
























01_Architecture_JFV14_01_Architecture_JFV14.ppt
- 1. 1 Copyright © 2005, Oracle. All rights reserved. Architecture and Concepts
- 2. Copyright © 2005, Oracle. All rights reserved. 1-2 Objectives After completing this lesson, you should be able to do the following: • List the various components of Cluster Ready Services (CRS) and Real Application Clusters (RAC) • Describe the various types of files used by a RAC database • Describe the various techniques used to share database files across a cluster • Describe the purpose of using services with RAC
- 3. Copyright © 2005, Oracle. All rights reserved. 1-3 Complete Integrated Cluster Ware Management APIs Hardware/OS kernel Hardware/OS kernel Connectivity Membership Messaging and Locking Volume Manager file system Applications Cluster control Event Services System Management Applications/RAC Services framework Cluster control/Recovery APIs Automatic Storage Management Messaging and Locking Membership Connectivity Event Services 9i RAC 10g RAC
- 4. Copyright © 2005, Oracle. All rights reserved. 1-4 RAC Software Principles Node1 Instance1 Cluster Ready Services CRSD & RACGIMON OCSSD & OPROCD EVMD LMON LMD0 LMSx DIAG … Cache Noden Instancen Cluster Applications VIP, ONS, EMD, Listener Cluster Ready Services CRSD & RACGIMON OCSSD & OPROCD EVMD ASM, DB, Services, OCR Applications VIP, ONS, EMD, Listener ASM, DB, Services, OCR Global management: SRVCTL, DBCA, EM Cluster interface LCK0 LMON LMD0 LMSx DIAG … Cache LCK0 Global resources
- 5. Copyright © 2005, Oracle. All rights reserved. 1-5 RAC Software Storage Principles Node1 Instance1 CRS home Local storage Oracle home Noden Instancen CRS home Local storage Oracle home … Voting file OCR file Node1 Instance1 Local storage Noden Instancen Local storage … Shared storage Voting file OCR file CRS home Oracle home Permits online patch upgrades Software not a single point of failure Shared storage
- 6. Copyright © 2005, Oracle. All rights reserved. 1-6 OCR Architecture Node1 OCR cache OCR process Client process Node2 OCR cache OCR process Node3 OCR cache OCR process Client process OCR file Shared storage
- 7. Copyright © 2005, Oracle. All rights reserved. 1-7 RAC Database Storage Principles Node1 Instance1 Shared storage … Noden Instancen Online redo log files for instance1 Online redo log files for instancen Data files Undo tablespace files for instance1 Undo tablespace files for instancen Flash recovery area files Change tracking file SPFILE Control files Temp files Archived log files Local storage Archived log files Local storage
- 8. Copyright © 2005, Oracle. All rights reserved. 1-8 RAC and Shared Storage Technologies • Storage is a critical component of grids: – Sharing storage is fundamental – New technology trends • Supported shared storage for Oracle grids: – Network Attached Storage – Storage Area Network • Supported file systems for Oracle grids: – Raw volumes – Cluster file system – ASM
- 9. Copyright © 2005, Oracle. All rights reserved. 1-10 Oracle Cluster File System • Is a shared disk cluster file system for Linux and Windows • Improves management of data for RAC by eliminating the need to manage raw devices • Provides open solution on the operating system side (Linux) free and open source • Can be downloaded from OTN: http://oss.oracle.com/software
- 10. Copyright © 2005, Oracle. All rights reserved. 1-11 Automatic Storage Management • Portable and high-performance cluster file system • Manages Oracle database files • Data spread across disks to balance load • Integrated mirroring across disks • Solves many storage management challenges ASM File system Volume manager Operating system Application Database
- 11. Copyright © 2005, Oracle. All rights reserved. 1-12 Raw or CFS? • Using CFS: – Simpler management – Use of OMF with RAC – Single Oracle software installation – Autoextend • Using raw: – Performance – Use when CFS not available – Cannot be used for archivelog files (on UNIX)
