A really really fast introduction to PySpark - lightning fast cluster computing with python
34 likes22,814 views

The document provides an overview of PySpark, including its setup, functionality, and key components, such as RDDs (Resilient Distributed Datasets) and DataFrames. It explains how to perform operations like word count using PySpark's APIs, and discusses concepts like transformations, actions, and lazy evaluation. Additionally, it highlights resources for further learning and suggests community events related to Apache Spark.







![Starting the shell
./bin/pyspark
[Lots of output]
SparkContext available as sc, SQLContext available as
sqlContext.
>>>](https://image.slidesharecdn.com/areallyreallyfastintroductiontopyspark-lightningfastclustercomputingwithpython1-150725040347-lva1-app6892/85/A-really-really-fast-introduction-to-PySpark-lightning-fast-cluster-computing-with-python-8-320.jpg)


![Sparkcontext: entry to the world
● Can be used to create RDDs from many input sources
○ Native collections, local & remote FS
○ Any Hadoop Data Source
● Also create counters & accumulators
● Automatically created in the shells (called sc)
● Specify master & app name when creating
○ Master can be local[*], spark:// , yarn, etc.
○ app name should be human readable and make sense
● etc.](https://image.slidesharecdn.com/areallyreallyfastintroductiontopyspark-lightningfastclustercomputingwithpython1-150725040347-lva1-app6892/85/A-really-really-fast-introduction-to-PySpark-lightning-fast-cluster-computing-with-python-11-320.jpg)






![Lets find the lines with the word “Spark”
import os
src = "file:///"+os.environ['SPARK_HOME']+"/README.md"
lines = sc.textFile(src)](https://image.slidesharecdn.com/areallyreallyfastintroductiontopyspark-lightningfastclustercomputingwithpython1-150725040347-lva1-app6892/85/A-really-really-fast-introduction-to-PySpark-lightning-fast-cluster-computing-with-python-18-320.jpg)



![lets use toDebugString
un-cached:
>>> print word_count.toDebugString()
(2) PythonRDD[17] at RDD at PythonRDD.scala:43 []
| MapPartitionsRDD[14] at mapPartitions at PythonRDD.scala:346 []
| ShuffledRDD[13] at partitionBy at NativeMethodAccessorImpl.java:-2 []
+-(2) PairwiseRDD[12] at reduceByKey at <stdin>:3 []
| PythonRDD[11] at reduceByKey at <stdin>:3 []
| MapPartitionsRDD[10] at textFile at NativeMethodAccessorImpl.java:-2 []
| file:////home/holden/repos/spark/README.md HadoopRDD[9] at textFile at NativeMethodAccessorImpl.java:-2 []](https://image.slidesharecdn.com/areallyreallyfastintroductiontopyspark-lightningfastclustercomputingwithpython1-150725040347-lva1-app6892/85/A-really-really-fast-introduction-to-PySpark-lightning-fast-cluster-computing-with-python-22-320.jpg)
![lets use toDebugString
cached:
>>> print word_count.toDebugString()
(2) PythonRDD[8] at RDD at PythonRDD.scala:43 []
| MapPartitionsRDD[5] at mapPartitions at PythonRDD.scala:346 []
| ShuffledRDD[4] at partitionBy at NativeMethodAccessorImpl.java:-2 []
+-(2) PairwiseRDD[3] at reduceByKey at <stdin>:3 []
| PythonRDD[2] at reduceByKey at <stdin>:3 []
| MapPartitionsRDD[1] at textFile at NativeMethodAccessorImpl.java:-2 []
| CachedPartitions: 2; MemorySize: 2.7 KB; ExternalBlockStoreSize: 0.0 B; DiskSize: 0.0 B
| file:////home/holden/repos/spark/README.md HadoopRDD[0] at textFile at NativeMethodAccessorImpl.java:-2 []](https://image.slidesharecdn.com/areallyreallyfastintroductiontopyspark-lightningfastclustercomputingwithpython1-150725040347-lva1-app6892/85/A-really-really-fast-introduction-to-PySpark-lightning-fast-cluster-computing-with-python-23-320.jpg)















![import urllib2
data = urllib2.urlopen('https://raw.githubusercontent.
