



































2019 dynamically composing_domain-data_selection_with_clean-data_selection_by_co-curricular_learning_for_neural_machine_translation
- 1. Introducer: Hiroki Homma, in Komachi’s lab. November 25th, 2019 ACL 2019
- 2. Abstract 1/2 • Noise and domain are important aspects of data quality for NMT. • Existing research focus separately on domain-data selection, clean-data selection, or their static combination. → ✘ Dynamic interaction • This paper introduces a “co-curricular learning” method. • compose dynamic domain-data selection with dynamic clean-data selection, for transfer learning across both capabilities
- 3. Abstract 2/2 • We apply an EM-style optimization procedure to further refine the “co-curriculum.” • Experiment results and analysis with two domains demonstrate the effectiveness of the method and the properties of data scheduled by the co- curriculum.
- 4. Introduction 1/4 • NMT has found successful use cases in, domain translation and helping other NLP applications. • Given a source monolingual corpus, how to use it to improve an NMT model to translate same-domain sentences well? Data selection plays an important role.
- 5. Introduction 2/4 • Data selection has been a fundamental research topic. • use language models to select parallel data → ✘ performs poorly on noisy data, such as large-scale, web-crawled datasets • NMT community has realized the harm of data noise to translation quality. • denoising methods (Koehn et al., 2018), clean-data selection → ✘ they require trusted parallel data
- 6. Introduction 3/4 clean-data selection domain-data selection
- 7. Introduction 4/4 • We introduce a method to dynamically combine clean-data selection and domain-data selection. • We treat them as independent curricula and compose them into a “co-curriculum.”
- 8. Contributions 1. “Co-curricular learning”, for transfer learning across data quality. 2. A curriculum optimization procedure to refine the co-curriculum. 3. We wish our work contributed towards better understanding of data, such as noise, domain, or “easy to learn”, and its interaction with NMT network. It extends the single curriculum learning work in NMT and makes the existing domain-data selection method work better with noisy data. While gaining some improvement with deep models, it surprisingly improves shallow model by 8-10 BLEU points – We find that bootstrapping seems to “regularize” the curriculum and make it easier for a small model to learn on.
- 9. Related Work 1/5 • Measuring Domain and Noise in Data • Moore and Lewis, 2010 • van der Wees et al., 2017 Axelrod et al,. 2011 • Junczys-Dowmunt, 2018 Wang et al,. 2018 cross entropy difference select domain sentences measure the noise level in sentence pair NMT model trusted data 𝑥 : source sentence ሚ𝜗 : general-domain LM መ𝜗 : in-domain LM (𝑥, 𝑦) : sentence pair ሚ𝜗 : baseline NMT መ𝜗 : trained on noisy data and cleaner NMT
- 10. Related Work 2/5 • Curriculum Learning for NMT • Bengio et al., 2009 Curriculum learning (CL) traditional static selection curriculum training criterion 𝑥, 𝑦 : training examples 𝐷 : dataset 𝑊𝑡 𝑥, 𝑦 : weights 𝑃 𝑥, 𝑦 : training distribution 𝑚 𝑓 : final task of interest tasks There has already been rich research in CL for NMT
- 11. Related Work 3/5 Curriculum learning (CL) Fine-tuning a base line on in-domain parallel data is good strategy domain curriculum There has already been rich research in CL for NMT noise level denoising curriculum linguistically- motivated features classify examples into bins for scheduling reinforcement learning observe faster training convergence adapt generic NMT models to specific domain CL framework simplify speed up training • Thompson et al., 2018 Sajjad et al., 2017 Freitag and Al-Onaizan, 2016 • van der Wees et al., 2017 • Wang et al., 2018 • Kocmi and Bojar, 2017 • Kumar et al., 2019 • Zhang et al., 2018 • Zhang et al., 2019 • Platanios et al., 2019
- 12. Related Work 4/5 therefore CL is a natural formulation for dynamic online data selection.
- 13. Related Work 5/5 • Our work is built on two types of data selection • Dynamic domain-data selection Uses the neural LM (NLM) based scoring function • Dynamic clean-data selection Uses the NMT-based scoring function • Ideally, we would have in-domain, trusted parallel data to design a true curriculum, 𝐶true domain curriculum 𝐶domain denoising curriculum 𝐶denoise reprint reprint true curriculum, 𝐶true
- 14. More Related Work • Junczys-Dowmunt (2018) : combine (static) features for data filtering • Mansour et al. (2011) : combine an n-gram LM and IBM translation Model 1 for domain data filtering • We compose different types of dynamic online selection rather than combining static features. • Back translation (BT) is another important approach to using monolingual data for NMT • Sennrich et al., 2016 • We use monolingual data to seed data selection, rather than generating parallel data directly from it.