- 12. Copyright © 2005, Oracle. All rights reserved. 1-13 Typical Cluster Stack with RAC High-speed Interconnect: Gigabit Ethernet UDP Proprietary Proprietary Database shared storage Interconnect Servers Oracle CRS RAC Linux, UNIX, Windows ASM RAC Linux Windows RAW RAC Linux Windows OCFS RAC AIX, HP-UX, Solaris ASM OS C/W RAW OS CVM CFS
- 13. Copyright © 2005, Oracle. All rights reserved. 1-14 RAC Certification Matrix 1. Connect and log in to http://metalink.oracle.com 2. Click the Certify and Availability button on the menu frame 3. Click the View Certifications by Product link 4. Select Real Application Clusters 5. Select the correct platform
- 14. Copyright © 2005, Oracle. All rights reserved. 1-15 The Necessity of Global Resources 1008 SGA1 SGA2 1008 SGA1 SGA2 1008 1008 SGA1 SGA2 1008 SGA1 SGA2 1009 1008 1009 Lost updates! 1 2 3 4
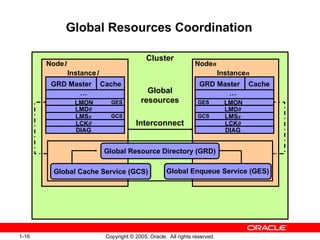
- 15. Copyright © 2005, Oracle. All rights reserved. 1-16 LMON LMD0 LMSx DIAG … LCK0 Cache GRD Master GES GCS LMON LMD0 LMSx DIAG … Cache LCK0 GRD Master GES GCS Global Resources Coordination Node1 Instance1 Noden Instancen Cluster Interconnect Global resources Global Enqueue Service (GES) Global Cache Service (GCS) Global Resource Directory (GRD)
- 16. Copyright © 2005, Oracle. All rights reserved. 1-17 Global Cache Coordination: Example Node1 Instance1 Node2 Instance2 … Cache Cluster 1009 1008 1 2 3 GCS 4 No disk I/O LMON LMD0 LMSx … LCK0 Cache 1009 DIAG LMON LMD0 LMSx LCK0 DIAG Block mastered by instance one Which instance masters the block? Instance two has the current version of the block
- 17. Copyright © 2005, Oracle. All rights reserved. 1-18 Write to Disk Coordination: Example Node1 Instance1 Node2 Instance2 Cache Cluster 1010 1010 1 3 2 GCS 4 5 Only one disk I/O LMON LMD0 LMSx LCK0 DIAG LMON LMD0 LMSx LCK0 DIAG … … Cache 1009 Need to make room in my cache. Who has the current version of that block? Instance two owns it. Instance two, flush the block to disk Block flushed, make room
- 18. Copyright © 2005, Oracle. All rights reserved. 1-19 RAC and Instance/Crash Recovery Recovery time SMON recovers the database Remaster enqueue resources Remaster cache resources Build re- covery set LMON recovers GRD Merge failed redo threads 1 2 3 5 Resource claim 4 Roll forward recovery set Use information for other caches
- 19. Copyright © 2005, Oracle. All rights reserved. 1-21 Instance Recovery and Database Availability Elapsed time Databa se availab ility None Partial Full A B C D E G H F 1 2 3 4 5 2
- 20. Copyright © 2005, Oracle. All rights reserved. 1-22 Efficient Inter-Node Row-Level Locking Node1 Instance1 Node2 Instance2 UPDATE Node1 Instance1 Node2 Instance2 UPDATE Node1 Instance1 Node2 Instance2 UPDATE Node1 Instance1 Node2 Instance2 COMMIT No block-level lock 1 2 3 4
- 21. Copyright © 2005, Oracle. All rights reserved. 1-23 Additional Memory Requirement for RAC • Heuristics for scalability cases: – 15% more shared pool – 10% more buffer cache • Smaller buffer cache per instance in the case of single-instance workload distributed across multiple instances • Current values: SELECT resource_name, current_utilization,max_utilization FROM v$resource_limit WHERE resource_name like 'g%s_%';
- 22. Copyright © 2005, Oracle. All rights reserved. 1-24 Parallel Execution with RAC Execution slaves have node affinity with the execution coordinator, but will expand if needed. Execution coordinator Parallel execution server Shared disks Node 4 Node 1 Node 2 Node 3
- 23. Copyright © 2005, Oracle. All rights reserved. 1-25 Global Dynamic Performance Views • Store information about all started instances • One global view for each local view • Use one parallel slave on each instance • Make sure that PARALLEL_MAX_SERVERS is big enough Node1 Instance1 Noden Instancen Cluster V$INSTANCE V$INSTANCE GV$INSTANCE
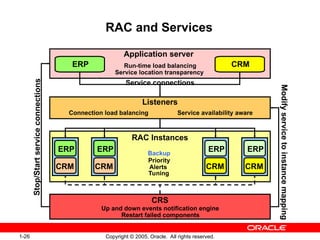
- 24. Copyright © 2005, Oracle. All rights reserved. 1-26 RAC and Services Up and down events notification engine Listeners RAC Instances Application server ERP CRM ERP ERP ERP ERP CRM CRM CRM CRM Stop/Start service connection s Modify service to instance mapping Service connections Backup Priority Alerts Tuning Connection load balancing Service availability aware CRS Run-time load balancing Service location transparency Restart failed components