com/databricks/learning-spark/master/files/testweet.json').
read()
print data
rdd = sc.parallelize([data])
path = "mytextFile.txt"
rdd.saveAsTextFile(path)](https://image.slidesharecdn.com/areallyreallyfastintroductiontopyspark-lightningfastclustercomputingwithpython1-150725040347-lva1-app6892/85/A-really-really-fast-introduction-to-PySpark-lightning-fast-cluster-computing-with-python-42-320.jpg)






A really really fast introduction to PySpark - lightning fast cluster computing with python
- 1. PySpark Lightning fast cluster computing with Python
- 2. Who am I? Holden ● I prefer she/her for pronouns ● Co-author of the Learning Spark book ● @holdenkarau ● http://www.slideshare.net/hkarau ● https://www.linkedin.com/in/holdenkarau
- 3. What we are going to explore together! ● What is Spark? ● Getting Spark setup locally OR getting access to cluster ● Spark primary distributed collection ● Word count ● How PySpark works ● Using libraries with Spark ● Spark SQL / DataFrames
- 4. What is Spark? ● General purpose distributed system ○ With a really nice API ● Apache project (one of the most active) ● Must faster than Hadoop Map/Reduce
- 5. The different pieces of Spark Apache Spark SQL & DataFrames Streaming Language APIs Scala, Java, Python, & R Graph Tools Spark ML bagel & Grah X MLLib Community Packages
- 6. Setup time! Remote Azure HDI cluster: http://bit.ly/clusterSignup (thanks Microsoft!) We can use Jupyter :) Local Machine: If you don’t have Spark installed you can get it from http: //spark.apache.org/downloads.html (select 1.3.1, any hadoop version)
- 7. Some pages to keep open for the exercises http://bit.ly/sparkDocs http://bit.ly/sparkPyDocs http://bit.ly/PySparkIntroExamples http://bit.ly/learningSparkExamples OR http://spark.apache.org/docs/latest/api/python/index.html http://spark.apache.org/docs/latest/ https://github.com/holdenk/intro-to-pyspark-demos
- 8. Starting the shell ./bin/pyspark [Lots of output] SparkContext available as sc, SQLContext available as sqlContext. >>>
- 9. Reducing log level cp ./conf/log4j.properties.template ./conf/log4j.properties Then set log4j.rootCategory=ERROR, console
- 10. Connecting to your Azure cluster ● Don’t screw up the password (gets cached) ● Use the Jupyter link ● Optionally you can configure your cluster to assign more executor cores to Jupyter
- 11. Sparkcontext: entry to the world ● Can be used to create RDDs from many input sources ○ Native collections, local & remote FS ○ Any Hadoop Data Source ● Also create counters & accumulators ● Automatically created in the shells (called sc) ● Specify master & app name when creating ○ Master can be local[*], spark:// , yarn, etc. ○ app name should be human readable and make sense ● etc.
- 12. Getting the Spark Context on Azure from pyspark import SparkContext from pyspark.sql.types import * sc = SparkContext( 'spark://headnodehost:7077', 'pyspark')
- 13. RDDs: Spark’s Primary abstraction RDD (Resilient Distributed Dataset) ● Recomputed on node failure ● Distributed across the cluster ● Lazily evaluated (transformations & actions)
- 14. Word count lines = sc.textFile(src) words = lines.flatMap(lambda x: x.split(" ")) word_count = (words.map(lambda x: (x, 1)) .reduceByKey(lambda x, y: x+y)) word_count.saveAsTextFile(output)
- 15. Word count lines = sc.textFile(src) words = lines.flatMap(lambda x: x.split(" ")) word_count = (words.map(lambda x: (x, 1)) .reduceByKey(lambda x, y: x+y)) word_count.saveAsTextFile(output) No data is read or processed until after this line This is an “action” which forces spark to evaluate the RDD
- 16. Some common transformations & actions Transformations (lazy) ● map ● filter ● flatMap ● reduceByKey ● join ● cogroup Actions (eager) ● count ● reduce ● collect ● take ● saveAsTextFile ● saveAsHadoop ● countByValue Photo by Steve Photo by Dan G
- 17. Exercise time Photo by recastle
- 18. Lets find the lines with the word “Spark” import os src = "file:///"+os.environ['SPARK_HOME']+"/README.md" lines = sc.textFile(src)
- 19. What did you find?