- 15. Problem Setting 1/2 a background parallel dataset between languages 𝑋 and 𝑌 large 100M diverse noisy an in-domain monolingual corpus in source language 𝑋 middle 1K~1M testing domain small, trusted, out-of-domain (OD) parallel dataset small ~1K out-of- domain trusted reprint reprinttrain 𝜙 to sort data by noise level into a denoising curriculum train 𝜑 to sort data by domain relevance into a domain curriculum
- 16. Problem Setting 2/2 • The setup, however, assumes that does not exist • Our goal is to use an easily available monolingual corpus and recycle existing trusted parallel data to reduce the cost of curating in-domain parallel data. • composed curriculum : • We hope in-domain, trusted parallel data testing domain trusted
- 17. Co-Curricular Learning The idea with a toy dataset of three examples travel domain travel domain noisy medicine domain well- translated domain curriculum 𝐶domain denoising curriculum 𝐶denoise Co-curriculum
- 18. Curriculum Mini-Batching to return the top 𝜆 𝑡 of examples in dataset 𝐷 sorted by a scoring function 𝜙 at a training step 𝑡. pace function Dynamic data selection function This is inspired by the exponential learning rate schedule We introduce two different co-curricula • Mixed Co-Curriculum (𝐶co mix) • Cascaded Co-Curriculum (𝐶co cascade)
- 19. Mixed Co-Curriculum (𝐶co mix ) • simply adds up the domain scoring function and the denoising function • for a sentence pair (𝑥, 𝑦), values of 𝜑 and 𝜙 may not be on the same scale or even from the same family of distributions 𝐶co mix may not be able to enforce either curriculum sufficiently ・assign non-zero weights ・use uniform sampling
- 20. Cascaded Co-Curriculum (𝐶co cascade ) • defines two selection functions and nests them data-discarding paces for clean-data selection data-discarding paces for domain-data selection
- 21. Curriculum Optimization curriculum generation process iteratively updated iteratively updated iteratively updated trustedleargein-domain
- 22. Experiments
- 23. Setup 1/4 • We consider two background datasets and two test domains • four experiment configurations • a background dataset (adapted sentence-piece model, shared 32k sub-words) En→Fr Paracrawl 300 M pairs En→Fr WMT14 train 40 M pairs noisier En→Fr IWSLT15: spoken language domain En→Fr WMT14 test: news domain 220 K English side validation: 28 M English side En→Fr IWSLT15 En→Fr WMT14 test En→Fr WMT14 test WMT 2012-2013 IWSLT15 220 K pairs IWSLT15 WMT 2010-2011 test WMT14 WMT 2010-2011 test validation:
- 24. Setup 2/4 • RNN-based NMT (Wu et al., 2016) to train models • Model parameterization for 𝜃’s of 𝜑 or 𝜗’s 𝜙 is 512 dimensions by 3 layers • NLMs are realized using NMT models with dummy source sentences (Sennrich et al., 2016) • Deep models are 1024 dimensions by 8 layers • Unless specified, results are reported for deep models. • truecased, detokenized BLEU with mteval-v14.pl
- 25. Setup 3/4 • Training on Paracrawl • Adam in warmup • SGD for a total of 3 million steps • batch size 128 • learning rate 0.5Training on Paracrawl annealed, at step 2 million, down to 0.05 • no dropout (due to its large data volume) • Training on WMT 2014 • batch size 96 • dropout probability 0.2 for a total of 2 million steps • learning rate 0.5 annealed, at step 1.2 million, down to 0.05
- 26. Setup 4/4 • Pace hyper-parameters • 𝐻 = 𝐹 = 400𝑘 • 𝐺 = 900𝑘 • Floor values • 𝜆, 𝛽, 𝛾 are top 0.1, 0.2, 0.5 selection ratios • 0.1 = 0.2 × 0.5 empirically All single curriculum experiments use the same pace setting as 𝐶mix
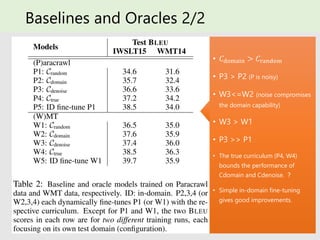
- 27. Baselines and Oracles 1/2 Baselines: 1. 𝐶random : Baseline model trained on background data with random data sampling. 2. 𝐶domain : Dynamically fine-tunes 𝐶random with a domain curriculum (van dar Wees et al., 2017) 3. 𝐶domain : Dynamically fine-tunes 𝐶random with a denoising curriculum (Wang et al., 2018) Oracles: 4. 𝐶true : Dynamically fine-tunes 𝐶random with the true curriculum 5. ID fine-tune 𝐶random : Simply fine-tunes 𝐶random with in-domain (ID) parallel data All single In most experiments, we fine-tune a warmed-up (baseline) model to compare curricula, for quicker experiment cycles
- 28. Baselines and Oracles 2/2 • 𝐶domain > 𝐶random • P3 > P2 (P is noisy) • W3<=W2 (noise compromises the domain capability) • W3 > W1 • P3 >> P1 • The true curriculum (P4, W4) bounds the performance of Cdomain and Cdenoise. ? • Simple in-domain fine-tuning gives good improvements.