- 25. Copyright © 2005, Oracle. All rights reserved. 1-27 Virtual IP Addresses and RAC ERP=(DESCRIPTION= ((HOST=clusnode-1vip)) ((HOST=clusnode-2vip)) (SERVICE_NAME=ERP)) clnode-1 ERP=(DESCRIPTION= ((HOST=clusnode-1)) ((HOST=clusnode-2)) (SERVICE_NAME=ERP)) Timeout wait clnode-2 clnode-1 clnode-2 2 5 3 7 clnode-1vip clnode-2vip 2 clnode-1vip clnode-2vip 3 4 7 Clients 1 4 6 1 5 6
- 26. Copyright © 2005, Oracle. All rights reserved. 1-28 Database Control and RAC Cluster Cluster Database Home Cluster Database Performance Cluster Database Administration Cluster Database Cluster Home Cluster Performance Cluster Targets Cluster Database Maintenance Node1 Instance1 DB Control Agent OC4J EM App Node2 Instance2 Agent OC4J EM App DB & Rep
- 27. Copyright © 2005, Oracle. All rights reserved. 1-29 Summary In this lesson, you should have learned how to: • Recognize the various components of CRS and RAC • Use the various types of files in a RAC database • Share database files across a cluster • Use services with RAC
Editor's Notes
- #3: Complete Integrated Cluster Ware With Oracle9i, Oracle introduced Real Application Clusters. For the first time, you were able to run online transaction processing (OLTP) and decision support system (DSS) applications against a database cluster without having to make expensive code changes or spend large amounts of valuable administrator time partitioning and repartitioning the database to achieve good performance. Although Oracle9i Real Application Clusters did much to ease the task of allowing applications to work in clusters, there are still support challenges and limitations. Among these cluster challenges are complex software environments, support, inconsistent features across platforms, and awkward management interaction across the software stack. Most clustering solutions today were designed with failover in mind. Failover clustering has additional systems standing by in case of a failure. During normal operations, these failover resources may sit idle. With the release of Oracle Database 10g, Oracle provides you with an integrated software solution that addresses cluster management, event management, application management, connection management, storage management, load balancing, and availability. These capabilities are addressed while hiding the complexity through simple-to-use management tools and automation. Real Application Clusters 10g provides an integrated cluster ware layer that delivers a complete environment for applications.
- #4: RAC Software Principles You may see a few additional background processes associated with a RAC instance than you would with a single-instance database. These processes are primarily used to maintain database coherency among each instance. They manage what is called the global resources: LMON: Global Enqueue Service Monitor LMD0: Global Enqueue Service Daemon LMSx: Global Cache Service Processes, where x can range from 0 to j LCK0: Lock process DIAG: Diagnosibility process At the cluster level, you find the main processes of the Cluster Ready Services software. They provide a standard cluster interface on all platforms and perform high-availability operations. You find these processes on each node of the cluster: CRSD and RACGIMON: Are engines for high-availability operations OCSSD: Provides access to node membership and group services EVMD: Scans callout directory and invokes callouts in reactions to detected events OPROCD: Is a process monitor for the cluster There are also several tools that are used to manage the various resources available on the cluster at a global level. These resources are the Automatic Storage Management (ASM) instances, the RAC databases, the services, and CRS node applications. Some of the tools that you will use throughout this course are Server Control (SRVCTL), DBCA, and Enterprise Manager.
