[2D1]Elasticsearch 성능 최적화
89 likes31,054 views

This document discusses Elasticsearch, including understanding how it works and optimizing performance. It covers Elasticsearch concepts like clusters, indexes, shards and nodes. It also discusses installing and configuring Elasticsearch, modeling data, indexing and querying optimizations. Lastly it discusses integrating Elasticsearch with Hadoop and using SQL on Elasticsearch.
![[2D1]Elasticsearch 성능 최적화](https://image.slidesharecdn.com/2d1elasticsearch-140929192211-phpapp02/85/2D1-Elasticsearch-1-320.jpg)





![ElasticSearch구성
Physical구성
Logical구성
1.1.ElasticSearch와동작방식
Cluster
Index
Node
Node
Node
Indice
Indice
Indice
Shard
Shard
Shard
Shard
Shard
Shard
Shard
Shard
Shard
Type
Type
Type
Document
Document
Document
field:value
field:value
field:value
field:value
field:value
field:value
field:value
field:value
field:value
[Physical 구성]
[Logical 구성]](https://image.slidesharecdn.com/2d1elasticsearch-140929192211-phpapp02/85/2D1-Elasticsearch-7-320.jpg)










![Hash partition test
1.3.Modeling 하기
public class EsHashPartitionTest{
@Test
public void testHashPartiion() {
……중략……
for ( inti=0; i<1000000; i++ ) {
intshardId= MathUtils.mod(hash(String.valueOf(i)), shardSize);
shards.add(shardId, (long) ++partSize[shardId]);
}
……중략……
}
public inthash(String routing) {
return hashFunction.hash(routing);
}
}](https://image.slidesharecdn.com/2d1elasticsearch-140929192211-phpapp02/85/2D1-Elasticsearch-18-320.jpg)











![Query
항상같은node 로query hitting이되지않도록한다.
Zero hit query를줄여야한다.
Query 결과를cache 한다.
Avoid deep pagination.
Sorting : number_of_shard×(from +size)
Script 사용시_source, _field 대신doc[‘field’]를사용한다.
2.4.질의최적화
Search type
Query and fetch
Query then fetch
Count
Scan](https://image.slidesharecdn.com/2d1elasticsearch-140929192211-phpapp02/85/2D1-Elasticsearch-31-320.jpg)





![Indexing
Java
Client
Application
MapReduce
3.1.Hadoop 통합
public static void main(String[] args) throws Exception {
...중략...
settings= Connector.buildSettings(esCluster);
client= Connector.buildClient(settings, esNodes.split(","));
runBeforeConfig(esIndice);
Job job= new Job(conf);
...중략...
for ( String distJar: esDistributedCacheJars) {
DistributedCache.addFileToClassPath(
new Path(esDistributedCachePath+"/"+distJar),
job.getConfiguration());
}
...중략...
if ( "true".equalsIgnoreCase(esOptimize) ) {
runOptimize(esIndice);
} else {
runRefreshAndFlush(esIndice);
}
runAfterConfig(esIndice, replica);
}](https://image.slidesharecdn.com/2d1elasticsearch-140929192211-phpapp02/85/2D1-Elasticsearch-37-320.jpg)


![Searching
ElasticSearch
Hadoop
Plugin
MapReduce
3.1.Hadoop 통합
public static class SearchMapperextends Mapper {
@Override
public void map(Object key, Object value, Context context)
throws IOException, InterruptedException{
Text docId= (Text) key;
LinkedMapWritabledoc = (LinkedMapWritable) value;
System.out.println(docId);
}
}
public static void main(String[] args) throws Exception {
Configuration conf= new Configuration();
...중략...
