What are the steps performed by an OS to create a new process? What is the difference between an interrupt and a trap? Give three examples of an interrupt What is the difference between a mode switch and a process switch?
- 53. Note.. Increasing the degree of multiprogramming will further degrade the performance, because more processes have to be swaped in and out from memory now, the system will spend too much time in swapping than in calculation. Decreasing the degree of multiprogramming will be helpful, because it will decrease the frequency of swapping, leaving the system more time doing calculations.