- 20. A solution: lines = sc.textFile(src) spark_lines = lines.filter( lambda x: x.lower().find("spark") != -1) print spark_lines.count()
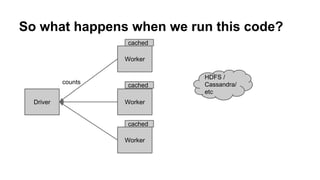
- 21. Combined with previous example Do you notice anything funky? ● We read the data in twice :( ● cache/persist/checkpoint to the rescue!
- 22. lets use toDebugString un-cached: >>> print word_count.toDebugString() (2) PythonRDD[17] at RDD at PythonRDD.scala:43 [] | MapPartitionsRDD[14] at mapPartitions at PythonRDD.scala:346 [] | ShuffledRDD[13] at partitionBy at NativeMethodAccessorImpl.java:-2 [] +-(2) PairwiseRDD[12] at reduceByKey at <stdin>:3 [] | PythonRDD[11] at reduceByKey at <stdin>:3 [] | MapPartitionsRDD[10] at textFile at NativeMethodAccessorImpl.java:-2 [] | file:////home/holden/repos/spark/README.md HadoopRDD[9] at textFile at NativeMethodAccessorImpl.java:-2 []
- 23. lets use toDebugString cached: >>> print word_count.toDebugString() (2) PythonRDD[8] at RDD at PythonRDD.scala:43 [] | MapPartitionsRDD[5] at mapPartitions at PythonRDD.scala:346 [] | ShuffledRDD[4] at partitionBy at NativeMethodAccessorImpl.java:-2 [] +-(2) PairwiseRDD[3] at reduceByKey at <stdin>:3 [] | PythonRDD[2] at reduceByKey at <stdin>:3 [] | MapPartitionsRDD[1] at textFile at NativeMethodAccessorImpl.java:-2 [] | CachedPartitions: 2; MemorySize: 2.7 KB; ExternalBlockStoreSize: 0.0 B; DiskSize: 0.0 B | file:////home/holden/repos/spark/README.md HadoopRDD[0] at textFile at NativeMethodAccessorImpl.java:-2 []
- 24. A detour into the internals Photo by Bill Ward
- 25. Why lazy evaluation? ● Allows pipelining procedures ○ Less passes over our data, extra happiness ● Can skip materializing intermediate results which are really really big* ● Figuring out where our code fails becomes a little trickier
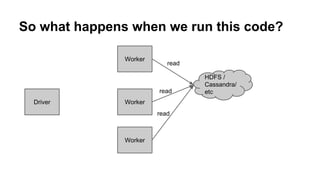
- 26. So what happens when we run this code? Driver Worker Worker Worker HDFS / Cassandra/ etc
- 27. So what happens when we run this code? Driver Worker Worker Worker HDFS / Cassandra/ etc function
- 28. So what happens when we run this code? Driver Worker Worker Worker HDFS / Cassandra/ etc read read read
- 29. So what happens when we run this code? Driver Worker Worker Worker HDFS / Cassandra/ etc cached cached cached counts
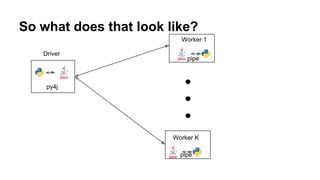
- 30. Spark in Scala, how does PySpark work? ● Py4J + pickling + magic ○ This can be kind of slow sometimes ● RDDs are generally RDDs of pickled objects ● Spark SQL (and DataFrames) avoid some of this
- 31. So what does that look like? Driver py4j Worker 1 Worker K pipe pipe
- 32. Using other libraries ● built ins ○ just import!* ■ Except for Hive, compile with -PHive & then import ● spark-packages ○ --packages ● generic python ○ pre-install on workers (pssh, puppet, etc.) ○ add it with --zip-files ○ sc.addPyFile
- 33. So lets take “DataFrames” out for a spin ● useful for structured data ● support schema inference on JSON ● Many operations done without* pickling ● Integrated into ML! ● Accessed through SQLContext ● Not the same feature set as Panda’s or R DataFrames