- #5: RAC Software Storage Principles The Oracle Database 10g Real Application Clusters installation is a two-phase installation. In the first phase, you install CRS. In the second phase, you install the Oracle database software with RAC components and create a cluster database. The Oracle home that you use for the CRS software must be different from the one that is used for the RAC software. Although it is possible to install the CRS and RAC software on your cluster shared storage when using certain cluster file systems, software is usually installed on a regular file system that is local to each node. This permits online patch upgrades and eliminates the software as a single point of failure. In addition, two files must be stored on your shared storage: The voting file is essentially used by the Cluster Synchronization Services daemon for node monitoring information across the cluster. Its size is set to around 20 MB. The Oracle Cluster Registry (OCR) file is also a key component of the CRS. It maintains information about the high-availability components in your cluster such as the cluster node list, cluster database instance to node mapping, and CRS application resource profiles (such as services, Virtual Interconnect Protocol addresses, and so on). This file is maintained automatically by administrative tools such as SRVCTL. Its size is around 100 MB. The voting and OCR files cannot be stored in ASM because they must be accessible before starting any Oracle instance. OCR and voting files must be on redundant, reliable storage such as RAID. The recommended best practice location for those files is raw devices.
- #6: OCR Architecture Cluster configuration information is maintained in Oracle Cluster Registry. OCR relies on a distributed shared-cache architecture for optimizing queries against the cluster repository. Each node in the cluster maintains an in-memory copy of OCR, along with an OCR process that accesses its OCR cache. Only one of the OCR processes actually reads from and writes to the OCR file on shared storage. This process is responsible for refreshing its own local cache, as well as the OCR cache on other nodes in the cluster. For queries against the cluster repository, the OCR clients communicate directly with the local OCR process on the node from which they originate. When clients need to update the OCR, they communicate through their local OCR process to the OCR process that is performing input/output (I/O) for writing to the repository on disk. The OCR client applications are Oracle Universal Installer (OUI), SRVCTL, Enterprise Manager (EM), Database Configuration Assistant (DBCA), Database Upgrade Assistant (DBUA), NetCA, and Virtual Internet Protocol Configuration Assistant (VIPCA). Furthermore, OCR maintains dependency and status information for application resources defined within CRS, specifically databases, instances, services, and node applications. The name of the configuration file is ocr.loc, and the configuration file variable is ocrconfig_loc. The location for the cluster repository is not restricted to raw devices. You can put OCR on shared storage that is managed by a Cluster File System. Note: OCR also serves as a configuration file in a single instance with the ASM, where there is one OCR per node.
- #7: RAC Database Storage Principles The primary difference between RAC storage and storage for single-instance Oracle databases is that all data files in RAC must reside on shared devices (either raw devices or cluster file systems) in order to be shared by all the instances that access the same database. You must also create at least two redo log groups for each instance, and all the redo log groups must also be stored on shared devices for instance or crash recovery purposes. Each instance’s online redo log groups are called an instance’s thread of online redo. In addition, you must create one shared undo tablespace for each instance for using the recommended automatic undo management feature. Each undo tablespace must be shared by all instances for recovery purposes. Archive logs cannot be placed on raw devices because their names are automatically generated and different for each one. That is why they must be stored on a file system. If you are using a cluster file system (CFS), it enables you to access these archive files from any node at any time. If you are not using a CFS, you are always forced to make the archives available to the other cluster members at the time of recovery; for example by using a network file system (NFS) across nodes. If you are using the recommended flash recovery area feature, then it must be stored in a shared directory so that all instances can access it. Note: A shared directory can be an ASM disk group, or a Cluster File System.
- #8: RAC and Shared Storage Technologies Storage is a critical component of any grid solution. Traditionally, storage has been directly attached to each individual server (DAS). Over the past few years, more flexible storage, which is accessible over storage area networks or regular Ethernet networks, has become popular. These new storage options enable multiple servers to access the same set of disks, simplifying provisioning of storage in any distributed environment. Storage Area Network (SAN) represents the evolution of data storage technology to this point. Traditionally, on client server systems, data was stored on devices either inside or directly attached to the server. Next in the evolutionary scale came Network Attached Storage (NAS) that took the storage devices away from the server and connected them directly to the network. SANs take the principle a step further by allowing storage devices to exist on their own separate networks and communicate directly with each other over very fast media. Users can gain access to these storage devices through server systems that are connected to both the local area network (LAN) and SAN. As you already saw, the choice of file system is critical for RAC deployment. Traditional file systems do not support simultaneous mounting by more than one system. Therefore, you must store files in either raw volumes without any file system, or on a file system that supports concurrent access by multiple systems.
