













![خودکار سازی برداری
ها حلقه در
amin@astek% icpc autovec.cc -qopt-report
amin@astek% cat autovec.optrpt
...
LOOP BEGIN at autovec.cc(12,3)
remark #15399: vectorization support: unroll factor
set to 2 [autovec.cc(12,3)] remark #15300: LOOP
WAS VECTORIZED
[autovec.cc(12,3)] LOOP END
...
amin@astek% ./a.out 0 0 0
1 2 1
2 4 2
3 6 3
4 8 4
...
#include <cstdio>
int main(){
const int n=1024;
int A[n] attribute ((aligned(64)));
int B[n] attribute ((aligned(64)));
for (int i = 0; i < n; i++)
A[i] = B[i] = i;
// شود می برداری خودکار صورت به حلقه این
for (int i = 0; i < n; i++)
A[i] = A[i] + B[i];
for (int i = 0; i < n; i++)
printf("%2d %2d %2dn",i,A[i],B[i]);
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17](https://image.slidesharecdn.com/02vectorizationfundamentalsofparallelismandcodeoptimization-www-200426100945/85/02-vectorization-fundamentals_of_parallelism_and_code_optimization-www-astek-ir-16-320.jpg)

![از استفاده برای کد کردن هدفمند
معماری زیر یک
-x[code] to target specific processor architecture
-ax[code] for multi-architecture dispatch
Code Target architecture
MIC-AVX512 Intel Xeon Phi processors (KNL)
CORE-AVX512 Future Intel Xeon processors
CORE-AVX2 Intel Xeon processor E3/E5/E7 v3, v4 family
AVX Intel Xeon processor E3/E5 and E3/E5/E7 v2 family
SSE4.2 Intel Xeon processor 55XX, 56XX, 75XX and E7 family
host architecture on which the code is compiled](https://image.slidesharecdn.com/02vectorizationfundamentalsofparallelismandcodeoptimization-www-200426100945/85/02-vectorization-fundamentals_of_parallelism_and_code_optimization-www-astek-ir-18-320.jpg)
![است ممکن خودکار سازی برداری
باشد پیچیده
for (int i = ii; i < ii + tileSize; i++) { // Auto-vectorized
//مسئله و نیوتن جاذبه قانون N-Body
const float dx = particle.x[j] - particle.x[i]; // x[j] is a const
const float dy = particle.y[j] - particle.y[i]; // x[i] -> vector
const float dz = particle.z[j] - particle.z[i];
const float rr = 1.0f/sqrtf(dx*dx + dy*dy + dz*dz + softening);
const float drPowerN32 = rr*rr*rr;
// Calculate the net force Fx[i-ii] += dx *
drPowerN32; Fy[i-ii] += dy * drPowerN32;
Fz[i-ii] += dz * drPowerN32;
}
1
2
3
4
5
6
7
8
9
10
11
12](https://image.slidesharecdn.com/02vectorizationfundamentalsofparallelismandcodeoptimization-www-200426100945/85/02-vectorization-fundamentals_of_parallelism_and_code_optimization-www-astek-ir-19-320.jpg)


![برای مثالی#pragma omp
simd
const int N=128, T=4;
float A[N*N], B[N*N], C[T*T];
for (int jj = 0; jj < N; jj+=T) // Tile in j
for (int ii = 0 ; ii < N; ii+=T) // and tile in i
#pragma omp simd // Vectorize outer loop
for (int k = 0; k < N; ++k) // long loop, vectorize it
for (int i = 0 ; i < T; i++) { // Loop between ii and ii+T
// Instead of a loop between jj and jj+T, unrolling that loop:
C[0*T + i] += A[(jj+0)*N + k]*B[(ii+i)*N + k];
C[1*T + i] += A[(jj+1)*N + k]*B[(ii+i)*N + k];
