Treasure Data and AWS - Developers.io 2015
29 likes8,022 views

This document discusses Treasure Data's data architecture. It describes how Treasure Data collects and imports log data using Fluentd. The data is stored in columnar format in S3 and metadata is stored in PostgreSQL. Treasure Data uses Presto to enable fast analytics on the large datasets. The document provides details on the import process, storage, partitioning, and optimizations to improve query performance.













![Realtime
Storage
PostgreSQL
Amazon S3 /
Basho Riak CS
Metadata
Import
Queue
Import
Worker
Import
Worker
Import
Worker
uploaded time file index range records
2015-03-08 10:47
[2015-12-01 10:47:11,
2015-12-01 10:48:13]
3
2015-03-08 11:09
[2015-12-01 11:09:32,
2015-12-01 11:10:35]
25
2015-03-08 11:38
[2015-12-01 11:38:43,
2015-12-01 11:40:49]
14
… … … …
Archive
Storage
Metadata of the
records in a file
(stored on
PostgreSQL)](https://image.slidesharecdn.com/developers-150329021913-conversion-gate01/85/Treasure-Data-and-AWS-Developers-io-2015-16-320.jpg)
![Amazon S3 /
Basho Riak CS
Metadata
Merge Worker
(MapReduce)
uploaded time file index range records
2015-03-08 10:47
[2015-12-01 10:47:11,
2015-12-01 10:48:13]
3
2015-03-08 11:09
[2015-12-01 11:09:32,
2015-12-01 11:10:35]
25
2015-03-08 11:38
[2015-12-01 11:38:43,
2015-12-01 11:40:49]
14
… … … …
file index range records
[2015-12-01 10:00:00,
2015-12-01 11:00:00]
3,312
[2015-12-01 11:00:00,
2015-12-01 12:00:00]
2,143
… … …
Realtime
Storage
Archive
Storage
PostgreSQL
Merge every 1 hourRetrying + Unique
(at-least-once + at-most-once)](https://image.slidesharecdn.com/developers-150329021913-conversion-gate01/85/Treasure-Data-and-AWS-Developers-io-2015-17-320.jpg)
![Amazon S3 /
Basho Riak CS
Metadata
uploaded time file index range records
2015-03-08 10:47
[2015-12-01 10:47:11,
2015-12-01 10:48:13]
3
2015-03-08 11:09
[2015-12-01 11:09:32,
2015-12-01 11:10:35]
25
2015-03-08 11:38
[2015-12-01 11:38:43,
2015-12-01 11:40:49]
14
… … … …
file index range records
[2015-12-01 10:00:00,
2015-12-01 11:00:00]
3,312
[2015-12-01 11:00:00,
2015-12-01 12:00:00]
2,143
… … …
Realtime
Storage
Archive
Storage
PostgreSQL
GiST (R-tree) Index
on“time” column on the files
Read from Archive Storage if merged.
Otherwise, from Realtime Storage](https://image.slidesharecdn.com/developers-150329021913-conversion-gate01/85/Treasure-Data-and-AWS-Developers-io-2015-18-320.jpg)



![time code method
2015-12-01 10:02:36 200 GET
2015-12-01 10:22:09 404 GET
2015-12-01 10:36:45 200 GET
2015-12-01 10:49:21 200 POST
… … …
time code method
2015-12-01 11:10:09 200 GET
2015-12-01 11:21:45 200 GET
2015-12-01 11:38:59 200 GET
2015-12-01 11:43:37 200 GET
2015-12-01 11:54:52 “200” GET
… … …
Archive
Storage
Files on Amazon S3 / Basho Riak CS
Metadata on PostgreSQL
path index range records
[2015-12-01 10:00:00,
2015-12-01 11:00:00]
3,312
[2015-12-01 11:00:00,
2015-12-01 12:00:00]
2,143
… … …
MessagePack Columnar
File Format](https://image.slidesharecdn.com/developers-150329021913-conversion-gate01/85/Treasure-Data-and-AWS-Developers-io-2015-23-320.jpg)
![time code method
2015-12-01 10:02:36 200 GET
2015-12-01 10:22:09 404 GET
2015-12-01 10:36:45 200 GET
2015-12-01 10:49:21 200 POST
… … …
time code method
2015-12-01 11:10:09 200 GET
2015-12-01 11:21:45 200 GET
2015-12-01 11:38:59 200 GET
2015-12-01 11:43:37 200 GET
2015-12-01 11:54:52 “200” GET
… … …
Archive
Storage
path index range records
[2015-12-01 10:00:00,
2015-12-01 11:00:00]
3,312