- 29. Co-Curricular Learning Per-step cascading works better than mixing. so we use 𝐶co cascade for the remaining experiments Co-curriculum improves either constituent curriculum (P2 or P3) and no CL, can be close to the true curriculum on noisy data. On the cleaner WMT training data, co-curriculum (W7) improves either constituent curricula (W2 and W3) by smaller gains than Paracrawl.
- 30. Effect of Curriculum Optimization 1/5 Shallow models reprint 512 dimensions × 3 layers Surprisingly, EM-3 improves baseline by +10 BLEU on IWSLT15, +8.2 BLEU on WMT14
- 31. Effect of Curriculum Optimization 2/5 Deep models reprint 1024 dimensions × 8 layers EM-style optimization further improves domain curriculum. But, overall, it has a small impact on deep models.
- 32. Effect of Curriculum Optimization 3/5 Why the difference? – Per-word Loss Curriculum learning and optimization push “easier-to-learn” (lower per-word loss) examples to late curriculum (right) and harder examples (higher per-word loss) to early curriculum (left).
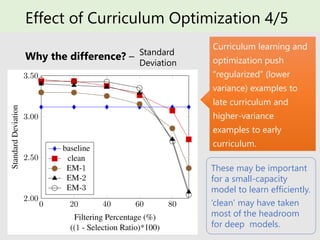
- 33. Effect of Curriculum Optimization 4/5 Why the difference? – Curriculum learning and optimization push “regularized” (lower variance) examples to late curriculum and higher-variance examples to early curriculum. Standard Deviation These may be important for a small-capacity model to learn efficiently. ‘clean’ may have taken most of the headroom for deep models.
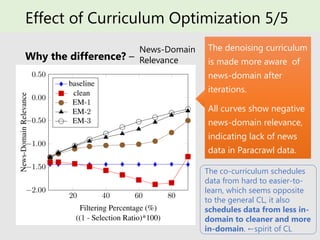
- 34. Effect of Curriculum Optimization 5/5 Why the difference? – The denoising curriculum is made more aware of news-domain after iterations. All curves show negative news-domain relevance, indicating lack of news data in Paracrawl data. The co-curriculum schedules data from hard to easier-to- learn, which seems opposite to the general CL, it also schedules data from less in- domain to cleaner and more in-domain. ←spirit of CL News-Domain Relevance
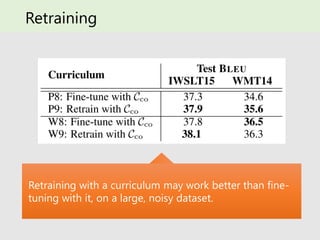
- 35. Retraining Retraining with a curriculum may work better than fine- tuning with it, on a large, noisy dataset.
- 36. Dynamic vs. Static Data Selection • How does being dynamic matter? • What if we retrain on the static data, too? Curriculum learning works slightly better than finetuning a warmed-up model with a top static selection. Curriculum learning works better than retraining with a static, top selection, especially when the training dataset is small.
- 37. Discussion 1/3 • Evidence of data-quality transfer. Curriculum learning in one domain may enable curriculum learning in another.
- 38. Discussion 2/3 • Regularizing data without a teacher. • Section “Effect of Curriculum Optimization” shows that • the denoising scoring function and its bootstrapped versions tend to regularize the late curriculum and make the scheduled data easier for small models to learn on. • One potential further application of this data property may be in learning a multitask curriculum where regular data may be helpful for multiple task distributions to work together in the same model. • We could regularize data by example selection, without a teacher. future work
- 39. Discussion 3/3 • Pace function hyper-parameters. • Data-discarding pace functions seem to work best when they simultaneously decay down to their respective floors. • Adaptively adjusting them future work
- 40. Conclusion • We present a co-curricular learning method to make domain- data selection work better on noisy data, by dynamically composing it with clean-data selection. • We show that the method improves over either constituent selection and their static combination. • We further refine the co-curriculum with an EM-style optimization procedure and show its effectiveness, in on small- capacity models. • In future, we would like to extend the method to handle more than two curricula objectives.