C[2*T + i] += A[(jj+2)*N + k]*B[(ii+i)*N + k];
C[3*T + i] += A[(jj+3)*N + k[*B[(ii+i)*N + k];
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14](https://image.slidesharecdn.com/02vectorizationfundamentalsofparallelismandcodeoptimization-www-200426100945/85/02-vectorization-fundamentals_of_parallelism_and_code_optimization-www-astek-ir-22-320.jpg)






![برداری سازی پیاده در آنچه
است درست
▷ True vector dependence – vectorization impossible:
for (int i = 1; i < n; i++)
a[i] += a[i-1]; // dependence on the previous element
for (int i = 0; i < n-1; i++)
a[i] += a[i+1]; // no dependence on the previous element
for (int i = 16; i < n; i++)
a[i] += a[i-16]; // no dependence if vector length <=16
▷ Safe to vectorize:
▷ May be safe to vectorize:](https://image.slidesharecdn.com/02vectorizationfundamentalsofparallelismandcodeoptimization-www-200426100945/85/02-vectorization-fundamentals_of_parallelism_and_code_optimization-www-astek-ir-29-320.jpg)
![وابستگی برای فرضیاتی
بردار به
Not enough information to confirm or rule out vector dependence:
void AmbiguousFunction(int n, int *a, int *b) {
for (int i = 0; i < n; i++)
a[i] = b[i];
}
گزارهSبهTاگر دارد وابستگی:
•اسکالر برنامه یک درTاز قبل
Sشود اجرا
•دوی هرSوTداده یک به
کنند پیدا دسترسی
•ها دسترسی از یکی حداقلWrite
1
2
3
4](https://image.slidesharecdn.com/02vectorizationfundamentalsofparallelismandcodeoptimization-www-200426100945/85/02-vectorization-fundamentals_of_parallelism_and_code_optimization-www-astek-ir-30-320.jpg)
















![استنسیل الگوریتم پایه سازی پیاده
لبه تشخیص در
float *in, *out; // Input and output images
int width, height; // Dimensions of the input image
// Image convolution with the edge detection stencil kernel:
for (int i = 1; i < height-1; i++)
for (int j = 1; j < width-1; j++)
out[i*width + j] =
-in[(i-1)*width + j-1] - in[(i-1)*width + j] - in[(i-1)*width + j+1]
-in[(i)*width + j-1] + 8*in[(i)*width + j] - in[(i)*width + j+1]
-in[(i+1)*width + j-1] - in[(i+1)*width + j] - in[(i+1)*width + j+1]](https://image.slidesharecdn.com/02vectorizationfundamentalsofparallelismandcodeoptimization-www-200426100945/85/02-vectorization-fundamentals_of_parallelism_and_code_optimization-www-astek-ir-47-320.jpg)
![الگوریتم سازی برداری
لبه تشخیص
amin@astek% icpc -c -qopt-report=5 -xMIC-AVX512 stencil.cc
1 for (int i = 1; i < height-1; i++)
2 #pragma omp simd
3 for (int j = 1; j < width-1; j++) out[i*width + j] =
4 -in[(i-1)*width + j-1] - in[(i-1)*width + j] - in[(i-1)*width + j+1]
5 -in[(i)*width + j-1] + 8*in[(i)*width + j] - in[(i)*width + j+1]
6 -in[(i+1)*width + j-1] -in[(i+1)*width + j] - in[(i+1)*width + j+1];](https://image.slidesharecdn.com/02vectorizationfundamentalsofparallelismandcodeoptimization-www-200426100945/85/02-vectorization-fundamentals_of_parallelism_and_code_optimization-www-astek-ir-48-320.jpg)






