- #9: RAC and Shared Storage Technologies (continued) Thus, three major approaches exist for providing the shared storage needed by RAC: Raw volumes: These are directly attached raw devices that require storage that operates in block mode such as fiber channel or iSCSI. Cluster File System: One or more cluster file systems can be used to hold all RAC files. Cluster file systems require block mode storage such as fiber channel or iSCSI. Automatic Storage Management (ASM) is a portable, dedicated, and optimized cluster file system for Oracle database files. Note: iSCSI is important to SAN technology because it enables a SAN to be deployed in a local area network (LAN), wide area network (WAN), or Metropolitan Area Network (MAN).
- #10: Oracle Cluster File System Oracle Cluster File System (OCFS) is a shared file system designed specifically for Oracle Real Application Clusters. OCFS eliminates the requirement that Oracle database files be linked to logical drives and enables all nodes to share a single Oracle Home (on Windows 2000 only), instead of requiring each node to have its own local copy. OCFS volumes can span one shared disk or multiple shared disks for redundancy and performance enhancements. Following is a list of files that can be placed on an Oracle Cluster File System: Oracle software installation: Currently, this configuration is only supported on Windows 2000. The next major version will provide support for Oracle Home on Linux as well. Oracle files (control files, data files, redo logs, bfiles, and so on) Shared configuration files (spfile) Files created by Oracle during run time Voting and OCR files Oracle Cluster File System is free for developers and customers. The source code is provided under the General Public License (GPL) on Linux. It can be downloaded from the Oracle Technology Network Web site. Note: Please see the release notes for platform-specific limitations for OCFS.
- #11: Automatic Storage Management The Automatic Storage Management (ASM) is a new feature in Oracle Database 10g. It provides a vertical integration of the file system and the volume manager that is specifically built for Oracle database files. The ASM can provide management for single SMP machines or across multiple nodes of a cluster for Oracle Real Application Clusters support. The ASM distributes I/O load across all available resources to optimize performance while removing the need for manual I/O tuning. It helps DBAs manage a dynamic database environment by allowing them to increase the database size without having to shut down the database to adjust the storage allocation. The ASM can maintain redundant copies of data to provide fault tolerance, or it can be built on top of vendor-supplied, reliable storage mechanisms. Data management is done by selecting the desired reliability and performance characteristics for classes of data rather than with human interaction on a per-file basis. The ASM capabilities save DBAs time by automating manual storage and thereby increasing their ability to manage larger databases (and more of them) with increased efficiency. Note: ASM is the strategic and stated direction as to where Oracle database files should be stored. However, OCFS will continue to be developed and supported for those who are using it.
- #12: Raw or CFS? As already explained, you can either use a cluster file system or place files on raw devices. Cluster file systems provide the following advantages: Greatly simplify the installation and administration of RAC Use of Oracle Managed Files with RAC Single Oracle software installation Autoextend enabled on Oracle data files Uniform accessibility to archive logs in case of physical node failure Raw devices implications: Raw devices are always used when CFS is not available or not supported by Oracle. Raw devices offer best performance without any intermediate layer between Oracle and the disk. Autoextend fails on raw devices if the space is exhausted. ASM, Logical Storage Managers, or Logical Volume Managers can ease the work with raw devices. Also, they can enable you to add space to a raw device online, or you may be able to create raw device names that make the usage of this device clear to the system administrators.
- #13: Typical Cluster Stack with RAC Each node in a cluster requires a supported interconnect software protocol to support inter-instance communication, and Transmission Control Protocol/Internet Protocol (TCP/IP) to support CRS polling. All UNIX platforms use User Datagram Protocol (UDP) on Gigabit Ethernet as one of the primary protocols and interconnect for RAC inter-instance IPC communication. Other supported vendor-specific interconnect protocols include Remote Shared Memory for SCI and SunFire Link interconnects, and Hyper Messaging Protocol for Hyperfabric interconnects. In any case, your interconnect must be certified by Oracle for your platform. Using Oracle clusterware, you can reduce installation and support complications. However, vendor clusterware may be needed if customers use non-Ethernet interconnect or if you have deployed clusterware-dependent applications on the same cluster where you deploy RAC. Similar to the interconnect, the shared storage solution you choose must be certified by Oracle for your platform. If a cluster file system (CFS) is available on the target platform, then both the database area and flash recovery area can be created on either CFS or ASM. If a CFS is unavailable on the target platform, then the database area can be created either on ASM or on raw devices (with the required volume manager), and the flash recovery area must be created on the ASM.