- 34. Loading data df = sqlContext.read.load( "files/testweet.json", format="json") # Built in json, parquet, etc. # More formats (csv, etc.) at http://spark-packages.org/
- 35. DataFrames aren’t quite as lazy... ● Keep track of schema information ● Loading JSON data involves looking at the data ● Before if we tried to load non-existent data wouldn’t fail right away, now fails right away
- 36. Examining Schema Information root |-- contributorsIDs: array (nullable = true) | |-- element: string (containsNull = true) |-- createdAt: string (nullable = true) |-- currentUserRetweetId: long (nullable = true) |-- hashtagEntities: array (nullable = true) | |-- element: string (containsNull = true) |-- id: long (nullable = true) |-- inReplyToStatusId: long (nullable = true) |-- inReplyToUserId: long (nullable = true) |-- isFavorited: boolean (nullable = true) |-- isPossiblySensitive: boolean (nullable = true) |-- isTruncated: boolean (nullable = true)
- 37. Manipulating DataFrames SQL df.registerTempTable("panda") sqlContext.sql("select * from panda where id = 529799371026485248") API df.filter(df.id == 529799371026485248)
- 38. DataFrames to RDD’s & vice versa ● map lets us work per-row df.map(lambda row: row.text) ● Converting back ○ infer_schema ○ specify the schema
- 39. Or we can make a UDF def function(x): # Some magic sqlContext.registerFunction(“name”, function, IntegerType())
- 40. More exercise funtimes :) ● Lets load a sample tweet ● Write a UDF to compute the length of the tweet ● Select the length of the tweet
- 41. Getting some tweets ● Could use Spark Streaming sample app if you have twitter keys handy ● Normally we would read data from HDFS or similar
- 42. import urllib2 data = urllib2.urlopen('https://raw.githubusercontent. com/databricks/learning-spark/master/files/testweet.json'). read() print data rdd = sc.parallelize([data]) path = "mytextFile.txt" rdd.saveAsTextFile(path)
- 43. Loading the tweets df = sqlContext.jsonFile(path) df.printSchema()
- 44. MLLib / ML ● Example in the notebook :)
- 45. Additional Resources ● Programming guide (along with JavaDoc, PyDoc, ScalaDoc, etc.) ○ http://spark.apache.org/docs/latest/ ● Books ● Videos ● Training ● My talk tomorrow
- 46. Learning Spark Fast Data Processing with Spark (Out of Date) Fast Data Processing with Spark Advanced Analytics with Spark Coming soon: Spark in Action
- 47. Conferences & Meetups ● Strata & Hadoop World (next one in NYC) ● Spark summit (next one in Amsterdam) ● Seattle Spark Meetup (next event on Aug 12th) & more at http://spark.apache.org/community.html#events
- 48. Spark Videos ● Apache Spark Youtube Channel ● Spark Summit 2014 training ● Paco’s Introduction to Apache Spark
Editor's Notes
- #15: We can examine how RDD’s work in practice with the traditonal word count example. If you’ve taken another intro to big data class, or just worked with mapreduce you’ll notice that this is a lot less code than we normally have to do.