02 vectorization fundamentals_of_parallelism_and_code_optimization-www.astek.ir
- 1. درس2-های عملیات برداری Fundamentals of Parallelism & Code Optimization (C/C++,Fortran) در کدها سازی بهینه و سازی موازی مبانی زبانهایC/C++,Fortran Amin Nezarat (Ph.D.) Assistant Professor at Payame Noor University [email protected] www.astek.ir - www.hpclab.ir
- 2. عناوین دوره 1.های پردازنده معماری با آشنایی اینتل 2.Vectorizationمعماری در اینتل کامپایلرهای 3.نویسی برنامه با کار و آشنایی درOpenMP 4.با داده تبادل قواعد و اصول حافظه(Memory Traffic)
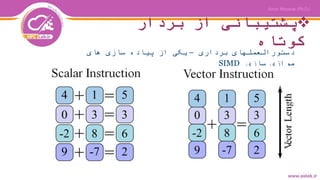
- 4. بردار از پشتیبانی کوتاه برداری دستورالعملهای–های سازی پیاده از یکی سازی موازیSIMD
- 5. ساده مثالی برنامه کارایی افزایش باعث تواند می های حلقه سازی برداری تعداد روی بر زمان یک در را عملیات یک که نحوی به ،شود ها دهد می انجام عنصر زیادی
- 6. Instruction Setsمعماری در اینتل SSE= Streaming SIMD Extensions AVX= Advanced Vector Extensions IMCI=Initial Many Core Instructions
- 7. در سازی برداری سیستمهایSIMD استفادهازمدلSIMDباعثافزایشسرعتمیشود.درمعماری هایمختلفیکهازبرداریسازیپشتیبانیمیکنندهمزمانی وجوددارد.ازجملهاینمعماریهادرIntelمیتوانبهسری هایبعدازSSEودرپردازندههایIBMبهAltivecاشارهکرد. مثالدریکALUمیتوان4مقدارSingle Precisionیا2مقدار Double Precisionرابهصورتبرداریدرهمانزمانیکهیکیک عملیاتاسکالرانجاممی،دهدمحاسبهکند.
- 9. محاسبات کار گردش برداری . . . . . . . . .
- 10. کد سازی برداری:دو رویکرد Automatic Vectorization → مربوطه زبان در سازی پیاده ← Explicit Vectorization ماکرو با سازی پیاده
- 14. خودکار سازی برداری مثال چند–بوسیله Directiveزبان های
- 15. خودکار سازی برداری مثال چند–تغییر حلقه ترتیب در
- 16. خودکار سازی برداری ها حلقه در amin@astek% icpc autovec.cc -qopt-report amin@astek% cat autovec.optrpt ... LOOP BEGIN at autovec.cc(12,3) remark #15399: vectorization support: unroll factor set to 2 [autovec.cc(12,3)] remark #15300: LOOP WAS VECTORIZED [autovec.cc(12,3)] LOOP END ... amin@astek% ./a.out 0 0 0 1 2 1 2 4 2 3 6 3 4 8 4 ... #include <cstdio> int main(){ const int n=1024; int A[n] attribute ((aligned(64))); int B[n] attribute ((aligned(64))); for (int i = 0; i < n; i++) A[i] = B[i] = i; // شود می برداری خودکار صورت به حلقه این for (int i = 0; i < n; i++) A[i] = A[i] + B[i]; for (int i = 0; i < n; i++) printf("%2d %2d %2dn",i,A[i],B[i]); } 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
- 17. برداری در محدودیتهایی سازیخودکار ▷ Innermost loops* ▷ Known number of iterations ▷ No vector dependence ▷ Functions must be SIMD-enabled * #pragma omp simd to override
- 18. از استفاده برای کد کردن هدفمند معماری زیر یک -x[code] to target specific processor architecture -ax[code] for multi-architecture dispatch Code Target architecture MIC-AVX512 Intel Xeon Phi processors (KNL) CORE-AVX512 Future Intel Xeon processors CORE-AVX2 Intel Xeon processor E3/E5/E7 v3, v4 family AVX Intel Xeon processor E3/E5 and E3/E5/E7 v2 family SSE4.2 Intel Xeon processor 55XX, 56XX, 75XX and E7 family host architecture on which the code is compiled