[2015-12-01 11:00:00,
2015-12-01 12:00:00]
2,143
… … …
column-based partitioning
time-based partitioning
Files on Amazon S3 / Basho Riak CS
Metadata on PostgreSQL](https://image.slidesharecdn.com/developers-150329021913-conversion-gate01/85/Treasure-Data-and-AWS-Developers-io-2015-24-320.jpg)
![time code method
2015-12-01 10:02:36 200 GET
2015-12-01 10:22:09 404 GET
2015-12-01 10:36:45 200 GET
2015-12-01 10:49:21 200 POST
… … …
time code method
2015-12-01 11:10:09 200 GET
2015-12-01 11:21:45 200 GET
2015-12-01 11:38:59 200 GET
2015-12-01 11:43:37 200 GET
2015-12-01 11:54:52 “200” GET
… … …
Archive
Storage
path index range records
[2015-12-01 10:00:00,
2015-12-01 11:00:00]
3,312
[2015-12-01 11:00:00,
2015-12-01 12:00:00]
2,143
… … …
column-based partitioning
time-based partitioning
Files on Amazon S3 / Basho Riak CS
Metadata on PostgreSQL
SELECT code, COUNT(1) FROM logs
WHERE time >= 2015-12-01 11:00:00
GROUP BY code](https://image.slidesharecdn.com/developers-150329021913-conversion-gate01/85/Treasure-Data-and-AWS-Developers-io-2015-25-320.jpg)















Treasure Data and AWS - Developers.io 2015
- 1. Masahiro Nakagawa Senior Software Engineer Treasure Data, inc. Treasure Data & AWS The light and dark side of the Cloud
- 2. Who am I > Masahiro Nakagawa > github: repeatedly > Treasure Data, Inc. > Senior Software Engineer > Fluentd / td-agent developer > Living at OSS :) > D language - Phobos, a.k.a standard library, committer > Fluentd - Main maintainer > MessagePack / RPC - D and Python (only RPC) > The organizer of several meetups (Presto, DTM, etc…) > etc…
- 3. TD Service Architecture Time to Value Send query result Result Push Acquire Analyze Store Plazma DB Flexible, Scalable, Columnar Storage Web Log App Log Censor CRM ERP RDBMS Treasure Agent(Server) SDK(JS, Android, iOS, Unity) Streaming Collector Batch / Reliability Ad-hoc / Low latency KPI$ KPI Dashboard BI Tools Other Products RDBMS, Google Docs, AWS S3, FTP Server, etc. Metric Insights Tableau, Motion Board etc. POS REST API ODBC / JDBC SQL, Pig Bulk Uploader Embulk, TD Toolbelt SQL-based query @AWS or @IDCF Connectivity Economy & Flexibility Simple & Supported
- 4. Treasure Data System Overview Frontend Job Queue Worker Hadoop Presto Fluentd Applications push metrics to Fluentd (via local Fluentd) Datadog for realtime monitoring Treasure Data for historical analysis Fluentd sums up data minutes (partial aggregation)
- 5. Plazma - Treasure Data’s distributed analytical database
- 6. Plazma by the numbers > Data import > 500,000 records / sec > 43 billion records / day > Hive Query > 2 trillion records / day > 2,828 TB/day > Presto Query > 10,000+ queries / day
- 7. Used AWS components > EC2 > Hadoop / Presto Clusters > API Servers > S3 > MessagePack Columnar Storage > RDS > MySQL for service information > PostgreSQL for Plazma metadata > Distributed Job Queue / Schedular
- 8. Used AWS components > CloudWatch > Monitor AWS service metrics > ELB > Endpoint for APIs > Endpoint for Heroku drains > ElastiCache > Store TD monitoring data > Event de-duplication for mobile SDKs
- 9. Why not use HDFS for storage? > To separate machine resource and storage > Easy to add or replace workers > Import load doesn’t affect queries > Don’t want to maintain HDFS… > HDFS crash > Upgrading HDFS cluster is hard > The demerit of S3 based storage > Eventual consistency > Network access
- 10. Data Importing
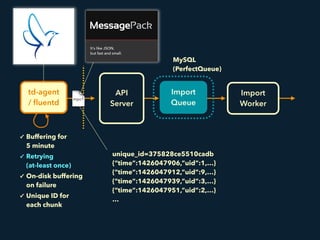