Job job= new Job(conf);
...중략...
conf.set(ConfigurationOptions.ES_QUERY,
"{ "query" : { "match_all" : {} } }");
job.setNumReduceTasks(0);
booleanresult = job.waitForCompletion(true);
}](https://image.slidesharecdn.com/2d1elasticsearch-140929192211-phpapp02/85/2D1-Elasticsearch-40-320.jpg)



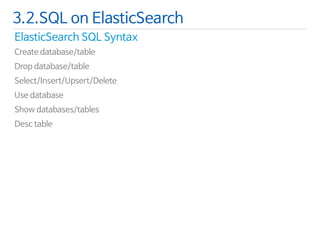
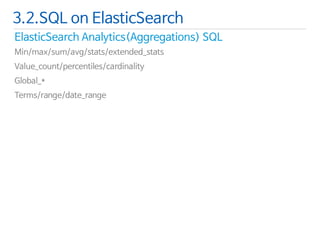
![ElasticSearchSQL vs. Query DSL
3.2.SQL on ElasticSearch
SQL
Query DSL
SELECT *
FROM type_name
LIMIT 0/10
"match_all": {}
…
“from” : 0,
“size” : 10
SELECT field1, field2
FROM type_name
WHERE search_field= ‘elasticsearch’
"term": {
"search_field": {
"value": "elasticsearch"
}
}
…
"fields": [
"field1","field2"
]](https://image.slidesharecdn.com/2d1elasticsearch-140929192211-phpapp02/85/2D1-Elasticsearch-46-320.jpg)
![ElasticSearchSQL vs. Query DSL
3.2.SQL on ElasticSearch
SQL
Query DSL
SELECT *
FROM type_name
WHERE search_ field > ‘20140624235959’
ORDER BY search_fieldDESC
"range": {
"search_field": {
"gt": "20140624235959"
}
}
…
"sort": [
{
"search_field": {
"order": "desc"
}
}
]](https://image.slidesharecdn.com/2d1elasticsearch-140929192211-phpapp02/85/2D1-Elasticsearch-47-320.jpg)




[2D1]Elasticsearch 성능 최적화
- 2. 정호욱책임/ BigDataPlatform Team 그루터 ElasticSearch의이해와 성능최적화
- 3. 저는요… •정호욱 •BigdataPlatform, GruterCorp •[email protected] •http://jjeong.tistory.com •E-book: 실무예제로배우는Elasticsearch검색엔진-입문편
- 4. 1.ElasticSearch이해 2.ElasticSearch 성능최적화이해 3.ElasticSearch 빅데이터활용 CONTENTS
- 5. 1.ElasticSearch 이해 1.1.ElasticSearch와동작방식 1.2.설치및실행하기 1.3.Modeling 하기
- 6. ElasticSearch란? Lucene기반의오픈소스검색엔진 1.1.ElasticSearch와동작방식 ElasticSearch특징 Easy Real time search & analytics Distributed & highly available search engine
- 7. ElasticSearch구성 Physical구성 Logical구성 1.1.ElasticSearch와동작방식 Cluster Index Node Node Node Indice Indice Indice Shard Shard Shard Shard Shard Shard Shard Shard Shard Type Type Type Document Document Document field:value field:value field:value field:value field:value field:value field:value field:value field:value [Physical 구성] [Logical 구성]
- 8. ElasticSearchNodes Master node Data node Search load balancer node Client node 1.1.ElasticSearch와동작방식 Master node.master: true Data node.data: true Search LB node.master: false node.data: false Client node.client: true
- 9. ElasticSearchNodes 구성예 1.1.ElasticSearch와동작방식 Case 1) All round player node.master: true node.data: true node.master: true node.data: true node.master: true node.data: true Case 2) Master Data node.master: true node.data: false node.master: true node.data: false node.master: false node.data: true node.master: false node.data: true Case 3) Master Data Search LB node.master: true node.data: false node.master: true node.data: false node.master: false node.data: true node.master: false node.data: true node.master: false node.data: false node.master: false node.data: false
- 10. ElasticSearchvs RDBMS 1.1.ElasticSearch와동작방식 Relational Database ElasticSearch Database Index Table Type Row Document Column Field Index Analyze Primary key _id Schema Mapping Physical partition Shard Logical partition Route Relational Parent/Child, Nested SQL Query DSL
- 11. ElasticSearchshard replication 1.1.ElasticSearch와동작방식 POST /my_index/_settings{ "number_of_replicas":1} POST /my_index/_settings{ "number_of_replicas":2} http://www.elasticsearch.org/guide/en/elasticsearch/guide/current/replica-shards
