A Dataflow Processing Chip for Training Deep Neural Networks
1 like2,507 views

Wave Computing has developed a dataflow processing chip designed to accelerate deep neural network training by up to 1000x, featuring a unique DPU architecture optimized for deep learning tasks. The company, established in 2010 and based in Campbell, CA, is now offering early access programs to selected customers for testing their advanced machine learning technology. Their system promises significant improvements in compute efficiency and scalability for deep learning applications, particularly in the context of rapidly increasing data demands.
























A Dataflow Processing Chip for Training Deep Neural Networks
- 1. A Dataflow Processing Chip for Training Deep Neural Networks Dr. Chris Nicol Chief Technology Officer Wave Computing Copyright 2017.
- 2. Founded in 2010 • Tallwood Venture Capital • Southern Cross Venture Partners Headquartered in Campbell, CA • World class team of 53 dataflow, data science, and systems experts • 60+ patents Invented Dataflow Processing Unit (DPU) architecture to accelerate deep learning training by up to 1000x • Coarse Grain Reconfigurable Array (CGRA) Architecture • Static scheduling of data flow graphs onto massive array of processors Now accepting qualified customers for Early Access Program Wave Computing. Copyright 2017. Wave Computing Profile
- 3. Extended training time due to increasing size of datasets • Weeks to tune and train typical deep learning models Hardware for accelerating ML was created for other applications • GPUs for graphics, FPGA’s for RTL emulation Data coming in “from the edge” is growing faster than the datacenter can accommodate/use it… Design •Neural network architecture •Cost functions Tune •Parameter initialization •Learning rate •Mini-batch size Train •Accuracy •Convergence Rate Deploy •For testing Deploy •For production ➢ Problem: Model development times can take days or weeks Wave Computing. Copyright 2017. Challenges of Machine Learning
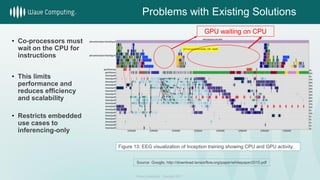
- 4. Source: Google; http://download.tensorflow.org/paper/whitepaper2015.pdf • Co-processors must wait on the CPU for instructions • This limits performance and reduces efficiency and scalability • Restricts embedded use cases to inferencing-only GPU waiting on CPU Figure 13: EEG visualization of Inception training showing CPU and GPU activity. Wave Computing. Copyright 2017. Problems with Existing Solutions
- 5. Times Times I/O Softmax Plus Plus Mem I/OSigmoid Programmed on Deep Learning Software Run on Wave Dataflow Processor Times Times Plus Plus Softmax Sigmoid Deep Learning Networks are Dataflow Graphs Wave Dataflow Processor WaveFlow Agent Library Wave Computing. Copyright 2017. Wave Dataflow Processor is Ideal for Deep Learning
- 6. DDR4 DDR4 HMCHMC HMCHMC PCIe Gen3 x16 MCU AXI4 AXI4 AXI4 AXI4 Secure DPU Program Buffer Secure DPU Program Loader 16ff CMOS Process Node 16K Processors, 8192 DPU Arithmetic Units Self-Timed, MPP Synchronization 181 Peak Tera-Ops, 7.25 Tera Bytes/sec Bisection Bandwidth 16 MB Distributed Data Memory 8 MB Distributed Instruction Memory 1.71 TB/s I/O Bandwidth 4096 Programmable FIFOs 270 GB/s Peak Memory Bandwidth 2048 outstanding memory requests 4 Billion 16-Byte Random Access Transfers / sec 4 Hybrid Memory Cube Interfaces 2 DDR4 Interfaces PCIe Gen3 16-Lane Host interface 32-b Andes N9 MCU 1 MB Program Store for Paging Hardware Engine for Fast Loading of AES Encrypted Programs Up to 32 Programmable dynamic reconfiguration zones Variable Fabric Dimensions (User Programmable at Boot) Wave Computing. Copyright 2017. Wave Dataflow Processing Unit Chip Characteristics & Design Features • Clock-less CGRA is robust to Process, Voltage & Temperature. • Distributed memory architecture for parallel processing • Optimized for data flow graph execution • DMA-driven architecture – overlapping I/O and computation
- 7. Key DPU Board Features • 65,536 CGRA Processing Elements • 4 Wave DPU chips per board • Modular, flexible design • Multiple DPU boards per Wave Compute Appliance • Off-the-shelf components • 32GB of ultra high-speed DRAM • 512GB of DDR4 DRAM • FPGA for high-speed board-to-board communication Wave Computing. Copyright 2017. Wave Current Generation DPU Board
- 8. • Best-in-class, highly scalable deep learning training and inference • More than orders of magnitude better compute-power efficiency • Plug-and-play node in a datacenter network -- Big Data – Hadoop, Yarn, Spark, Kafka • Native support of Google TensorFlow (initially) Wave Computing. Copyright 2017. Wave’s Solution: Dataflow Computer for Deep Learning