- #14: RAC Certification Matrix Real Application Clusters Certification Matrix is designed to address any certification inquiries. Use this matrix to answer any certification questions that are related to RAC. To navigate to Real Application Clusters Certification Matrix, perform the steps shown in the slide above.
- #15: The Necessity of Global Resources In single-instance environments, locking coordinates access to a common resource such as a row in a table. Locking prevents two processes from changing the same resource (or row) at the same time. In RAC environments, internode synchronization is critical because it maintains proper coordination between processes on different nodes, preventing them from changing the same resource at the same time. Internode synchronization guarantees that each instance sees the most recent version of a block in its buffer cache. Note: The slide shows you what can happen in the absence of cache coordination.
- #16: Global Resources Coordination Cluster operations require synchronization among all instances to control shared access to resources. RAC uses the Global Resource Directory (GRD) to record information about how resources are used within a cluster database. The Global Cache Service (GCS) and Global Enqueue Service (GES) manage the information in the GRD. Each instance maintains a part of the GRD in its System Global Area (SGA). The GCS and GES nominate one instance to manage all information about a particular resource. This instance is called the resource master. Also, each instance knows which instance masters which resource. Maintaining cache coherency is an important part of a RAC activity. Cache coherency is the technique of keeping multiple copies of a block consistent between different Oracle instances. GCS implements cache coherency by using what is called the Cache Fusion algorithm. The GES manages all non-Cache Fusion inter-instance resource operations and tracks the status of all Oracle enqueuing mechanisms. The primary resources of the GES controls are dictionary cache locks and library cache locks. The GES also performs deadlock detection to all deadlock-sensitive enqueues and resources.
- #17: Global Cache Coordination: Example The scenario described in the slide assumes that the data block has been changed, or dirtied, by the first instance. Furthermore, only one copy of the block exists clusterwide, and the content of the block is represented by its SCN. 1. The second instance attempting to modify the block submits a request to the GCS. 2. The GCS transmits the request to the holder. In this case, the first instance is the holder. 3. The first instance receives the message and sends the block to the second instance. The first instance retains the dirty buffer for recovery purposes. This dirty image of the block is also called a past image of the block. A past image block cannot be modified further. 4. On receipt of the block, the second instance informs the GCS that it holds the block. Note: The data block is not written to disk before the resource is granted to the second instance.
- #18: Write to Disk Coordination: Example The scenario described in the slide illustrates how an instance can perform a checkpoint at any time or replace buffers in the cache due to free buffer requests. Because multiple versions of the same data block with different changes can exist in the caches of instances in the cluster, a write protocol managed by the GCS ensures that only the most current version of the data is written to disk. It must also ensure that all previous versions are purged from the other caches. A write request for a data block can originate in any instance that has the current or past image of the block. In this scenario, assume that the first instance holding a past image buffer requests that Oracle writes the buffer to disk: 1. The first instance sends a write request to the GCS. 2. The GCS forwards the request to the second instance, the holder of the current version of the block. 3. The second instance receives the write request and writes the block to disk. 4. The second instance records the completion of the write operation with the GCS. 5. After receipt of the notification, the GCS orders all past image holders to discard their past images. These past images are no longer needed for recovery. Note: In this case, only one I/O is performed to write the most current version of the block to disk.
- #19: RAC and Instance/Crash Recovery When an instance fails and the failure is detected by another instance, the second instance performs the following recovery steps: 1. During the first phase of recovery, GES remasters the enqueues. 2. Then the GCS remasters its resources. The GCS processes remaster only those resources that lose their masters. During this time, all GCS resource requests and write requests are temporarily suspended. However, transactions can continue to modify data blocks as long as these transactions have already acquired the necessary resources. 3. After enqueues are reconfigured, one of the surviving instances can grab the Instance Recovery enqueue. Therefore, at the same time as GCS resources are remastered, SMON determines the set of blocks that need recovery. This set is called the recovery set. Because, with Cache Fusion, an instance ships the contents of its blocks to the requesting instance without writing the blocks to the disk, the on-disk version of the blocks may not contain the changes that are made by either instance. This implies that SMON needs to merge the content of all the online redo logs of each failed instance to determine the recovery set. This is because one failed thread might contain a hole in the redo that needs to be applied to a particular block. So, redo threads of failed instances cannot be applied serially. Also, redo threads of surviving instances are not needed for recovery because SMON could use past or current images of their corresponding buffer caches.
