[2B5]nBase-ARC Redis Cluster
18 likes4,528 views

DEVIEW 2014 [2B5]nBase-ARC Redis Cluster
![[2B5]nBase-ARC Redis Cluster](https://image.slidesharecdn.com/2b5nbase-arcrediscluster-140930003743-phpapp02/85/2B5-nBase-ARC-Redis-Cluster-1-320.jpg)































[2B5]nBase-ARC Redis Cluster
- 2. 이규재 수석연구원 / NAVER LABS nBase-ARC: Redis Cluster
- 3. 1. nBase-ARC 소개 2. 오픈 소스 제품과 비교 3. 발전 방향 CONTENTS
- 5. Scale-out 클러스터 비용 효율성 서비스 연속성 확장/축소 일반 컴퓨터를 이용해 시스템 구축 작게 시작해서 크게 성공할 수 있어야 … 운영 작업이 서비스에 영향을 주어선 안됨 인터넷 스케일 서비스에 필요한 분산 저장 시스템
- 6. nBase-ARC는 Autonomous Redis Cluster nBase- Labs에서 만드는 Scale-out 클러스터 시리즈 운영자의 개입 없이 동작하는 (장애 탐지, 장애 처리) 고속의 In-Memory 연산이 가능한 Scale-out 클러스터
- 7. 탄생 배경 (1/2) In-memory 기반의 고성능, 고가용 scale-out 클러스터 DB가 필요해짐 •세션 저장소로 디스크 기반의 클러스터를 사용 •많은 쓰기 부하를 일정한 응답 속도로 처리해야 하는 요구사항 •비용 효율적으로 해결 해야 됨 •Caching이 도움이 되질 않음
- 8. 탄생 배경 (2/2) •Simple •Fast •Persistent •Available 정부 과제: 페타바이트급 대용량 이기종 클러스터드 DBMS SW 개발 복제 Configuration Master
- 9. Required Features 장애 처리 •장애를 감지해 자동으로 fail-over 해야 한다 Scale-out •장비를 투입해 rebalancing 할 수 있다 API •기존 Redis 클라이언트를 그대로 사용 분산 방식 •여러 장비에 데이터를 나누어 처리해야 한다 가용성 •데이터 durability, 서비스 availability •장애, 운영 작업 등에 의해 서비스가 영향을 받지 않아야 한다 서비스 연속성
- 10. 분산 방식 0 1 2 8191 PG 0 PG 1 PG N PGS 1 PGS 2 PGS 3 PGS 4 PGS 5 CRC16(key) % 8192 복제 그룹 Partition Group Partition Number Key에 대한 hash 값을 기반으로 하는 분할 방식 채택
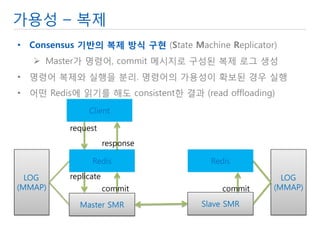
- 11. 가용성 – Redis 복제 •Redis 복제는 비 동기 복제로 master 장애 발생하면 데이터 유실 •Slave에 읽기를 하면 이전 데이터를 읽을 수 있음 •복제 동기화는 sync 방식과 (RDB + replication buffer), psync (일시적 단절 대비 버퍼 유지) 방식을 지원 설정이 어려움 Client Master Slave request response request 복제를 통해 서비스 및 데이터 가용성 확보. 하지만 Redis 복제는 문제
- 12. 가용성 – 복제 •Consensus 기반의 복제 방식 구현 (State Machine Replicator) Master가 명령어, commit 메시지로 구성된 복제 로그 생성 •명령어 복제와 실행을 분리. 명령어의 가용성이 확보된 경우 실행 •어떤 Redis에 읽기를 해도 consistent한 결과 (read offloading) Client Redis Redis request response Master SMR Slave SMR replicate commit commit LOG (MMAP) LOG (MMAP)
- 13. 가용성 – 복제 (계속) •명령어의 가용성은 실행되기 전에 저장되는 로그의 개수로 보장됨 예를 들어 2인 경우, 두 장비의 로그에 저장된 이후에 실행 속도를 위해 로그 파일에 대한 연산은 OS buffer 까지 쓰고 리턴 로그 파일은 1초 (또는 10M) 주기로 디스크로 sync 됨
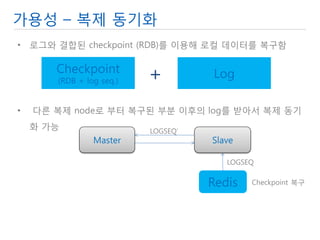
- 14. 가용성 – 복제 동기화 •로그와 결합된 checkpoint (RDB)를 이용해 로컬 데이터를 복구함 Checkpoint (RDB + log seq.) Log + • 다른 복제 node로 부터 복구된 부분 이후의 log를 받아서 복제 동기화 가능 Master Slave Redis Checkpoint 복구 LOGSEQ LOGSEQ’