- 11. Import Queue td-agent / fluentd Import Worker ✓ Buffering for 5 minute ✓ Retrying (at-least once) ✓ On-disk buffering on failure ✓ Unique ID for each chunk API Server It’s like JSON. but fast and small. unique_id=375828ce5510cadb {“time”:1426047906,”uid”:1,…} {“time”:1426047912,”uid”:9,…} {“time”:1426047939,”uid”:3,…} {“time”:1426047951,”uid”:2,…} … MySQL (PerfectQueue)
- 12. Import Queue td-agent / fluentd Import Worker ✓ Buffering for 1 minute ✓ Retrying (at-least once) ✓ On-disk buffering on failure ✓ Unique ID for each chunk API Server It’s like JSON. but fast and small. MySQL (PerfectQueue) unique_id time 375828ce5510cadb 2015-12-01 10:47 2024cffb9510cadc 2015-12-01 11:09 1b8d6a600510cadd 2015-12-01 11:21 1f06c0aa510caddb 2015-12-01 11:38
- 13. Import Queue td-agent / fluentd Import Worker ✓ Buffering for 5 minute ✓ Retrying (at-least once) ✓ On-disk buffering on failure ✓ Unique ID for each chunk API Server It’s like JSON. but fast and small. MySQL (PerfectQueue) unique_id time 375828ce5510cadb 2015-12-01 10:47 2024cffb9510cadc 2015-12-01 11:09 1b8d6a600510cadd 2015-12-01 11:21 1f06c0aa510caddb 2015-12-01 11:38UNIQUE (at-most once)
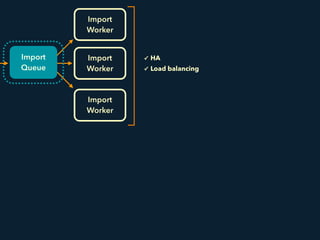
- 15. Realtime Storage PostgreSQL Amazon S3 / Basho Riak CS Metadata Import Queue Import Worker Import Worker Import Worker Archive Storage
- 16. Realtime Storage PostgreSQL Amazon S3 / Basho Riak CS Metadata Import Queue Import Worker Import Worker Import Worker uploaded time file index range records 2015-03-08 10:47 [2015-12-01 10:47:11, 2015-12-01 10:48:13] 3 2015-03-08 11:09 [2015-12-01 11:09:32, 2015-12-01 11:10:35] 25 2015-03-08 11:38 [2015-12-01 11:38:43, 2015-12-01 11:40:49] 14 … … … … Archive Storage Metadata of the records in a file (stored on PostgreSQL)
- 17. Amazon S3 / Basho Riak CS Metadata Merge Worker (MapReduce) uploaded time file index range records 2015-03-08 10:47 [2015-12-01 10:47:11, 2015-12-01 10:48:13] 3 2015-03-08 11:09 [2015-12-01 11:09:32, 2015-12-01 11:10:35] 25 2015-03-08 11:38 [2015-12-01 11:38:43, 2015-12-01 11:40:49] 14 … … … … file index range records [2015-12-01 10:00:00, 2015-12-01 11:00:00] 3,312 [2015-12-01 11:00:00, 2015-12-01 12:00:00] 2,143 … … … Realtime Storage Archive Storage PostgreSQL Merge every 1 hourRetrying + Unique (at-least-once + at-most-once)
- 18. Amazon S3 / Basho Riak CS Metadata uploaded time file index range records 2015-03-08 10:47 [2015-12-01 10:47:11, 2015-12-01 10:48:13] 3 2015-03-08 11:09 [2015-12-01 11:09:32, 2015-12-01 11:10:35] 25 2015-03-08 11:38 [2015-12-01 11:38:43, 2015-12-01 11:40:49] 14 … … … … file index range records [2015-12-01 10:00:00, 2015-12-01 11:00:00] 3,312 [2015-12-01 11:00:00, 2015-12-01 12:00:00] 2,143 … … … Realtime Storage Archive Storage PostgreSQL GiST (R-tree) Index on“time” column on the files Read from Archive Storage if merged. Otherwise, from Realtime Storage
- 19. Why not use LIST API? > LIST API is slow > It causes slow query on large dataset > Riak CS’s LIST is also toooo slow! > LIST API has a critical problem… ;( > LIST skips some objects when high-loaded environment > It doesn’t return an error… > Using PostgreSQL improves the performance > Easy to check time range > Operation cost is cheaper than S3 call
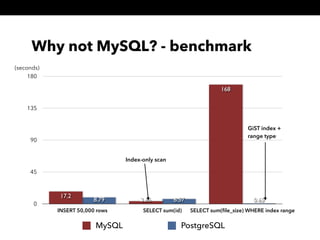
- 20. Why not MySQL? - benchmark 0 45 90 135 180 INSERT 50,000 rows SELECT sum(id) SELECT sum(file_size) WHERE index range 0.656.578.79 168 3.66 17.2 MySQL PostgreSQL (seconds) Index-only scan GiST index + range type