- #20: RAC and Instance/Crash Recovery (continued) 4. Buffer space for recovery is allocated and the resources that were identified in the previous reading of the redo logs are claimed as recovery resources. This is done to avoid other instances to access those resources. 5. All resources required for subsequent processing have been acquired and the GRD is now unfrozen. Any data blocks that are not in recovery can now be accessed. Note that the system is already partially available. Then, assuming that there are past images or current images of blocks to be recovered in other caches in the cluster database, the most recent is the starting point of recovery for these particular blocks. If neither the past image buffers nor the current buffer for a data block is in any of the surviving instances’ caches, then SMON performs a log merge of the failed instances. SMON recovers and writes each block identified in step 3, releasing the recovery resources immediately after block recovery so that more blocks become available as recovery proceeds. After all blocks have been recovered and the recovery resources have been released, the system is again fully available. In summary, the recovered database or the recovered portions of the database becomes available earlier, and before the completion of the entire recovery sequence. This makes the system available sooner and it makes recovery more scalable. Note: The performance overhead of a log merge is proportional to the number of failed instances and to the size of the redo logs for each instance.
- #21: Instance Recovery and Database Availability The graphic illustrates the degree of database availability during each step of Oracle instance recovery: A. Real Application Clusters is running on multiple nodes. B. Node failure is detected. C. The enqueue part of the GRD is reconfigured; resource management is redistributed to the surviving nodes. This operation occurs relatively quickly. D. The cache part of the GRD is reconfigured and SMON reads the redo log of the failed instance to identify the database blocks that it needs to recover. E. SMON issues the GRD requests to obtain all the database blocks it needs for recovery. After the requests are complete, all other blocks are accessible. F. Oracle performs roll forward recovery. Redo logs of the failed threads are applied to the database, and blocks are available right after their recovery is completed. G. Oracle performs rollback recovery. Undo blocks are applied to the database for all uncommitted transactions. H. Instance recovery is complete and all data is accessible. Note: The dashed line represents the blocks identified in step 2 on the previous slide. Also, the dotted steps represent the ones identified on the previous slide.
- #22: Efficient Inter-Node Row-Level Locking Oracle supports efficient row-level locks. These row-level locks are created when data manipulation language (DML) operations, such as UPDATE, are executed by an application. These locks are held until the application commits or rolls back the transaction. Any other application process will be blocked if it requests a lock on the same row. Cache Fusion block transfers operate independently of these user-visible row-level locks. The transfer of data blocks by the GCS is a low level process that can occur without waiting for row-level locks to be released. Blocks may be transferred from one instance to another while row-level locks are held. GCS provides access to data blocks allowing multiple transactions to proceed in parallel.
- #23: Additional Memory Requirement for RAC RAC-specific memory is mostly allocated in the shared pool at SGA creation time. Because blocks may be cached across instances, you must also account for bigger buffer caches. Therefore, when migrating your Oracle database from single instance to RAC, keeping the workload requirements per instance the same as with the single-instance case, then about 10% more buffer cache and 15% more shared pool are needed to run on RAC. These values are heuristics, based on RAC sizing experience. However, these values are mostly upper bounds. If you are using the recommended automatic memory management feature as a starting point, then you can reflect these values in your SGA_TARGET initialization parameter. However, consider that memory requirements per instance are reduced when the same user population is distributed over multiple nodes. Actual resource usage can be monitored by querying the CURRENT_UTILIZATION and MAX_UTILIZATION columns for the GCS and GES entries in the V$RESOURCE_LIMIT view of each instance.
- #24: Parallel Execution with RAC Oracle’s cost-based optimizer incorporates parallel execution considerations as a fundamental component in arriving at optimal execution plans. In a RAC environment, intelligent decisions are made with regard to intra-node and inter-node parallelism. For example, if a particular query requires six query processes to complete the work and six parallel execution slaves are idle on the local node (the node that the user connected to), then the query is processed by using only local resources. This demonstrates efficient intra-node parallelism and eliminates the query coordination overhead across multiple nodes. However, if there are only two parallel execution servers available on the local node, then those two and four of another node are used to process the query. In this manner, both inter-node and intra-node parallelism are used to speed up query operations. In real world decision support applications, queries are not perfectly partitioned across the various query servers. Therefore, some parallel execution servers complete their processing and become idle sooner than others. The Oracle parallel execution technology dynamically detects idle processes and assigns work to these idle processes from the queue tables of the overloaded processes. In this way, Oracle efficiently redistributes the query workload across all processes. Real Application Clusters further extends these efficiencies to clusters by enabling the redistribution of work across all the parallel execution slaves of a cluster.
