A Deep Dive into Stateful Stream Processing in Structured Streaming with Tathagata Das
14 likes6,278 views

The document details stateful stream processing in Apache Spark's Structured Streaming, highlighting its fast, scalable, and fault-tolerant capabilities with high-level APIs. It covers the anatomy of streaming queries, including sources, transformations, and sinks, while emphasizing the importance of state management, watermarking, and fault recovery mechanisms. Additionally, it discusses various operations such as streaming aggregation, deduplication, and user-defined stateful processing using APIs like mapGroupsWithState.







![Anatomy of a Streaming Query
spark.readStream.format("kafka")
.option("kafka.boostrap.servers",...)
.option("subscribe", "topic")
.load()
Kafka DataFrame
key value topic partition offset timestamp
[binary] [binary] "topic" 0 345 1486087873
[binary] [binary] "topic" 3 2890 1486086721](https://image.slidesharecdn.com/1tathagatadas-180613002030/85/A-Deep-Dive-into-Stateful-Stream-Processing-in-Structured-Streaming-with-Tathagata-Das-8-320.jpg)






































![MapGroupsWithState - How to use?
2. Define function to update
state of each grouping
key using the new data
Input
Grouping key: userId
New data: new user actions
Previous state: previous status
of this user
case class UserAction(
userId: String, action: String)
case class UserStatus(
userId: String, active: Boolean)
def updateState(
userId: String,
actions: Iterator[UserAction],
state: GroupState[UserStatus]):UserStatus = {
}](https://image.slidesharecdn.com/1tathagatadas-180613002030/85/A-Deep-Dive-into-Stateful-Stream-Processing-in-Structured-Streaming-with-Tathagata-Das-48-320.jpg)
![MapGroupsWithState - How to use?
2. Define function to update
state of each grouping key
using the new data
Body
Get previous user status
Update user status with actions
Update state with latest user status
Return the status
def updateState(
userId: String,
actions: Iterator[UserAction],
state: GroupState[UserStatus]):UserStatus = {
}
val prevStatus = state.getOption.getOrElse {
new UserStatus()
}
actions.foreah { action =>
prevStatus.updateWith(action)
}
state.update(prevStatus)
return prevStatus](https://image.slidesharecdn.com/1tathagatadas-180613002030/85/A-Deep-Dive-into-Stateful-Stream-Processing-in-Structured-Streaming-with-Tathagata-Das-49-320.jpg)
![MapGroupsWithState - How to use?
3. Use the user-defined function
on a grouped Dataset
Works with both batch and
streaming queries
In batch query, the function is called
only once per group with no prior state
def updateState(
userId: String,
actions: Iterator[UserAction],
state: GroupState[UserStatus]):UserStatus = {
}
// process actions, update and return status
userActions
.groupByKey(_.userId)
.mapGroupsWithState(updateState)](https://image.slidesharecdn.com/1tathagatadas-180613002030/85/A-Deep-Dive-into-Stateful-Stream-Processing-in-Structured-Streaming-with-Tathagata-Das-50-320.jpg)




![FlatMapGroupsWithState
More general version where the
function can return any number
of events, possibly none at all
Example: instead of returning
user status, want to return
specific actions that are
significant based on the history
def updateState(
userId: String,
actions: Iterator[UserAction],
state: GroupState[UserStatus]):
Iterator[SpecialUserAction] = {
}
userActions
.groupByKey(_.userId)
.flatMapGroupsWithState
(outputMode, timeoutConf)
(updateState)](https://image.slidesharecdn.com/1tathagatadas-180613002030/85/A-Deep-Dive-into-Stateful-Stream-Processing-in-Structured-Streaming-with-Tathagata-Das-55-320.jpg)



![Monitoring the state of Query State
Get current state metrics using the
last progress of the query
Total number of rows in state
Total memory consumed (approx.)
Get it asynchronously through
StreamingQueryListener API
val progress = query.lastProgress
print(progress.json)
{
...
"stateOperators" : [ {
"numRowsTotal" : 660000,
"memoryUsedBytes" : 120571087
...