- 12. Creating, indexing and deleting a document 1.1.ElasticSearch와동작방식 http://www.elasticsearch.org/guide/en/elasticsearch/guide/current/distrib-write.html
- 13. Retrieve, query and fetch a document 1.1.ElasticSearch와동작방식 http://www.elasticsearch.org/guide/en/elasticsearch/guide/current/distrib-read.html http://www.elasticsearch.org/guide/en/elasticsearch/guide/current/_query_phase.html http://www.elasticsearch.org/guide/en/elasticsearch/guide/current/_fetch_phase.html
- 14. 설치하기 다운로드 압축해제 1.2.설치및실행하기 실행하기 실행 테스트 Create index Add document Get document Search document
- 15. Indice/type design Time-based/User-based data Relational data 1TB 1.3.Modeling 하기 Field design 검색대상필드 분석대상필드 정렬대상필드 저장대상필드 Primary key 필드
- 16. Modeling 구성예 1.3.Modeling 하기 Indice1 Indice2 Indice3 IndiceA IndiceB IndiceC Type Parent Type Child Type Parent Type Child Type Child Type 1 : N 1 : N 1 : N
- 17. Shard design number_of_shards>= number_of_data_nodes number_of_replica<= number_of_data_nodes-1 1.3.Modeling 하기 Shard sizing Index 당최대shard 수: 200 개이하 Shard 하나당최대크기: 20 ~ 50GB Shard 하나당최소크기: ~ 3GB
- 18. Hash partition test 1.3.Modeling 하기 public class EsHashPartitionTest{ @Test public void testHashPartiion() { ……중략…… for ( inti=0; i<1000000; i++ ) { intshardId= MathUtils.mod(hash(String.valueOf(i)), shardSize); shards.add(shardId, (long) ++partSize[shardId]); } ……중략…… } public inthash(String routing) { return hashFunction.hash(routing); } }
- 19. 2.ElasticSearch 성능최적화 이해 2.1.성능에영향을미치는요소들 2.2.설정최적화 2.3.색인최적화 2.4.질의최적화
- 20. 장비관점 Network bandwidth? Disk I/O? RAM? CPU cores? 2.1.성능에영향을미치는요소들 문서관점 Document size? Total index data size? Data size increase? Store period? 서비스관점 Analyzer? Analyze fields? Indexed field size? Boosting? Realtimeor batch? Queries?
- 21. In ElasticSearchsite: If 1 shard is too few and 1,000 shards are too many, how do I know how many shards I need? This is a question that is impossible to answer in the general case. There are just too many variables: the hardware that you use, the size and complexity of your documents, how you index and analyze those documents, the types of queries that you run, the aggregations that you perform, how you model your data, etc., etc. 2.1.성능에영향을미치는요소들 http://www.elasticsearch.org/guide/en/elasticsearch/guide/current/capacity-planning.html
- 22. In ElasticSearchsite: Fortunately, it is an easy question to answer in the specific case: yours. 1.Create a cluster consisting of a single server, with the hardware that you are considering using in production. 2.Create an index with the same settings and analyzers that you plan to use in production, but with only on primary shard and no replicas. 3.Fill it with real documents (or as close to real as you can get). 4.Run real queries and aggregations (or as close to real as you can get). 2.1.성능에영향을미치는요소들 http://www.elasticsearch.org/guide/en/elasticsearch/guide/current/capacity-planning.html
- 23. 운영체제관점 Increase File descriptor Avoid swap 2.2.설정최적화 검색엔진관점 Avoid swap Thread pool Segment merge Index buffer size Storage device Use recent version
- 24. Cluster restart관점 Optimize (max segments: 5) Close index Restart after set “disable_allocation: true” Increase recovery limits 2.2.설정최적화