- 19. است ممکن خودکار سازی برداری باشد پیچیده for (int i = ii; i < ii + tileSize; i++) { // Auto-vectorized //مسئله و نیوتن جاذبه قانون N-Body const float dx = particle.x[j] - particle.x[i]; // x[j] is a const const float dy = particle.y[j] - particle.y[i]; // x[i] -> vector const float dz = particle.z[j] - particle.z[i]; const float rr = 1.0f/sqrtf(dx*dx + dy*dy + dz*dz + softening); const float drPowerN32 = rr*rr*rr; // Calculate the net force Fx[i-ii] += dx * drPowerN32; Fy[i-ii] += dy * drPowerN32; Fz[i-ii] += dz * drPowerN32; } 1 2 3 4 5 6 7 8 9 10 11 12
- 21. با بیشتر های حلقه سازی برداری #pragma omp simd Used to “enforce vectorization of loops”, which includes: ▷ Loops with SIMD-enabled functions ▷ Second innermost loops ▷ Failed vectorization due to compiler decision ▷ Where guidance is required (vector length, reduction, etc.) See OpenMP reference for syntax; #pragma simd
- 22. برای مثالی#pragma omp simd const int N=128, T=4; float A[N*N], B[N*N], C[T*T]; for (int jj = 0; jj < N; jj+=T) // Tile in j for (int ii = 0 ; ii < N; ii+=T) // and tile in i #pragma omp simd // Vectorize outer loop for (int k = 0; k < N; ++k) // long loop, vectorize it for (int i = 0 ; i < T; i++) { // Loop between ii and ii+T // Instead of a loop between jj and jj+T, unrolling that loop: C[0*T + i] += A[(jj+0)*N + k]*B[(ii+i)*N + k]; C[1*T + i] += A[(jj+1)*N + k]*B[(ii+i)*N + k]; C[2*T + i] += A[(jj+2)*N + k]*B[(ii+i)*N + k]; C[3*T + i] += A[(jj+3)*N + k[*B[(ii+i)*N + k]; } 1 2 3 4 5 6 7 8 9 10 11 12 13 14
- 24. ماکروها از استفاده با سازی برداری- روشIntrinsicsاینتل معماری در
- 25. ماکروها از استفاده با سازی برداری-روشIntrinsics معماری درIBM
- 27. قابلیت که توابعی SIMDدارند Define function in one file (e.g., library), use in another
- 28. قابلیت با توابعSIMDمی باشند پیچیده تواند #pragma omp declare simd float MyErfElemental(const float inx){ const float x = fabsf(inx); // Absolute value (in each vector lane) const float p = 0.3275911f; // Constant parameter across vector lanes const float t = 1.0f/(1.0f+p*x); // Expression in each vector lanes const float l2e = 1.442695040f; // log2f(expf(1.0f)) const float e = exp2f(-x*x*l2e); // Transcendental in each vector lane float res = -1.453152027f + 1.061405429f*t; // Computing a polynomial res = 1.421413741f + t*res; res =-0.284496736f + t*res; res = 0.254829592f + t*res; res *= e; res = 1.0f - t*res; // Analytic approximation in each vector lane return copysignf(res, inx); // Copy sign in each vector lane } 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
- 29. برداری سازی پیاده در آنچه است درست ▷ True vector dependence – vectorization impossible: for (int i = 1; i < n; i++) a[i] += a[i-1]; // dependence on the previous element for (int i = 0; i < n-1; i++) a[i] += a[i+1]; // no dependence on the previous element for (int i = 16; i < n; i++) a[i] += a[i-16]; // no dependence if vector length <=16 ▷ Safe to vectorize: ▷ May be safe to vectorize:
- 30. وابستگی برای فرضیاتی بردار به Not enough information to confirm or rule out vector dependence: void AmbiguousFunction(int n, int *a, int *b) { for (int i = 0; i < n; i++) a[i] = b[i]; } گزارهSبهTاگر دارد وابستگی: •اسکالر برنامه یک درTاز قبل Sشود اجرا •دوی هرSوTداده یک به کنند پیدا دسترسی •ها دسترسی از یکی حداقلWrite 1 2 3 4
- 31. داده وابستگی ها کرد فرض زیر صورت به توان می را ممکن های وابستگی انواع وابستگی شناور(درست وابستگی) وابسته غیر خروجی به وابستگی
- 32. حلقه در ها داده وابستگی–بررسی سناریو چند(1) حلقه در وابستگی غیر کنیم می گسترده را حلقه ،وابستگی بررسی برای
- 33. حلقه در ها داده وابستگی–چند بررسی سناریو(2) وابستگی دارای حلقه مستقل وابستگی دارای حلقه
- 34. و ای داده های وابستگی سازی برداری •برای مناسبی راهنمای تواند می ای داده وابستگی باشد سازی برداری •به گرافی وابستگی دارای که حلقه درون گزاره یک شود برداری تواند می نباشد خود
- 35. و ای داده های وابستگی سازی برداری خود به گرافی وابستگی وجود زمان در(Cycle)سازی برداری است امکانپذیر زیر روشهای از یکی با: •شود خارج سایکل از که نحوی به گزاره کردن توزیع •وابستگی حذف •Freezeجلقه کردن •الگوریتم تغییر
- 37. وابستگی حذف
- 39. تغییر الگوریتم رخدادها باز شناسایی برای کامپایلر(Cycle)سری یک از را حلقه موازی نسخه و کرده استفاده الگوها کنند می قبلی نسخه جایگزین است رخدادها باز از مثالهایی زیر موارد:
- 40. Multiversioned amin@astek% icpc -c code.cc -qopt-report amin@astek% cat code.optrpt ... LOOP BEGIN at code.cc(4,1) <Multiversioned v1> remark #25228: LOOP WAS VECTORIZED LOOP END ... LOOP BEGIN at code.cc(4,1) <Multiversioned v2> remark #15304: loop was not vectorized: non-vectorizable loop instance .. LOOP END Pointers checked for aliasing runtime to choose code path.
- 41. Multiversioned Prevent multiversioning or allow vectorization with a directive: #pragma ivdep for (int i = 0; i < n; i++) // ... amin@astek% icpc -c code.cc -qopt-report -qopt-report-phase:vec amin@astek% cat vdep.optrpt ... LOOP BEGIN at code.cc(4,1) remark #25228: LOOP WAS VECTORIZED LOOP END ... Alternative: keyword restrict – more fine-grained, weaker.
- 42. Strip-Mining
- 43. Strip-Minigبرداری برای سازی ▷به را حلقه یک که نویسی برنامه تکنیکهای کند می تبدیل تودرتو حلقه دو ▷برداری برای را بیشتری فرصتهای تکنیک این کند می فراهم سازی ▷اندازهStripمعادل بایدRegisterباشد سیستمOriginal: Strip-mined: for (int i = 0; i < n; i++ ){ // ... do work } const int STRIP=1024; const int nPrime = n - n%STRIP; for (int ii=0; ii<nPrime; ii+=STRIP( for (int i=ii; i<ii+STRIP; i++ ) // ... do work for (int i=nPrime; i<n; i++) // ... do work
- 45. Stencil Operators ▷ Linear systems of equations ▷ Partial differential equations Fluid dynamics, heat transfer, image processing (convolution matrix), cellular automata.