} ],
}
new StreamingQueryListener {
...
def onQueryProgress(
event: QueryProgressEvent)
}](https://image.slidesharecdn.com/1tathagatadas-180613002030/85/A-Deep-Dive-into-Stateful-Stream-Processing-in-Structured-Streaming-with-Tathagata-Das-59-320.jpg)



![Managing Very Large Statewith RocksDB
In Databricks Runtime, you can store state locally in RocksDB
Avoids JVM heap, no GC issues with 100 millions state keys per worker
Local RocksDB snapshot files automatically checkpointed to HDFS
Same exactly-once fault-tolerant guarantees
Latency
capped
at 10s
[More info in Databricks Docs]](https://image.slidesharecdn.com/1tathagatadas-180613002030/85/A-Deep-Dive-into-Stateful-Stream-Processing-in-Structured-Streaming-with-Tathagata-Das-63-320.jpg)




A Deep Dive into Stateful Stream Processing in Structured Streaming with Tathagata Das
- 1. A Deep Dive into Stateful Stream Processing in Structured Streaming Spark Summit 2018 5th June, San Francisco Tathagata “TD” Das @tathadas
- 2. Structured Streaming stream processing on Spark SQL engine fast, scalable, fault-tolerant rich, unified, high level APIs deal with complex data and complex workloads rich ecosystem of data sources integrate with many storage systems
- 3. you should not have to reason about streaming
- 4. you should write simple queries & Spark should continuously update the answer
- 5. Treat Streams as Unbounded Tables data stream unbounded input table new data in the data stream = new rows appended to a unbounded table
- 6. Anatomy of a Streaming Query Example Read JSON data from Kafka Parse nested JSON Store in structured Parquet table Get end-to-end failure guarantees ETL
- 7. Anatomy of a Streaming Query spark.readStream.format("kafka") .option("kafka.boostrap.servers",...) .option("subscribe", "topic") .load() Source Specify where to read data from Built-in support for Files / Kafka / Kinesis* Can include multiple sources of different types using join() / union() *Available only on Databricks Runtime returns a Spark DataFrame (common API for batch & streaming data)
- 8. Anatomy of a Streaming Query spark.readStream.format("kafka") .option("kafka.boostrap.servers",...) .option("subscribe", "topic") .load() Kafka DataFrame key value topic partition offset timestamp [binary] [binary] "topic" 0 345 1486087873 [binary] [binary] "topic" 3 2890 1486086721
- 9. Anatomy of a Streaming Query spark.readStream.format("kafka") .option("kafka.boostrap.servers",...) .option("subscribe", "topic") .load() .selectExpr("cast (value as string) as json") .select(from_json("json", schema).as("data")) Transformations Cast bytes from Kafka records to a string, parse it as a json, and generate nested columns 100s of built-in, optimized SQL functions like from_json user-defined functions, lambdas, function literals with map, flatMap…
- 10. Anatomy of a Streaming Query Sink Write transformed output to external storage systems Built-in support for Files / Kafka Use foreach to execute arbitrary code with the output data Some sinks are transactional and exactly once (e.g. files) spark.readStream.format("kafka") .option("kafka.boostrap.servers",...) .option("subscribe", "topic") .load() .selectExpr("cast (value as string) as json") .select(from_json("json", schema).as("data")) .writeStream .format("parquet") .option("path", "/parquetTable/")
- 11. Anatomy of a Streaming Query Processing Details Trigger: when to process data - Fixed interval micro-batches - As fast as possible micro-batches - Continuously (new in Spark 2.3) Checkpoint location: for tracking the progress of the query spark.readStream.format("kafka") .option("kafka.boostrap.servers",...) .option("subscribe", "topic") .load() .selectExpr("cast (value as string) as json") .select(from_json("json", schema).as("data")) .writeStream .format("parquet") .option("path", "/parquetTable/") .trigger("1 minute") .option("checkpointLocation", "…") .start()
- 12. DataFrames, Datasets, SQL Logical Plan Read from Kafka Project device, signal Filter signal > 15 Write to Parquet Spark automatically streamifies! Spark SQL converts batch-like query to a series of incremental execution plans operating on new micro-batches of data Kafka Source Optimized Operator codegen, off- heap, etc. Parquet Sink Optimized Plan spark.readStream.format("kafka") .option("kafka.boostrap.servers",...) .option("subscribe", "topic") .load() .selectExpr("cast (value as string) as json") .select(from_json("json", schema).as("data")) .writeStream .format("parquet") .option("path", "/parquetTable/") .trigger("1 minute") .option("checkpointLocation", "…") .start() Series of Incremental Execution Plans process newdata t = 1 t = 2 t = 3 process newdata process newdata