- #25: Global Dynamic Performance Views Global dynamic performance views store information about all started instances accessing one RAC database. In contrast, standard dynamic performance views store information about the local instance only. For each of the V$ views available, there is a corresponding GV$ view except for a few exceptions. In addition to the V$ information, each GV$ view possesses an additional column named INST_ID. The INST_ID column displays the instance number from which the associated V$ view information is obtained. You can query GV$ views from any started instance. In order to query the GV$ views, the value of the PARALLEL_MAX_SERVERS initialization parameter must be set to at least 1 on each instance. This is because GV$ views use a special form of parallel execution. The parallel execution coordinator is running on the instance that the client connects to, and one slave is allocated in each instance to query the underlying V$ view for that instance. If PARALLEL_MAX_SERVERS is set to 0 on a particular node, then you do not get a result from that node. Also, if all the parallel servers are busy on a particular node, then you do not get a result either. In the two cases above, you do not get a warning or an error message.
- #26: RAC and Services Services are a logical abstraction for managing workloads. Services divide the universe of work executing in the Oracle database into mutually disjoint classes. Each service represents a workload with common attributes, service level thresholds, and priorities. Services are built into the Oracle database providing single system image for workloads, prioritization for workloads, performance measures for real transactions, and alerts and actions when performance goals are violated. These attributes are handled by each instance in the cluster by using metrics, alerts, scheduler job classes, and resource manager. With RAC, services facilitate load balancing, allow for end-to-end lights-out recovery, and provide full location transparency. A service can span one or more instances of an Oracle database in a cluster, and a single instance can support multiple services. The number of instances offering the service is transparent to the application. Services enable the automatic recovery of work. Following outages, the service is recovered fast and automatically at the surviving instances. When instances are later repaired, services that are not running are restored fast and automatically by CRS. Immediately the service changes state, up or down; a notification is available for applications using the service to trigger immediate recovery and load-balancing actions. Listeners are also aware of services availability, and are responsible for distributing the workload on surviving instances when new connections are made. This architecture forms an end-to-end continuous service for applications.
- #27: Virtual IP Addresses and RAC Virtual IP addresses (VIP) are all about availability of applications when an entire node fails. When a node fails, the VIP associated with it automatically fails over to some other node in the cluster. When this occurs: The new node indicates to the world the new MAC address for the VIP. For directly connected clients, this usually causes them to see errors on their connections to the old address. Subsequent packets sent to the VIP go to the new node, which will send error RST packets back to the clients. This results in the clients getting errors immediately. This means that when the client issues SQL to the node that is now down (3), or traverses the address list while connecting (1), rather than waiting on a very long TCP/IP timeout (5), which could be as long as ten minutes, the client receives a TCP reset. In the case of SQL, this results in an ORA-3113 error. In the case of connect, the next address in tnsnames is used (6). The slide shows you the connect case with and without VIP. Without using VIPs, clients connected to a node that died will often wait a 10-minute TCP timeout period before getting an error. As a result, you do not really have a good high-availability solution without using VIPs. Note: After you are in the SQL stack and blocked on read/write requests, you need to use Fast Application Notification (FAN) to receive an interrupt. FAN is discussed in more detail in the “High Availability of Connections” lesson.
- #28: Database Control and RAC With Real Application Clusters 10g, Enterprise Manager (EM) is the recommended management tool for the cluster as well as the database. EM delivers a single-system image of RAC databases, providing consolidated screens for managing and monitoring individual cluster components. The integration with the cluster allows EM to report status and events, offer suggestions, and show configuration information for the storage and the operating system. This information is available from the Cluster page in a summary form. The flexibility of EM allows you to drill down easily on any events or information that you want to explore. For example, you can use EM to administer your entire processing environment, not just the RAC database. EM enables you to manage a RAC database with its instance targets, listener targets, host targets, and a cluster target, as well as the ASM targets if you are using ASM storage for your database. EM has two different management frameworks: Grid Control and Database Control. RAC is supported in both modes. Database Control is configured within the same ORACLE_HOME of your database target and can be used to manage only one database at a time. Alternatively, Grid Control can be used to manage multiple databases, iAS, and other target types in your enterprise across different ORACLE_HOME directories. The diagram shows you the main divisions that can be seen from the various EM pages.