- 9. Pipelined 1KB Single Port Data RAM /w BIST & ECC Pipelined 256-entry Instruction RAM /w ECC Quad of PEs are fully connected PE c PE a PE b PE d Wave Computing. Copyright 2017. Dataflow Processing Element (PE)
- 10. • 16 Processor CLUSTER: a full custom tiled GDSII block • Fully-Connected PE Quads with fan-out • 8 DPU Arithmetic Units – Per-cycle grouping into 8, 16, 24, 32, 64-b Operations – Pipelined MAC Units with (un)Signed Saturation – Support for floating point emulation – Barrel Shifter, Bit Processor – SIMD and MIMD instruction classes – Data driven • 16KB Data RAM • 16 Instruction RAMs • Full custom semi-static digital circuits • Robust PVT insensitive operation – Scalable to low voltages – No global signals, no global clocks Wave Computing. Copyright 2017. Cluster of 16 Dataflow PEs
- 11. Each cluster has a pipelined instruction-driven word-level switch Each cluster has a 4 independent pipelined instruction driven byte-switches Word switch supports fan-out and fan-in fan-in All switches have registers for Router use to avoid congestion “valid” and “invalid” data in the switch enables fan-in fan-out Wave Computing. Copyright 2017. Hybrid CGRA Architecture
- 12. From Asleep to Active • Word switch fabric remains active • If valid data arrives at switch input AND switch executes instruction to send data to one of Quads THEN wake up PEs • Copy PC from word switch to PE and byte switch iRAMs • Send the incoming data to the PEs From Active to Asleep • A PE executes a “sleep” instruction • All PE & byte switch execution is suspended • PE can opt for fast wakeup or slow wakeup (deep sleep with lower power) Wave Computing. Copyright 2017. Data-Driven Power Management
- 13. Wave Computing. Copyright 2017. Compute Machine with AXI4 Interfaces
- 14. 24 Compute Machines Wave Computing. Copyright 2017. Wave DPU Hierarchy
- 15. Wave Computing. Copyright 2017. Wave DPU Memory Hierarchy
- 16. • Clock skew and jitter limit cycle time with traditional clock distribution • Self-timed “done” signal from PEs if they are awake. Programmable tuning of margin. • Synchronized with neighboring Clusters to minimize skew • 1-sigma local mismatch ~1.3ps and global + local mismatch ~6ps at 140ps cycle time Clock Distribution and Generation Network across entire Fabric Wave Computing. Copyright 2017. 6-10 GHz Auto-Calibrated Clock Distribution
- 17. -4 -5 -3 -4 -6 -7 -5 -6 -2 -3 -1 -2 -4 -5 -3 -4 Up-counter in each cluster initialized to -(1+Manhattan distance from end cluster) End cluster Start cluster When counter reaches 0, either: - Reset the processors - Suspend processors for configuration (at PC=0) - Enable processors to execute (from PC=0) -4 -5 -3 -4 -6 -7 -5 -6 -2 -3 -1 -2 -4 -5 -3 -4 Pre-program 4 clusters to ENTER config mode. Counters operating 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 DMA new kernel instructions into cluster I-mems -4 -5 -3 -4 -6 -7 -5 -6 -2 -3 -1 -2 -4 -5 -3 -4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Old kernel Enter config mode Exit config modePropagate SignalPropagate Signal Step 1 Step 2 Step 3 Step 4 Propagate control signal from start cluster to end cluster. Advances 1 cluster per cycle. Pre-program 4 clusters to EXIT config mode. All clusters running in-synch New kernel SW controls this process to manage surge current Propagate signal starts the up-counter in each cluster. Counters operating Counters operating New kernel Reset, Configuration Modes Stop (config mode) (running) (running) (running) (running) (running) (running) (running) (running) (running)
- 18. 1 1 1 1 2 2 2 2 - - - - 2 2 2 2 Kernel1 and kernel2 mounted. 3 3 3 3 I/O Mount(kernel3) (note: I/Os at bottom) New Kernel goes here! 1 1 1 1 2 2 2 2 3 3 3 3 2 2 2 2 After mount(kernel3) I/O I/O I/O Just-in-time route through Kernel 2 The I/Os cannot go here! • Runtime resource manager in lightweight host. • Mount(). Online placement algorithm with maxrects management of empty clusters. • Uses “porosity map” for each kernel showing route-thru opportunities. (SDK provides this) • Just-in-time Place & Route (using A*) of I/Os through other kernels without functional side-effects. • Unmount(). Removes paths through other kernels. • Machines are combined for mounting large kernels. Partitioned during unmount(). • Periodic garbage collection used for cleanup. • Average mount time < 1ms Runtime resource manager performing mount() Dynamic Reconfiguration