- 21. Data Importing > Scalable & Reliable importing > Fluentd buffers data on a disk > Import queue deduplicates uploaded chunks > Workers take the chunks and put to Realtime Storage > Instant visibility > Imported data is immediately visible by query engines. > Background workers merges the files every 1 hour. > Metadata > Index is built on PostgreSQL using RANGE type and GiST index
- 22. Data processing
- 23. time code method 2015-12-01 10:02:36 200 GET 2015-12-01 10:22:09 404 GET 2015-12-01 10:36:45 200 GET 2015-12-01 10:49:21 200 POST … … … time code method 2015-12-01 11:10:09 200 GET 2015-12-01 11:21:45 200 GET 2015-12-01 11:38:59 200 GET 2015-12-01 11:43:37 200 GET 2015-12-01 11:54:52 “200” GET … … … Archive Storage Files on Amazon S3 / Basho Riak CS Metadata on PostgreSQL path index range records [2015-12-01 10:00:00, 2015-12-01 11:00:00] 3,312 [2015-12-01 11:00:00, 2015-12-01 12:00:00] 2,143 … … … MessagePack Columnar File Format
- 24. time code method 2015-12-01 10:02:36 200 GET 2015-12-01 10:22:09 404 GET 2015-12-01 10:36:45 200 GET 2015-12-01 10:49:21 200 POST … … … time code method 2015-12-01 11:10:09 200 GET 2015-12-01 11:21:45 200 GET 2015-12-01 11:38:59 200 GET 2015-12-01 11:43:37 200 GET 2015-12-01 11:54:52 “200” GET … … … Archive Storage path index range records [2015-12-01 10:00:00, 2015-12-01 11:00:00] 3,312 [2015-12-01 11:00:00, 2015-12-01 12:00:00] 2,143 … … … column-based partitioning time-based partitioning Files on Amazon S3 / Basho Riak CS Metadata on PostgreSQL
- 25. time code method 2015-12-01 10:02:36 200 GET 2015-12-01 10:22:09 404 GET 2015-12-01 10:36:45 200 GET 2015-12-01 10:49:21 200 POST … … … time code method 2015-12-01 11:10:09 200 GET 2015-12-01 11:21:45 200 GET 2015-12-01 11:38:59 200 GET 2015-12-01 11:43:37 200 GET 2015-12-01 11:54:52 “200” GET … … … Archive Storage path index range records [2015-12-01 10:00:00, 2015-12-01 11:00:00] 3,312 [2015-12-01 11:00:00, 2015-12-01 12:00:00] 2,143 … … … column-based partitioning time-based partitioning Files on Amazon S3 / Basho Riak CS Metadata on PostgreSQL SELECT code, COUNT(1) FROM logs WHERE time >= 2015-12-01 11:00:00 GROUP BY code
- 26. Handling Eventual Consistency 1. Writing data / metadata first > At this time, data is not visible 2. Check S3 data is available or not > GET, GET, GET… 3. S3 data become visible > Query includes imported data! Ex. Netflix case > https://github.com/Netflix/s3mper
- 27. Hide network cost > Open a lot of connections to S3 > Using range feature with columnar offset > Improve scan performance for partitioned data > Detect recoverable error > We have error lists for fault tolerance > Stall checker > Watch the progress of reading data > If processing time reached threshold, re-connect to S3 and re-read data
- 28. buffer Optimizing Scan Performance • Fully utilize the network bandwidth from S3 • TD Presto becomes CPU bottleneck 8 TableScanOperator • s3 file list • table schema header request S3 / RiakCS • release(Buffer) Buffer size limit Reuse allocated buffers Request Queue • priority queue • max connections limit Header Column Block 0 (column names) Column Block 1 Column Block i Column Block m MPC1 file HeaderReader • callback to HeaderParser ColumnBlockReader header HeaderParser • parse MPC file header • column block offsets • column names column block request Column block requests column block prepare MessageUnpacker buffer MessageUnpacker MessageUnpacker S3 read S3 read pull records Retry GET request on - 500 (internal error) - 503 (slow down) - 404 (not found) - eventual consistency S3 read• decompression • msgpack-java v07 S3 read S3 read S3 read Optimize scan performance