- 46. لبه تشخیص
- 47. استنسیل الگوریتم پایه سازی پیاده لبه تشخیص در float *in, *out; // Input and output images int width, height; // Dimensions of the input image // Image convolution with the edge detection stencil kernel: for (int i = 1; i < height-1; i++) for (int j = 1; j < width-1; j++) out[i*width + j] = -in[(i-1)*width + j-1] - in[(i-1)*width + j] - in[(i-1)*width + j+1] -in[(i)*width + j-1] + 8*in[(i)*width + j] - in[(i)*width + j+1] -in[(i+1)*width + j-1] - in[(i+1)*width + j] - in[(i+1)*width + j+1]
- 48. الگوریتم سازی برداری لبه تشخیص amin@astek% icpc -c -qopt-report=5 -xMIC-AVX512 stencil.cc 1 for (int i = 1; i < height-1; i++) 2 #pragma omp simd 3 for (int j = 1; j < width-1; j++) out[i*width + j] = 4 -in[(i-1)*width + j-1] - in[(i-1)*width + j] - in[(i-1)*width + j+1] 5 -in[(i)*width + j-1] + 8*in[(i)*width + j] - in[(i)*width + j+1] 6 -in[(i+1)*width + j-1] -in[(i+1)*width + j] - in[(i+1)*width + j+1];
- 49. کارایی
- 52. سازی پیاده اسکالر double BlackBoxFunction(double x); ... const double dx = a/(double)n; double integral = 0.0; for (int i = 0; i < n; i++){ const double xip12 = dx*((double)i +0.5); const double dI = BlackBoxFunction(xip12)*dx; integral += dI; }
- 53. سازی پیاده برداری 1 #pragma omp declare simd 2 double BlackBoxFunction(double x); 3 ... 4 const double dx = a/(double)n; 5 double integral = 0.0; 7 #pragma omp simd reduction(+: integral) 8 for (int i = 0; i < n; i++) { 9 const double xip12 = dx*((double)i + 0.5); 10 const double dI = BlackBoxFunction(xip12)*dx; 11 integral += dI; 12 }
- 54. کارایی
- 55. حلقه تبدیل
- 56. تبدیل روشهای انواع حلقه باشند می زیر شرح به حلقه تبدیل روشهای انواع: • Compiler Directives • Loop Distribution or loop fission • Reordering Statements • Node Splitting • Scalar expansion • Loop Peeling • Loop Fusion • Loop Unrolling • Loop Interchanging
- 57. دایرکتیوهای کامپایلر عملیات خودکار صورت به توانند نمی کامپایلرها که زمانی از استفاده با توان می کنند گیری تصمیم را سازی برداری عمل انجام به مجبور را کامپایلر ،دایرکتیوها سری یک کرد سازی برداری •که زمانی در تواند می حلقه اینK<-3وK>=0 شود برداری است •که داند می نویس برنامهk>=0است •افزودن با#pragma ivdepمی کامپایلر به های وابستگی از تواند می که گوییم کند صرفنظر ناشناخته در اینتل در IBM
- 59. Node Splitting
- 63. Reductions Reductionیک از عناصری بر که جمع همانند است عملیات یک شود می استفاده تجمیعی نتایج تولید منظور به آرایه. مثال دو:
- 64. متغیرهای استقرایی یک نقش در تواند می که است متغیری استقرایی متغیر شود نمایان حلقه تکرار متغیرهای از تابع اما کنند می کار یک کد تکه دو این...
- 65. Data Alignment می حافظه در آدرس و مقدار خصوصیت دو دارای داده هر در داده یک آدرس که است مفهوم بدین داده ترازبندی ،باشد اعداد بر پردازنده آن معماری مدل به توجه با حافظه 1،2،4،8،16،32،64است پذیر تقسیم.داده یک آدرس اگر مثال حافظه در1244098ترازبندی بر مبتنی داده یعنی باشد4 به پردازنده ارجاع بار هر در که معنی بدین ،است بایتی حافظه4شود می خوانده یکجا صورت به بایت.
