A Fast Intro to Fast Query with ClickHouse, by Robert Hodges
3 likes4,212 views

The document introduces ClickHouse, a fast, scalable data warehouse solution that excels in handling large datasets with low operating costs and high performance. It highlights its capabilities in real-time data analytics, SQL compatibility, and efficient management of massive data pools with practical examples on setup, data loading, and query execution. ClickHouse aims to meet the demands of modern applications while overcoming limitations of legacy data warehousing solutions.























A Fast Intro to Fast Query with ClickHouse, by Robert Hodges
- 1. A Fast Intro to Fast Query with ClickHouse Robert Hodges, Altinity CEO
- 2. Altinity Background ● Premier provider of software and services for ClickHouse ● Incorporated in UK with distributed team in US/Canada/Europe ● Main US/Europe sponsor of ClickHouse community ● Offerings: ○ Enterprise support for ClickHouse and ecosystem projects ○ Software (Kubernetes, cluster manager, tools & utilities) ○ POCs/Training
- 3. The shape of data has changed Business insights are hidden in massive pools of automatically collected information
- 4. Applications that rule the digital era have a common success factor The ability to discover and apply business-critical insights from petabyte datasets in real time
- 5. Let’s consider a concrete example Web properties track clickstreams to: ● Calculate clickthrough/buy rates ● Guide ad placement ● Optimize eCommerce services Constraints: ● Run on commodity hardware ● Simple to operate ● Fast interactive query ● Avoid encumbering licenses
- 6. Existing analytic databases do not meet requirements fully Cloud-native data warehouses cannot operate on-prem, limiting range of solutions Legacy SQL databases are expensive to run, scale poorly on commodity hardware, and adapt slowly Hadoop/Spark ecosystem solutions are resource intensive with slow response and complex pipelines Specialized solutions limit query domain and are complex/ resource-inefficient for general use
- 7. ClickHouse fills the gaps and does much more besides Understands SQL Runs on bare metal to cloud Stores data in columns Parallel and vectorized execution Scales to many petabytes Is Open source (Apache 2.0) Is WAY fast! Id a b c d Id a b c d Id a b c d Id a b c d
- 8. What does “WAY fast” mean? SELECT Dest d, count(*) c, avg(ArrDelayMinutes) ad FROM ontime GROUP BY d HAVING c > 100000 ORDER BY ad DESC limit 5 ┌─d───┬───────c─┬─────────────────ad─┐ │ EWR │ 3660570 │ 17.637564095209218 │ │ SFO │ 4056003 │ 16.029478528492213 │ │ JFK │ 2198078 │ 15.33669824273752 │ │ LGA │ 3133582 │ 14.533851994299177 │ │ ORD │ 9108159 │ 14.431460737565077 │ └─────┴─────────┴────────────────────┘ 5 rows in set. Elapsed: 1.182 sec. Processed 173.82 million rows, 2.78 GB (147.02 million rows/s., 2.35 GB/s.) (Amazon md5.2xlarge: Xeon(R) Platinum 8175M, 8vCPU, 30GB RAM, NVMe SSD)
- 9. What are the main ClickHouse use patterns? ● Fast, scalable data warehouse for online services (SaaS and in-house apps) ● Built-in data warehouse for installed analytic applications ● Exploration -- throw in a bunch of data and go crazy!
- 10. Getting started is easy with Docker image $ docker run -d --name ch-s yandex/clickhouse-server $ docker exec -it ch-s clickhouse client ... 11e99303c78e :) select version() SELECT version() ┌─version()─┐ │ 19.3.3 │ └───────────┘ 1 rows in set. Elapsed: 0.001 sec.
- 11. Or install recommended Altinity stable version packages $ sudo apt -y install clickhouse-client=18.16.1 clickhouse-server=18.16.1 clickhouse-common-static=18.16.1 ... $ sudo systemctl start clickhouse-server ... 11e99303c78e :) select version() SELECT version() ┌─version()─┐ │ 18.16.1 │ └───────────┘ 1 rows in set. Elapsed: 0.001 sec.