- 13. process newdata t = 1 t = 2 t = 3 process newdata process newdata Fault-tolerance with Checkpointing Checkpointing Saves processed offset info to stable storage Saved as JSON for forward-compatibility Allows recovery from any failure Can resume after limited changes to your streaming transformations (e.g. adding new filters to drop corrupted data, etc.) end-to-end exactly-once guarantees write ahead log
- 14. Anatomy of a Streaming Query ETL Raw data from Kafka available as structured data in seconds, ready for querying spark.readStream.format("kafka") .option("kafka.boostrap.servers",...) .option("subscribe", "topic") .load() .selectExpr("cast (value as string) as json") .select(from_json("json", schema).as("data")) .writeStream .format("parquet") .option("path", "/parquetTable/") .trigger("1 minute") .option("checkpointLocation", "…") .start()
- 15. 2xfaster Structured Streaming reuses the Spark SQL Optimizer and Tungsten Engine Performance: Benchmark 40-core throughput 700K 33M 65M 0 10 20 30 40 50 60 70 Kafka Streams Apache Flink Structured Streaming Millionsofrecords/s More details in our blog post cheaper
- 17. What is Stateless Stream Processing? Stateless streaming queries (e.g. ETL) process each record independent of other records df.select(from_json("json", schema).as("data")) .where("data.type = 'typeA') Spark stateless streaming Every record is parsed into a structured form and then selected (or not) by the filter
- 18. What is Stateful Stream Processing? Stateful streaming queries combine information from multiple records together .count() Spark stateful streaming statedf.select(from_json("json", schema).as("data")) .where("data.type = 'typeA') Count is the streaming state and every selected record increments the count State is the information that is maintained for future use statestate
- 19. Stateful Micro-Batch Processing State is versioned between micro-batches while streaming query is running Each micro-batch reads previous version state and updates it to new version Versions used for fault recovery process newdata t = 1 sink src t = 2 process newdata sink src t = 3 process newdata sink src statestatestate micro-batch incremental execution
- 20. Distributed, Fault-tolerant State State data is distributed across executors State stored in the executor memory Micro-batch tasks update the state Changes are checkpointed with version to given checkpoint location (e.g. HDFS) Recovery from failure is automatic Exactly-once fault-tolerance guarantees! executor 2 executor 1 driver state state HDFS tasks
- 22. Automatic State Cleanup User-defined State Cleanup Two types of Stateful Operations
- 23. Automatic State Cleanup User-defined State Cleanup For SQL operations with well- defined semantics State cleanup is automatic with watermarking because we precisely know when state data is not needed any more For user-defined, arbitrary stateful operations No automatic state cleanup User has to explicitly manage state
- 24. Automatic State Cleanup User-defined State Cleanup aggregations deduplications joins streaming sessionization with mapGroupsWithState and flatMapGroupsWithState
- 25. Rest of this talk Explore built-in stateful operations How to use watermarks to control state size How to build arbitrary stateful operations How to monitor and debug stateful queries
- 27. Aggregation by key and/or time windows Aggregation by key only Aggregation by event time windows Aggregation by both Supports multiple aggregations, user-defined functions (UDAFs)! events .groupBy("key") .count() events .groupBy(window("timestamp","10 mins")) .avg("value") events .groupBy( col(key), window("timestamp","10 mins")) .agg(avg("value"), corr("value"))
- 28. Automatically handles Late Data 12:00 - 13:00 1 12:00 - 13:00 3 13:00 - 14:00 1 12:00 - 13:00 3 13:00 - 14:00 2 14:00 - 15:00 5 12:00 - 13:00 5 13:00 - 14:00 2 14:00 - 15:00 5 15:00 - 16:00 4 12:00 - 13:00 3 13:00 - 14:00 2 14:00 - 15:00 6 15:00 - 16:00 4 16:00 - 17:00 3 13:00 14:00 15:00 16:00 17:00Keeping state allows late data to update counts of old windows red = state updated with late data But size of the state increases indefinitely if old windows are not dropped