- 19. • WFG Compiler • WFG Linker • WFG Simulator • DF agent partitioning • DFG throughput optimization • Runs on Session Host WaveFlow Execution Engine • Resource Manager • Monitors • Drivers • Runs on a Wave Deep Learning Computer WaveFlow Session Manager WaveFlow Agent Library • BLAS 1,2,3 • CONV2D • SoftMax, etc. WaveFlow SDK On line Off line Encrypted Agent Code Wave Computing. Copyright 2017. WaveFlow Software Stack
- 20. WaveFlow agents are pre compiled off-line using WaveFlow SDK • Wave provides a complete agent library for TensorFlow • Customer can create additional agents for differentiation Customer supplied agent source code Wave supplied agent source code WaveFlow Agent Library Wave SDK • WFG Compiler • WFG Linker • WFG Simulator • WFG Debugger • MATMUL • Batchnorm • Relu, etc. Your new DNN training technique Encrypted Agent Code Wave Computing. Copyright 2017. WaveFlow Agent Library
- 21. SATSolver WFG Compiler LLVM Frontend WFG Linker AssemblerArchitectural Simulator WaveFlow Agents WFG Simulator ML function (gemm, sigmoid, …) To appear in ICCAD 2017 WFG = Wave Flow Graph Wave Computing. Copyright 2017. WaveFlow SDK
- 22. Kernels are islands of machine code scheduled onto machine cycles Example: Sum of Products on 16 PEs in a single cluster WFG of Sum of ProductsSum of Products Kernel PE 0 to 15 Time mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mac mac mac mac mac mac mac mac mac mac mac mac mac mac mac mac mov mov movcr mov mov mov mov mov mov mov movcr movi mov mov mov movcr mov mov mov movi mov mov mov movcr mov mov mov add8 mov mov mov mov mov mov mov add8 mov mov mov incc8 mov movcr mov mov mov movcr mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov movcr mov mov mov mov mov memr movcr mov memr mov mov mov mov mov mov mov movcr mov mov mov mov movcr mov mov mov movcr mov mov mov mov mov mac mac mov mov mov mov mov mov mac mac mov mov mov mov mac mac mov mov mac mac mac mac mac mac mov mov mac mac mac mac mov mov mov memr mov mov mov mov mov mov mov mov mov movcr mov mov mov movcr mov mov memr mov mov mov mov mov mov incc8 mov mov mov mov incc8 mov mov mov mov mov mov mov mov mov mov mov mov mov mov incc8 mov mov mov movcr movcr memw mov mov mov mov mov mov mov movcr mov mov mov mov mov mov mov memr mov mov mov memr incc8 mov mov mov mov st mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mac mac mac mac mac mac mac mac mac mac mac mac mac mac mac mac mov mov mov mov mov mov mov mov mov mov mov mov mov mov memr mov mov mov memr mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov cmuxi mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov memr mov mov mov memr mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mac mac mac mac mac mac mac mac mac mac mac mac mac mac mac mac mov mov mov mov mov mov mov mov mov mov mov mov mov mov memr mov mov memr mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mac mac mac mac mac mac mac mac mac mac mac mac mac mac mac mac mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov memr mov mov mov mov mov mov mov mov memr mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mac mac mac mac mac mac mac mac mac mac mac mac mac mac mac mac mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mac mac mac mac mac mac mac mac mac mac mac mac mac mac mac mac mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mov mac mac mac mac mac mac mac mac mac mac mac mac mac mac mac mac mov mov mov mov mov mov mov mov mov mov Wave Computing. Copyright 2017. Wave SDK: Compiler Produces Kernels
- 23. Session Manager Partitions & Maps to DPUs & Memory Inference Graph generated directly from Keras model by Wave Compiler Wave Flow Graph Format Mapping Inception V4 to DPUs Single Node 64-DPU Computer
- 24. Benchmarks on a single node 64-DPU Data Flow Computer • ImageNet training, 90 epochs, 1.28M images, 224x224x3 • Seq2Seq training using parameters from https://papers.nips.cc/paper/5346-sequence-to-sequence- learning-with-neural-networks.pdf by I. Sutskever, O. Vinyals & Q. Le Network Inferencing (Images/sec) Training time AlexNet 962,000 40 mins GoogleNet 420,000 1 hour 45 mins Squeezenet 75,000 3 hours Seq2Seq - 7 hours 15 min Deep Neural Network Performance Wave Computing. Copyright 2017.
- 25. Wave is now accepting qualified customers to its Early Access Program (EAP) Provides select companies access to a Wave machine learning computer for testing and benchmarking months before official system sales begin For details about participation in the limited number of EAP positions, contact [email protected] Wave Computing. Copyright 2017. Wave’s Early Access Program