- #17: Panda https://www.flickr.com/photos/dannydansoy/14796219847/in/photolist-oxuuEK-djGVsL-Kmi1i-pCUSTG-pAUejE-4h3psP-9wnBzL-pmrVmA-nUPi4J-qudhKM-b6u5p2-4h7snY-oCFDwT-bnjuJu-8WJYBp-4i5rpo-2pthZD-6Wu6v4-9oheF6-sSXVqV-oVbEDV-eEWMcU-rW9sfP-cdHrWU-sdh3CZ-rW9u74-4zfj1L-6WyaeN-jq9H83-uBFLAY-djGJHE-7dhK6i-63xb5p-ismea-qudjDg-4kuBWy-7bR7bZ-srti4t-dtVySZ-aqMyvB-aT8y1n-eEWKkm-4eFZ8m-7szpy-rm3uJZ-iDGvfm-6Wy4i3-apHzX2-9117E-pAUhf9 Beaver: https://www.flickr.com/photos/sherseydc/2452702213/in/photolist-4JJJVc-dJ18wN-6YKwzR-uQSFpe-9jtjwr-k5yLMP-uQpxHo-i5Z62d-cDDf9w-evkSg-oA75Df-sCodZ3-jY12zC-aJ4WG-p9fnWX-a3WZMo-a1c6W2-efymRX-rywhN-a55i3T-mJSB5T-qSa1rU-5Hbwjz-axeSeC-n5s6QM-cDDeNs-uQpAJ3-mH1fkx-dHUF3X-5wVXSn-cgqjXw-br2MdK-bqZaE8-qaiwrY-faxrfo-7LRKFS-k5ADU7-6cUj1e-cgqkNN-4Cc1n6-8H2ihf-4oxEob-4oxDLQ-8Kp1KK-uNybAm-9ZZSSG-qr5KyY-qrhZuZ-rnX1j2-54uh5d
- #18: https://www.flickr.com/photos/18521020@N04/16907107492/in/photolist-rL2m2j-rtFs9c-rL3wXp-qPmbtK-rtxMko-rHR5BY-rty5Pb-rL3Egn-rtFLbV-qP8Qo9-rL2nXd-rL8NLc-rtzgBy-rty1qb-rL3wUt-rL3G8P-qP8XUS-rtz6cA-rtxX5o-rL2eXq-rHRbWw-rtFJgn-rL8NnX-rL3vHk-rL2ex7-rrPb4F-qP8Vn7-rL3BHB-rtz3xN-qP8YY5-rrPgoZ-rL2cCq-qPmc7t-6Cs4Z9-4PpUzz-rL3KCz-rL3HE6-rHQYhy-rtFzPT-rrP6q2-rtxSAy-rrPj3g-rHQVD7-rtzhD3-rL3zMH-rtzb1U-rtxT6w-rL2vH3-rL8G9V-rrPd6g backup https://www.flickr.com/photos/18521020@N04/16908361265/in/photolist-rL8LJ6-rHR4QN-rrPnzg-rL2nHA-qPkVBF-rL2m2j-rtFs9c-rL3wXp-qPmbtK-rtxMko-rHR5BY-rty5Pb-rL3Egn-rtFLbV-qP8Qo9-rL2nXd-rL8NLc-rtzgBy-rty1qb-rL3wUt-rL3G8P-qP8XUS-rtz6cA-rtxX5o-rL2eXq-rHRbWw-rtFJgn-rL8NnX-rL3vHk-rL2ex7-rrPb4F-qP8Vn7-rL3BHB-rtz3xN-qP8YY5-rrPgoZ-rL2cCq-qPmc7t-6Cs4Z9-4PpUzz-rL3KCz-rL3HE6-rHQYhy-rtFzPT-rrP6q2-rtxSAy-rrPj3g-rHQVD7-rtzhD3-rL3zMH
- #20: Should be ~28 (unless running a different version of Spark)
- #25: https://www.flickr.com/photos/billward/508211284/in/photolist-87LCUa-87PQ6A-87LC44-87PPWs-87LD54-87PPDo-87LBY2-87LCqB-87LBD6-87LCWH-87PQML-87LCRT-7GYBRK-6ZhCV4-bEjtfp-qVRG3a-7gcxPZ-3zxGY6-9Un3j4-f3mrBZ-thSTC9-e214LM-dEDTg3-7TqRQU-7TqRNN-e26FZb-6sjCuP-86656v-7H3xJd-dovrrt-7H3ycb-91otqR-4uiXe5-4ueUy2-7H3y4J-LUHvw-LUS7x-7GYCor-7GYCa8-7H3x7A-7GYCjk-7H3xCh-7GYCMV-dUuL8X-dUAnK7-dUuLut-dUAnU5-dUAnAA-dUAofC-dUAneN