- 29. Watermarking Watermark - moving threshold of how late data is expected to be and when to drop old state Trails behind max event time seen by the engine Watermark delay = trailing gap event time max event time watermark data older than watermark not expected 12:30 PM 12:20 PM trailing gap of 10 mins
- 30. Watermarking Data newer than watermark may be late, but allowed to aggregate Data older than watermark is "too late" and dropped Windows older than watermark automatically deleted to limit state max event time event time watermark late data allowed to aggregate data too late, dropped watermark delay of 10 mins
- 31. Watermarking max event time event time watermark parsedData .withWatermark("timestamp", "10 minutes") .groupBy(window("timestamp","5 minutes")) .count() late data allowed to aggregate data too late, dropped Used only in stateful operations Ignored in non-stateful streaming queries and batch queries watermark delay of 10 mins
- 32. Watermarking data too late, ignored in counts, state dropped Processing Time12:00 12:05 12:10 12:15 12:10 12:15 12:20 12:07 12:13 12:08 EventTime 12:15 12:18 12:04 watermark updated to 12:14 - 10m = 12:04 for next trigger, state < 12:04 deleted data is late, but considered in counts system tracks max observed event time 12:08 wm = 12:04 10min 12:14 More details in my blog post parsedData .withWatermark("timestamp", "10 minutes") .groupBy(window("timestamp","5 minutes")) .count()
- 33. Watermarking Trade off between lateness tolerance and state size lateness toleranceless late data processed, less memory consumed more late data processed, more memory consumed state size
- 35. Streaming Deduplication Drop duplicate records in a stream Specify columns which uniquely identify a record Spark SQL will store past unique column values as state and drop any record that matches the state userActions .dropDuplicates("uniqueRecordId")
- 36. Streaming Deduplication with Watermark Timestamp as a unique column along with watermark allows old values in state to dropped Records older than watermark delay is not going to get any further duplicates Timestamp must be same for duplicated records userActions .withWatermark("timestamp") .dropDuplicates( "uniqueRecordId", "timestamp")
- 37. Streaming Joins
- 38. Streaming Joins Spark 2.0+ supports joins between streams and static datasets Spark 2.3+ supports joins between multiple streams Join (ad, impression) (ad, click) (ad, impression, click) Join stream of ad impressions with another stream of their corresponding user clicks Example: Ad Monetization
- 39. Streaming Joins Most of the time click events arrive after their impressions Sometimes, due to delays, impressions can arrive after clicks Each stream in a join needs to buffer past events as state for matching with future events of the other stream Join (ad, impression) (ad, click) (ad, impression, click) state state
- 40. Join (ad, impression) (ad, click) (ad, impression, click) Simple Inner Join Inner join by ad ID column Need to buffer all past events as state, a match can come on the other stream any time in the future To allow buffered events to be dropped, query needs to provide more time constraints impressions.join( clicks, expr("clickAdId = impressionAdId") ) state state ∞ ∞
- 41. Inner Join + Time constraints + Watermarks time constraints Time constraints Let's assume Impressions can be 2 hours late Clicks can be 3 hours late A click can occur within 1 hour after the corresponding impression val impressionsWithWatermark = impressions .withWatermark("impressionTime", "2 hours") val clicksWithWatermark = clicks .withWatermark("clickTime", "3 hours") impressionsWithWatermark.join( clicksWithWatermark, expr(""" clickAdId = impressionAdId AND clickTime >= impressionTime AND clickTime <= impressionTime + interval 1 hour """ )) Join Range Join
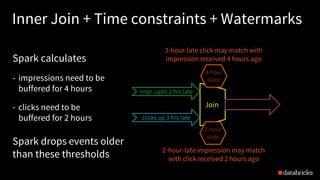
- 42. impressionsWithWatermark.join( clicksWithWatermark, expr(""" clickAdId = impressionAdId AND clickTime >= impressionTime AND clickTime <= impressionTime + interval 1 hour """ )) Inner Join + Time constraints + Watermarks Spark calculates - impressions need to be buffered for 4 hours - clicks need to be buffered for 2 hours Join impr. upto 2 hrs late clicks up 3 hrs late 4-hour state 2-hour state 3-hour-late click may match with impression received 4 hours ago 2-hour-late impression may match with click received 2 hours ago Spark drops events older than these thresholds