- 25. Modeling Disable “_all”fields Disable “_source” fields, so far as possible Set right value to “_id” fields Set false to “store” fields, so far as possible 2.3.색인최적화
- 26. Sizing Indice는데이터의크기를관리할수있는용도로사용한다. Indice당primary shard 수는data node 수보다크거나같아야한다. (number_of_shards>= number_of_data_nodes) Indice당shard 수는200개미만으로구성한다. Shard 하나의크기는50GB 미만으로구성한다. 2.3.색인최적화
- 27. Client Bulk API를사용한다. Hardware 성능을점검한다. Exception을확인한다. Thread pools을점검한다. 1110(Node,Indice,Shard,Replica)으로점검한다. Optimize 대신Flush와Refresh를활용한다. 2.3.색인최적화
- 28. Bulk indexing Request 당크기는5 ~ 15MB Request 당문서크기는1,000 ~ 5,000개 Server bulk thread pool 크기는core size ×5 보다작거나같게설정 Client bulk connection pool 크기는3 ~ 10개×number_of_data_nodes Client ping timeout은30 ~ 90초로설정 Client node sampler interval은30 ~ 90초로설정 Client transport sniff를true로설정 Client network TCP blocking을false로설정 2.3.색인최적화
- 29. Bulk indexing Disable refresh_interval Disable replica Use flush & refresh (instead of optimize) 2.3.색인최적화 Bulk indexing flow Update Settings Bulk Request Flush & Refresh Update Settings
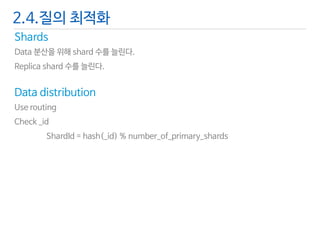
- 30. Shards Data 분산을위해shard 수를늘린다. Replica shard 수를늘린다. 2.4.질의최적화 Data distribution Use routing Check _id ShardId= hash(_id) % number_of_primary_shards
- 31. Query 항상같은node 로query hitting이되지않도록한다. Zero hit query를줄여야한다. Query 결과를cache 한다. Avoid deep pagination. Sorting : number_of_shard×(from +size) Script 사용시_source, _field 대신doc[‘field’]를사용한다. 2.4.질의최적화 Search type Query and fetch Query then fetch Count Scan
- 32. Queries vs. Filters Query 대신filtered query와filter를사용한다. And/or/not filter 대신boolfilter를사용한다. 2.4.질의최적화 Queries Filters Relevance Binary yes/no Full text Exactvalues Not cached Cached Slower Faster “query” : { “match_all” : { } } “query” : { “filtered” : { “query” : { “match_all” : {} } } }
- 33. 3.ElasticSearch 빅데이터 활용 3.1.Hadoop 통합 3.2.SQL on ElasticSearch
- 34. ElasticSearchHadoop 활용 Big data 분석을위한도구 Snapshot & Restore 저장소 ElasticSearchHadoop plugin 도구제공 3.1.Hadoop 통합
- 35. Indexing 3.1.Hadoop 통합 ElasticSearch Hadoop plugin Read raw data Integrate natively Bulk indexing Java client application BulkRequestBuilder REST API Control concurrency request
- 36. Indexing ElasticSearch Hadoop Plugin MapReduce 3.1.Hadoop 통합 Configuration conf= new Configuration(); …중략… conf.set(Configuration.ES_NODES, “localhost:9200”); conf.set(Configuration.ES_RESOURCE, “blog/post”); …중략… Job job= new Job(conf); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(EsOutputFormat.class); job.setMapOutputValueClass(LinkedMapWritable.class); job.setMapperClass(TabMapper.class); job.setNumReduceTasks(0); File fl= new File(“blog/post.txt”); long splitSize= fl.length() / 3; TextInputFormat.setMaxInputSplitSize(job, splitSize); TextInputFormat.setMinInputSplitSize(job, 50); booleanresult = job.waitForCompletion(true);
- 37. Indexing Java Client Application MapReduce 3.1.Hadoop 통합 public static void main(String[] args) throws Exception { ...중략... settings= Connector.buildSettings(esCluster); client= Connector.buildClient(settings, esNodes.split(",")); runBeforeConfig(esIndice); Job job= new Job(conf); ...중략... for ( String distJar: esDistributedCacheJars) { DistributedCache.addFileToClassPath( new Path(esDistributedCachePath+"/"+distJar), job.getConfiguration()); } ...중략... if ( "true".equalsIgnoreCase(esOptimize) ) { runOptimize(esIndice); } else { runRefreshAndFlush(esIndice); } runAfterConfig(esIndice, replica); }