- 12. Examples of table creation and data insertion CREATE TABLE sdata ( DevId Int32, Type String, MDate Date, MDatetime DateTime, Value Float64 ) ENGINE = MergeTree() PARTITION BY toYYYYMM(MDate) ORDER BY (DevId, MDatetime) INSERT INTO sdata VALUES (15, 'TEMP', '2018-01-01', '2018-01-01 23:29:55', 18.0), (15, 'TEMP', '2018-01-01', '2018-01-01 23:30:56', 18.7) INSERT INTO sdata VALUES (15, 'TEMP', '2018-01-01', '2018-01-01 23:31:53', 18.1), (2, 'TEMP', '2018-01-01', '2018-01-01 23:31:55', 7.9)
- 13. Loading data from CSV files cat > sdata.csv <<END DevId,Type,MDate,MDatetime,Value 59,"TEMP","2018-02-01","2018-02-01 01:10:13",19.5 59,"TEMP","2018-02-01","2018-02-01 02:10:01",18.8 59,"TEMP","2018-02-01","2018-02-01 03:09:58",18.6 59,"TEMP","2018-02-01","2018-02-01 04:10:05",15.1 59,"TEMP","2018-02-01","2018-02-01 05:10:31",12.2 59,"TEMP","2018-02-01","2018-02-01 06:10:02",11.8 59,"TEMP","2018-02-01","2018-02-01 07:09:55",10.9 END cat sdata.csv |clickhouse-client --database foo --query='INSERT INTO sdata FORMAT CSVWithNames'
- 14. Select results can be surprising! SELECT * FROM sdata WHERE DevId < 20 ┌─DevId─┬─Type─┬──────MDate─┬───────────MDatetime─┬─Value─┐ │ 15 │ TEMP │ 2018-01-01 │ 2018-01-01 23:29:55 │ 18 │ │ 15 │ TEMP │ 2018-01-01 │ 2018-01-01 23:30:56 │ 18.7 │ └───────┴──────┴────────────┴─────────────────────┴───────┘ ┌─DevId─┬─Type─┬──────MDate─┬───────────MDatetime─┬─Value─┐ │ 2 │ TEMP │ 2018-01-01 │ 2018-01-01 23:31:55 │ 7.9 │ │ 15 │ TEMP │ 2018-01-01 │ 2018-01-01 23:31:53 │ 18.1 │ └───────┴──────┴────────────┴─────────────────────┴───────┘ ┌─DevId─┬─Type─┬──────MDate─┬───────────MDatetime─┬─Value─┐ │ 2 │ TEMP │ 2018-01-01 │ 2018-01-01 23:31:55 │ 7.9 │ │ 15 │ TEMP │ 2018-01-01 │ 2018-01-01 23:29:55 │ 18 │ │ 15 │ TEMP │ 2018-01-01 │ 2018-01-01 23:30:56 │ 18.7 │ │ 15 │ TEMP │ 2018-01-01 │ 2018-01-01 23:31:53 │ 18.1 │ └───────┴──────┴────────────┴─────────────────────┴───────┘ Result right after INSERT: Result somewhat later:
- 15. Time for some research into table engines CREATE TABLE sdata ( DevId Int32, Type String, MDate Date, MDatetime DateTime, Value Float64 ) ENGINE = MergeTree() PARTITION BY toYYYYMM(MDate) ORDER BY (DevId, MDatetime) How to manage data and handle queries How to break table into parts How to index and sort data in each part
- 16. MergeTree writes parts quickly and merges them offline /var/lib/clickhouse/data/default/sdata 201801_1_1_0/ 201801_2_2_0/ Multiple parts after initial insertion ( => very fast writes) 201801_1_2_1/ Single part after merge ( => very fast reads)
- 17. Rows are indexed and sorted inside each part /var/lib/clickhouse/data/default/sdata ... ... 956 2018-01-01 15:22:37 575 2018-01-01 23:31:53 1300 2018-01-02 05:14:47 ... ... primary.idx |||| .mrk .bin |||| .mrk .bin |||| .mrk .bin |||| .mrk .bin 201802_1_1_0/ (DevId, MDateTime) DevId Type MDate MDatetime... primary.idx .mrk .bin .mrk .bin .mrk .bin .mrk .bin 201801_1_2_1/ (DevId, MDateTime) DevId Type MDate MDatetime...