- 43. Join Outer Join + Time constraints + Watermarks Left and right outer joins are allowed only with time constraints and watermarks Needed for correctness, Spark must output nulls when an event cannot get any future match Note: null outputs are delayed as Spark has to wait for sometime to be sure that there cannot be any match impressionsWithWatermark.join( clicksWithWatermark, expr(""" clickAdId = impressionAdId AND clickTime >= impressionTime AND clickTime <= impressionTime + interval 1 hour """ ), joinType = "leftOuter" ) Can be "inner" (default) /"leftOuter"/ "rightOuter"
- 45. Arbitrary Stateful Operations Many use cases require more complicated logic than SQL ops Example: Tracking user activity on your product Input: User actions (login, clicks, logout, …) Output: Latest user status (online, active, inactive, …) Solution: MapGroupsWithState General API for per-key user-defined stateful processing Since Spark 2.2, for Scala and Java only MapGroupsWithState / FlatMapGroupsWithState
- 46. No automatic state clean up and dropping of late data Adding watermark does not automatically manage late and state data Explicit state clean up by the user More powerful + efficient than DStream's mapWithState and updateStateByKey MapGroupsWithState / FlatMapGroupsWithState
- 47. MapGroupsWithState - How to use? 1. Define the data structures Input event: UserAction State data: UserStatus Output event: UserStatus (can be different from state) case class UserAction( userId: String, action: String) case class UserStatus( userId: String, active: Boolean) MapGroupsWithState
- 48. MapGroupsWithState - How to use? 2. Define function to update state of each grouping key using the new data Input Grouping key: userId New data: new user actions Previous state: previous status of this user case class UserAction( userId: String, action: String) case class UserStatus( userId: String, active: Boolean) def updateState( userId: String, actions: Iterator[UserAction], state: GroupState[UserStatus]):UserStatus = { }
- 49. MapGroupsWithState - How to use? 2. Define function to update state of each grouping key using the new data Body Get previous user status Update user status with actions Update state with latest user status Return the status def updateState( userId: String, actions: Iterator[UserAction], state: GroupState[UserStatus]):UserStatus = { } val prevStatus = state.getOption.getOrElse { new UserStatus() } actions.foreah { action => prevStatus.updateWith(action) } state.update(prevStatus) return prevStatus
- 50. MapGroupsWithState - How to use? 3. Use the user-defined function on a grouped Dataset Works with both batch and streaming queries In batch query, the function is called only once per group with no prior state def updateState( userId: String, actions: Iterator[UserAction], state: GroupState[UserStatus]):UserStatus = { } // process actions, update and return status userActions .groupByKey(_.userId) .mapGroupsWithState(updateState)
- 51. Timeouts Example: Mark a user as inactive when there is no actions in 1 hour Timeouts: When a group does not get any event for a while, then the function is called for that group with an empty iterator Must specify a global timeout type, and set per-group timeout timestamp/duration Ignored in a batch queries userActions.withWatermark("timestamp") .groupByKey(_.userId) .mapGroupsWithState (timeoutConf)(updateState) EventTime Timeout ProcessingTime Timeout NoTimeout (default)
- 52. userActions .withWatermark("timestamp") .groupByKey(_.userId) .mapGroupsWithState ( timeoutConf )(updateState) Event-time Timeout - How to use? 1. Enable EventTimeTimeout in mapGroupsWithState 2. Enable watermarking 3. Update the mapping function Every time function is called, set the timeout timestamp using the max seen event timestamp + timeout duration Update state when timeout occurs def updateState(...): UserStatus = { if (!state.hasTimedOut) { // track maxActionTimestamp while // processing actions and updating state state.setTimeoutTimestamp( maxActionTimestamp, "1 hour") } else { // handle timeout userStatus.handleTimeout() state.remove() } // return user status } EventTimeTimeout if (!state.hasTimedOut) { } else { // handle timeout userStatus.handleTimeout() state.remove() } return userStatus
- 53. Event-time Timeout - When? Watermark is calculated with max event time across all groups For a specific group, if there is no event till watermark exceeds the timeout timestamp, Then Function is called with an empty iterator, and hasTimedOut = true Else Function is called with new data, and timeout is disabled Needs to explicitly set timeout timestamp every time