- 66. Data Alignment معماری درSSEتا های داده اینتل128است تعریف قابل بیت که معنی بدین8داده16بایتیSingle Precisionیا4داده32 بایتیDouble Precision •ترازبندی یک زیر مثال16تعریف این ،دهد می نشان را دستی بایتی ترتیب با پایه آدرس که است معنی بدین16رود می جلو تایی •آرایه سه هر هم مثال این درa,b,cترازبندی با 16کنند می حرکت حافظه در بایتی
- 67. Data Alignmentداده نوع در Struct •های آرایهA,Bمبنای بر16اند نشده ترازبندی بایتی
- 68. Data Alignmentداده نوع در Struct •گفت کامپایلر به توان می کد به ترازبندی صفت افزودن با شود انجام مبنایی چه بر ترازبندی که
- 69. Aliasing حلقه تواند می کامپایلر آیا کند؟ می برداری را زیر •aوbهستند یکدیگر مستعار •وابستگی یکSelf-Trueافتاده اتفاق است •و غیرمجاز حلقه این سازی برداری است پرهزینه
- 70. Aliasing •برایبرداری،سازیکامپایلربایداطمینانیابدکهبرروی پوینترهاaliasingاتفاقنمیافتد •اگرکامپایلرنداندکهدوپوینترaliasمیشوندوکدرا برداریکندهزینهچککردنبسیارزیادومعادلخواهد شدکهnتعدادپوینترهاست •اگرتعدادپوینترهادرکدزیادباشندکامپایلرممکناست تصمیمبگیردکهبرداریسازیراانجامندهد زمان کنترلهای از جلوگیری برای حل راه دو دارد وجود اجرا 1-های آرایهStaticوGlobal 2-از استفاده__restrict__ attribute
- 73. عنوان راهکار اگر__restrict__بعدی دو های آرایه سازی برداری روشهای از ،نکرد فعال را کنید استفاده زیر: 1-های آرایه تعریفStatic or Global 2-از استفاده و ارایه کردن خطی__restrict__ 3-از استفادهdirectiveکامپایلر های
- 74. Non-Unit Stride از ای آرایه که کنید فرضStructداریم کنیم می تعریف معمولی آرایه صورت به را آن حال
- 75. از دیگر مثالیNon- Unit Stride
- 76. های گزاره شرطی دایرکتیو شرط حاوی های حلقه#pragma vector alwaysدارند نیاز را •برداری آیا که داند نمی کامپایلر که آنجا از خیر یا بود خواهد سودمند سازی •کند ممانعت استثنا حالت یک از است ممکن شرط •،حال این در حلقه سازی برداری صورت در کند می حذف را شرط کامپایلر
- 77. های گزاره شرطی حلقه از شرط حذف
- 78. سایرDirectiveهای کامپایلر خودکار صورت به را ها حلقه از بسیاری کامپایلر تواند نمی نیز را تعدادی اما کند می برداری از توان می منظور همین به ،کند گیری تصمیمdirective کرد استفاده ها
- 80. چه سازی برداری از بعد کنیم کار برداریسازیعملیاتهایریاضیکمهزینه ،استامادسترسیبهحافظهخیلیپر هزینهاست. ا،نکنید بهینه را کش از استفاده شما گر بود خواهد فایده کم نیز سازی برداری. به دسترسی نام به ای مسئله با شما بود خواهید طرف حافظه.
- 83. گیری اندازه اجرا زمان کن اضافه اجرا زمان افزایش برای خارجی حلقه یک را خارجی تابع یک اضافه حلقه درون از تمرکز که کنید خارج حلقهشود
- 84. چگونه کنیم کامپایل icpc yourcode.cc -o youroutput.out -qopt-report=n -xCORE-AVX2 nرا خروجی گزارش سطح که است عددی دهد می نشان: 0گزارش بدون 1شده برداری حلقه خط شماره صرفا دهد می را 2تا5از را بیشتری جزئیات دهد می سازی برداری فرایند با همنام گزارشی کامپایل از پس پسوند و کد فایلoptrptمی ساخته شود •کدهای کامپایل برایc++کامپایلر درgnu g++ -O2 -ftree-vectorize -ftree-vectorizer-verbose=n –msse4 -S -c yourcode.cpp کنید کلیک بیشتر راهنمایی برای معمار ی code Targetarchitecture MIC-AVX512 Intel Xeon Phi processors (KNL) CORE-AVX512 Future Intel Xeonprocessors CORE-AVX2 Intel Xeon processor E3/E5/E7 v3, v4family AVX Intel Xeon processor E3/E5 and E3/E5/E7 v2family SSE4.2 Intel Xeon processor 55XX, 56XX,75XX and E7family host architecture on which the code is compiled
- 85. ضرب مثال ها ماتریس •یافت بهبود کد این مرحله دو طی 1-افزودنDirectiveکد به 2-Loop Interchange