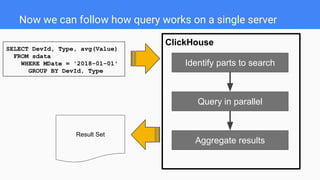
- 18. ClickHouse Now we can follow how query works on a single server SELECT DevId, Type, avg(Value) FROM sdata WHERE MDate = '2018-01-01' GROUP BY DevId, Type Identify parts to search Query in parallel Aggregate results Result Set
- 19. Clickhouse distributed engine spreads queries across shards SELECT ... FROM sdata_dist ClickHouse sdata_dist (Distributed) sdata (MergeTable) ClickHouse sdata_dist sdata ClickHouse sdata_dist sdata Result Set
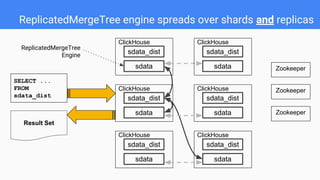
- 20. ReplicatedMergeTree engine spreads over shards and replicas ClickHouse sdata_dist sdata ReplicatedMergeTree Engine ClickHouse sdata_dist sdata ClickHouse sdata_dist sdata ClickHouse sdata_dist sdata ClickHouse sdata_dist sdata ClickHouse sdata_dist sdata SELECT ... FROM sdata_dist Result Set Zookeeper Zookeeper Zookeeper
- 21. SELECT Dest, count(*) c, avg(DepDelayMinutes) FROM ontime GROUP BY Dest HAVING c > 100000 ORDER BY c DESC limit 5 SELECT Dest, count(*) c, avg(DepDelayMinutes) FROM ontime WHERE toYear(FlightDate) = toYear(toDate('2016-01-01')) GROUP BY Dest HAVING c > 100000 ORDER BY c DESC limit 5 With basic engine knowledge you can now tune queries Scans 355 table parts in parallel; does not use index Scans 12 parts (3% of data) because FlightDate is partition key Hint: clickhouse-server.log has the query plan Faster
- 22. SELECT Dest d, Name n, count(*) c, avg(ArrDelayMinutes) FROM ontime JOIN airports ON (airports.IATA = ontime.Dest) GROUP BY d, n HAVING c > 100000 ORDER BY ad DESC SELECT dest, Name n, c AS flights, ad FROM ( SELECT Dest dest, count(*) c, avg(ArrDelayMinutes) ad FROM ontime GROUP BY dest HAVING c > 100000 ORDER BY ad DESC ) LEFT JOIN airports ON airports.IATA = dest You can also optimize joins Subquery minimizes data scanned in parallel; joins on GROUP BY results Joins on data before GROUP BY, increased amount to scan Faster
- 23. ClickHouse has a wealth of features to help queries go fast Dictionaries Materialized Views Arrays Specialized functions and SQL extensions Lots more table engines
- 24. ...And a nice set of supporting ecosystem tools Client libraries: JDBC, ODBC, Python, Golang, ... Kafka table engine to ingest from Kafka queues Visualization tools: Grafana, Tableau, Tabix, SuperSet Data science stack integration: Pandas, Jupyter Notebooks Kubernetes ClickHouse operator
- 25. Where to get more information ● ClickHouse Docs: https://clickhouse.yandex/docs/en/ ● Altinity Blog: https://www.altinity.com/blog ● Meetups and conference presentations ○ 2 April -- Madrid, Spain ClickHouse Meetup ○ 28-30 May -- Austin, TX Percona Live 2019 ○ San Francisco ClickHouse Meetup
- 26. Questions? Thank you! Contacts: [email protected] Visit us at: https://www.altinity.com Read Our Blog: https://www.altinity.com/blog