- 15. 장애 처리 – Failure detection Failure Detection Fail over + •Heartbeat module(HB)이 응용 레벨 (L7) ping 메시지 전송 •다수의 HB 운영 •대상 상태에 대한 결정은 Zookeeper 사용 대상의 상태 z-node 대상의 상태에 대한 의견 z-node 하위의 ephemeral z-node
- 16. 장애 처리 – Fail over Failure Detection Fail over + •Cluster controller에 의해 수행 복수의 instance를 두며, 장애 시 leader election을 통해 새로운 cluster controller가 동작 •감시 대상 z-node를 watch •상태 변경 발생시 (child event) 클러스터의 상태를 결정하고 fail- over 작업 진행
- 17. Scale-out •Migration에 의한 데이터 처리 부분 이동 Dump Load Log catchup 2PC
- 18. API •기존 Redis 클라이언트를 그대로 사용할 수 있어야 한다 Gateway
- 19. 서비스 연속성 •장비 추가, 제거, scale-out, 소프트웨어 업그레이드 복제 추가, 제거, migration으로 해결됨 •Gateway 업그레이드, 추가 삭제? Gateway에 대한 L4 스위치 구성? Gateway lookup 서비스
- 20. nBase-ARC 구조 HB HB HB Cluster Controller Leader Follower Follower Configuration Master Cluster Gateway Gateway 복제 Zookeeper Ensemble Redis Redis Zone
- 21. 2. 오픈 소스 제품과 비교
- 22. Redis Cluster Redis 개발자가 만들고 있는 제품과의 차이점에 대해 설명 ARC: nBase-ARC RC: Redis Cluster
- 23. 정리 RC ARC 키 분산 동일 복제 Asynchronous Consensus Node 복구 RDB or AOF RDB + LOG 클라이언트 연결 REDIS Gateway Migration Key 단위 Key 영역 단위 Fault detection Node간의 gossip 복수의 HB CAP 측면 CP •RC: 고성능+, 장애/단절 발생 시 데이터 유실 •ARC: 고성능, DB
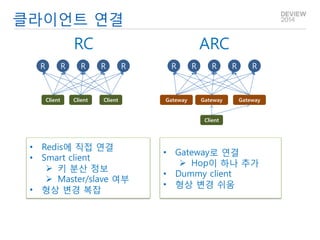
- 24. 클라이언트 연결 R R R R R Gateway Gateway Gateway R R R R R Client Client Client Client RC ARC •Redis에 직접 연결 •Smart client 키 분산 정보 Master/slave 여부 •형상 변경 복잡 •Gateway로 연결 Hop이 하나 추가 •Dummy client •형상 변경 쉬움
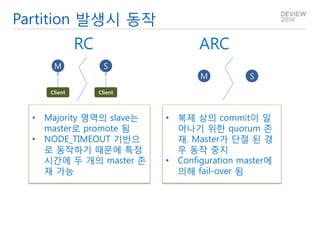
- 25. Partition 발생시 동작 RC ARC •Majority 영역의 slave는 master로 promote 됨 •NODE_TIMEOUT 기반으로 동작하기 때문에 특정 시간에 두 개의 master 존재 가능 •복제 상의 commit이 일어나기 위한 quorum 존재. Master가 단절 된 경우 동작 중지 •Configuration master에 의해 fail-over 됨 M S M S Client Client
- 26. Migration RC ARC MIGRATING SLOT IMPORTING SLOT SOURCE SLOT TARGET SLOT Dump Load Log Catch-up 2PC WHILE true IF GETKEYSINSLOT MIGRATE key ELSE break •Key 단위로 수행 •느림 •Slot 영역 단위로 수행 •빠름
- 27. CAP Perspective A •Partition이 발생하지 않도록 소프트웨어를 만들 수 없음 •CP 분할 발생시 consistency 유지 •AP 분할 발생시 availability 유지 이후 merge 해야 함 C P RC ARC •Not AP Major partition만 살아 남음 •Not CP Write 에 대한 consensus가 없음 •CP
- 28. 성능 •ARC는 latency가 더 크다 Gateway에 의한 hop 복제 layer •ARC의 경우 CPU를 더 사용한다 Gateway Replicator •성능상의 병목은 네트워크에서 생김 네트워크로 전송되는 데이터의 양 네트워크로 전송되는 packet의 개수 (interrupt 처리 능력) RPS (Receive Packet Steering)/RFS (Receive Flow Steering)등의 네트워크 최적화 설정이 필요함