- 54. Processing-time Timeout Instead of setting timeout timestamp, function sets timeout duration (in terms of wall-clock-time) to wait before timing out Independent of watermarks Note, query downtimes will cause lots of timeouts after recovery def updateState(...): UserStatus = { if (!state.hasTimedOut) { // handle new data state.setTimeoutDuration("1 hour") } else { // handle timeout } return userStatus } userActions .groupByKey(_.userId) .mapGroupsWithState (ProcessingTimeTimeout)(updateState)
- 55. FlatMapGroupsWithState More general version where the function can return any number of events, possibly none at all Example: instead of returning user status, want to return specific actions that are significant based on the history def updateState( userId: String, actions: Iterator[UserAction], state: GroupState[UserStatus]): Iterator[SpecialUserAction] = { } userActions .groupByKey(_.userId) .flatMapGroupsWithState (outputMode, timeoutConf) (updateState)
- 56. userActions .groupByKey(_.userId) .flatMapGroupsWithState (outputMode, timeoutConf) (updateState) Function Output Mode Function output mode* gives Spark insights into the output from this opaque function Update Mode - Output events are key-value pairs, each output is updating the value of a key in the result table Append Mode - Output events are independent rows that being appended to the result table Allows Spark SQL planner to correctly compose flatMapGroupsWithState with other operations *Not to be confused with output mode of the query Update Mode Append Mode
- 58. Optimizing Query State Set # shuffle partitions to 1-3 times number of cores Too low = not all cores will be used à lower throughput Too high = cost of writing state to HDFS will increases à higher latency Total size of state per worker Larger state leads to higher overheads of snapshotting, JVM GC pauses, etc.
- 59. Monitoring the state of Query State Get current state metrics using the last progress of the query Total number of rows in state Total memory consumed (approx.) Get it asynchronously through StreamingQueryListener API val progress = query.lastProgress print(progress.json) { ... "stateOperators" : [ { "numRowsTotal" : 660000, "memoryUsedBytes" : 120571087 ... } ], } new StreamingQueryListener { ... def onQueryProgress( event: QueryProgressEvent) }
- 60. Monitoring the state of Query State Databricks Notebooks integrated with Structured Streaming Shows size of state along with other processing metrics Data rates Batch durations # state keys
- 61. Debugging Query State SQL metrics in the Spark UI (SQL tab, DAG view) expose more operator-specific stats Answer questions like - Is the memory usage skewed? - Is removing rows slow? - Is writing checkpoints slow?
- 62. Managing Very Large State State data kept on JVM heap Can have GC issues with millions of state keys per worker Limits depend on the size and complexity of state data structures Latency spikes of > 20s due to GC
- 63. Managing Very Large Statewith RocksDB In Databricks Runtime, you can store state locally in RocksDB Avoids JVM heap, no GC issues with 100 millions state keys per worker Local RocksDB snapshot files automatically checkpointed to HDFS Same exactly-once fault-tolerant guarantees Latency capped at 10s [More info in Databricks Docs]
- 64. Continuous Processing Millisecond-level latencies with Continuous Processing engine Experimental release in Apache Spark 2.3 Shuffle and stateful operator support coming in future releases More info: Talk today! Blog post
- 65. More Info Structured Streaming Docs http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html https://docs.databricks.com/spark/latest/structured-streaming/index.html Databricks blog posts for more focused discussions https://databricks.com/blog/category/engineering/streaming My previous talk on the basics of Structured Streaming https://www.slideshare.net/databricks/a-deep-dive-into-structured-streaming
- 66. Questions? Office hours today at 2:00 PM at Databricks Booth
- 67. UNIFIED ANALYTICS PLATFORM Try Apache Spark in Databricks! • Collaborative cloud environment • Free version (community edition) DATABRICKS RUNTIME 3.0 • Apache Spark - optimized for the cloud • Caching and optimization layer - DBIO • Enterprise security - DBES Try for free today databricks.com