- 38. Indexing Java Client Application MapReduce 3.1.Hadoop 통합 public void map(Object key, Object value, Context context) throws Exception { ...중략... IndexRequestindexRequest= new IndexRequest(); indexRequest= indexRequest.index(esIndice) .type(esType) .source(doc); ...중략... bulkRequest.add(indexRequest); ...중략... bulkResponse= bulkRequest.setConsistencyLevel(QUORUM) .setReplicationType(ASYNC) .setRefresh(false) .execute() .actionGet(); ...중략... }
- 39. Searching 3.1.Hadoop 통합 ElasticSearchHadoop plugin Integrate natively Query request Java client application Query request
- 40. Searching ElasticSearch Hadoop Plugin MapReduce 3.1.Hadoop 통합 public static class SearchMapperextends Mapper { @Override public void map(Object key, Object value, Context context) throws IOException, InterruptedException{ Text docId= (Text) key; LinkedMapWritabledoc = (LinkedMapWritable) value; System.out.println(docId); } } public static void main(String[] args) throws Exception { Configuration conf= new Configuration(); ...중략... Job job= new Job(conf); ...중략... conf.set(ConfigurationOptions.ES_QUERY, "{ "query" : { "match_all" : {} } }"); job.setNumReduceTasks(0); booleanresult = job.waitForCompletion(true); }
- 41. Searching Java Client Application 3.1.Hadoop 통합 SearchResponsesearchResponse; MatchAllQueryBuilder matchAllQueryBuilder= new MatchAllQueryBuilder(); searchResponse= client.prepareSearch(esIndice) .setQuery(matchAllQueryBuilder) .execute() .actionGet(); System.out.println(searchResponse.toString());
- 42. ElasticSearchSQL 이란? 쉬운접근성과데이터분석도구를제공한다. 표준SQL 문법을Query DSL로변환한다. 표준SQL 문법을사용하여검색엔진으로CRUD 연산을수행할수있다. JDBC drive와CLI 기능을제공하고있다. Apache Tajo용SQL analyzer를사용하고있다. 3.2.SQL on ElasticSearch
- 43. ElasticSearchJDBC driver 3.2.SQL on ElasticSearch Client Application JDBC Driver Elastic Search SQL Analyzer Algebra Expression Query DSL Planner Query Execution SQL DSL
- 44. ElasticSearchSQL Syntax Create database/table Drop database/table Select/Insert/Upsert/Delete Use database Show databases/tables Desctable 3.2.SQL on ElasticSearch
- 45. ElasticSearchAnalytics(Aggregations) SQL Min/max/sum/avg/stats/extended_stats Value_count/percentiles/cardinality Global_* Terms/range/date_range 3.2.SQL on ElasticSearch
- 46. ElasticSearchSQL vs. Query DSL 3.2.SQL on ElasticSearch SQL Query DSL SELECT * FROM type_name LIMIT 0/10 "match_all": {} … “from” : 0, “size” : 10 SELECT field1, field2 FROM type_name WHERE search_field= ‘elasticsearch’ "term": { "search_field": { "value": "elasticsearch" } } … "fields": [ "field1","field2" ]
- 47. ElasticSearchSQL vs. Query DSL 3.2.SQL on ElasticSearch SQL Query DSL SELECT * FROM type_name WHERE search_ field > ‘20140624235959’ ORDER BY search_fieldDESC "range": { "search_field": { "gt": "20140624235959" } } … "sort": [ { "search_field": { "order": "desc" } } ]
- 48. SQL on ElasticSearch Demo
- 49. ElasticSearch이해 Lucene기반의분산검색엔진 ElasticSearch성능최적화이해 정답은없지만… 항상좋은장비에최신버전을사용한다. 확장가능한modeling과sizing을구성한다. 병목구간을항상모니터링한다. Query와filter를목적에맞게사용한다. Bulk API를사용한다. ElasticSearch빅데이터활용 Hadoop과SQL로쉽게분석도구로활용한다. 마무리하며…
- 51. THANK YOU