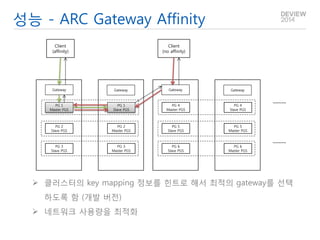
- 29. 성능 - ARC Gateway Affinity PG 1 Master PGS PG 2 Slave PGS PG 3 Slave PGS PG 1 Slave PGS PG 2 Master PGS PG 3 Master PGS Gateway Gateway PG 4 Master PGS PG 5 Slave PGS PG 6 Slave PGS PG 4 Slave PGS PG 5 Master PGS PG 6 Master PGS Gateway Gateway Client (affinity) Client (no affinity) 클러스터의 key mapping 정보를 힌트로 해서 최적의 gateway를 선택하도록 함 (개발 버전) 네트워크 사용량을 최적화
- 30. 성능 테스트 환경 Gateway Gateway Gateway Gateway Gateway Gateway M S S M M S S M M S S M M S S M M S S M M S S M YCSB YCSB YCSB YCSB YCSB YCSB •Load generator 6장비, 클러스터 6대 •24개의 Redis instance (master 12, slave 12) •YCSB Scan 명령 제외 (단일 키 sorted set 사용) Driver는 Jedis 기반 (nBase-ARC java client, Jedis Client)
- 31. 시험 결과 - 1K 100% Write 0 50000 100000 150000 200000 250000 0 200 400 600 OPS (RC) OPS(ARC) 0 0.5 1 1.5 2 2.5 0 200 400 600 Latency (RC) (ms) Latency(ARC)(m s) •Client 개수를 많이 늘릴 수 없는 문제가 있었음 (RC용 Jedis) •CPU 사용량은 RC (10%), ARC (20%) •RC는 클라이언트 개수가 늘어나면 성능이 저하 된다 각 client가 Redis에 직접 연결하기 때문에 connection 개수가 증가 •ARC의 성능 최대치가 RC의 성능 최대치에 미치지 못하는 이유 복제 layer에 의해서 작은 크기의 packet 전송이 추가됨 85 %
- 32. 시험 결과 - 1K 100% Read •CPU 사용량은 RC (10%), ARC (20%) •ARC의 경우 Consistent read 를 위한 복제 상의 overhead Operation 자체는 복제로 전송되지 않지만 순서를 맞추기 위한 reference data는 전송 •Read offloading 0 100000 200000 300000 400000 500000 0 200 400 600 OPS (RC) OPS(ARC) 0 0.2 0.4 0.6 0.8 1 1.2 0 200 400 600 Latency (RC) (ms) Latency(ARC)( ms) 93 %
- 33. 시험 – 결론 •RC: 고성능+, 장애/단절 발생 시 데이터 유실 •ARC: 고성능, DB
- 34. 3. 발전 방향 및 오픈 소스
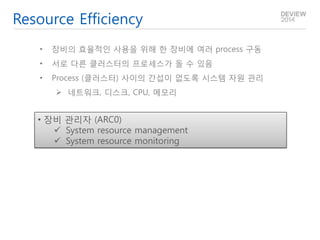
- 35. More Autonomous Cluster •고속으로 동작하는 시스템이기 때문에 사람이 운영에 개입해야 하는 상황이면 이미 대형 장애 상황 •현재는 장애 감지 및 처리만 자동화됨. 더욱 필요 •장비 관리자 (ARC0) Local repository management Process management Heartbeat aggregation
- 36. Resource Efficiency •장비의 효율적인 사용을 위해 한 장비에 여러 process 구동 •서로 다른 클러스터의 프로세스가 돌 수 있음 •Process (클러스터) 사이의 간섭이 없도록 시스템 자원 관리 네트워크, 디스크, CPU, 메모리 •장비 관리자 (ARC0) System resource management System resource monitoring
- 37. Global Management •Global 환경에 여러 zone 이 구축됨에 따라 체계적이고 자동화된 운영 방식이 필요하다 HUB -Zone registry -Resource (e.g. binary) repository -User account -Global management ZONE
- 38. 오픈 소스 2015 준비되는 대로 순차적으로 오픈 할 예정
- 39. THANK YOU