- 29. Recoverable errors > Error types > User error > Syntax error, Semantic error > Insufficient resource > Exceeded task memory size > Internal failure > I/O error of S3 / Riak CS > worker failure > etc We can retry these patterns
- 30. Recoverable errors > Error types > User error > Syntax error, Semantic error > Insufficient resource > Exceeded task memory size > Internal failure > I/O error of S3 / Riak CS > worker failure > etc We can retry these patterns
- 31. Presto retry on Internal Errors > Query succeed eventually log scale
- 32. time code method 2015-12-01 10:02:36 200 GET 2015-12-01 10:22:09 404 GET 2015-12-01 10:36:45 200 GET 2015-12-01 10:49:21 200 POST … … … user time code method 391 2015-12-01 11:10:09 200 GET 482 2015-12-01 11:21:45 200 GET 573 2015-12-01 11:38:59 200 GET 664 2015-12-01 11:43:37 200 GET 755 2015-12-01 11:54:52 “200” GET … … …
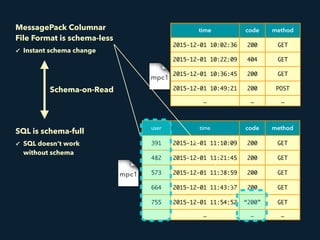
- 33. time code method 2015-12-01 10:02:36 200 GET 2015-12-01 10:22:09 404 GET 2015-12-01 10:36:45 200 GET 2015-12-01 10:49:21 200 POST … … … user time code method 391 2015-12-01 11:10:09 200 GET 482 2015-12-01 11:21:45 200 GET 573 2015-12-01 11:38:59 200 GET 664 2015-12-01 11:43:37 200 GET 755 2015-12-01 11:54:52 “200” GET … … … MessagePack Columnar File Format is schema-less ✓ Instant schema change SQL is schema-full ✓ SQL doesn’t work without schema Schema-on-Read
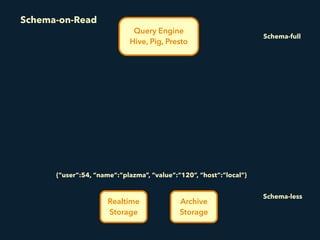
- 34. Realtime Storage Query Engine Hive, Pig, Presto Archive Storage {“user”:54, “name”:”plazma”, “value”:”120”, “host”:”local”} Schema-on-Read Schema-full Schema-less
- 35. Realtime Storage Query Engine Hive, Pig, Presto Archive Storage Schema-full Schema-less Schema {“user”:54, “name”:”plazma”, “value”:”120”, “host”:”local”} CREATE TABLE events ( user INT, name STRING, value INT, host INT ); | user | 54 | name | “plazma” | value | 120 | host | NULL | | Schema-on-Read
- 36. Realtime Storage Query Engine Hive, Pig, Presto Archive Storage {“user”:54, “name”:”plazma”, “value”:”120”, “host”:”local”} CREATE TABLE events ( user INT, name STRING, value INT, host INT ); | user | 54 | name | “plazma” | value | 120 | host | NULL | | Schema-on-Read Schema-full Schema-less Schema
- 37. Monitoring
- 38. Datadog based monitoring > dd-agent for system metrics > Send application metrics using Fluentd > Hadoop / Presto usage > Service metrics > PostgreSQL status > Check AWS events > EC2, CloudTrail and more > Event based alert
- 40. Presto example
- 41. Pitfall of PostgreSQL on RDS > PostgreSQL on RDS has TCP Proxy > “DB connections” metrics shows TCP connections, not execution processes of PostgreSQL > PostgreSQL spawns a process for each TCP connection > The problem is the process is sometimes still running even if TCP connection is closed. > In this result, “DB connections” is decreased but PostgreSQL can’t receive new request ;( > We collect actual metrics from PostgreSQL tables. > Can’t use some extensions
- 42. Conclusion > Build scalable data analytics platform on Cloud > Separate resource and storage > loosely-coupled components > AWS has some pitfalls but we can avoid it > There are many trade-off > Use existing component or create new component? > Stick to the basics!
- 43. Check: treasuredata.com treasure-data.hateblo.jp/ (Japan blog) Cloud service for the entire data pipeline