Accelerating Spark MLlib and DataFrame with Vector Processor “SX-Aurora TSUBASA”
1 like731 views

NEC has developed a new vector processor called SX-Aurora TSUBASA to accelerate machine learning and data analytics workloads. They developed a middleware framework called Frovedis that provides Spark-like functionality and is optimized for SX-Aurora TSUBASA. Frovedis achieved 10-100x speedups on machine learning algorithms and SQL-like queries compared to Spark on CPUs. NEC has also opened a lab called VEDAC for external users to access SX-Aurora TSUBASA systems running Frovedis.











![14 © NEC Corporation 201914
Complete Sample Program (1/2)
▌Scatter a vector; double each element; then gather
▌Do not have to be aware of MPI (SPMD programming style)
Looks more like a sequential program
#include <frovedis.hpp>
using namespace frovedis;
int two_times(int i) {return i*2;}
int main(int argc, char* argv[]) {
use_frovedis use(argc, argv);
std::vector<int> v = {1,2,3,4,5,6,7,8};
dvector<int> d1 = make_dvector_scatter(v);
dvector<int> d2 = d1.map(two_times);
std::vector<int> r = d2.gather();
}
initialization
scatter to
create dvector
gather to
std::vector](https://image.slidesharecdn.com/052020takeohosomitakuyaaraki-190508190425/85/Accelerating-Spark-MLlib-and-DataFrame-with-Vector-Processor-SX-Aurora-TSUBASA-14-320.jpg)
![15 © NEC Corporation 201915
Complete Sample Program (2/2)
▌Works as an MPI program
#include <frovedis.hpp>
using namespace frovedis;
int two_times(int i) {return i*2;}
int main(int argc, char* argv[]) {
use_frovedis use(argc, argv);
std::vector<int> v = {1,2,3,4,5,6,7,8};
dvector<int> d1 = make_dvector_scatter(v);
dvector<int> d2 = d1.map(two_times);
std::vector<int> r = d2.gather();
}
MPI_Init is called in the constructor, then branch:
• rank 0: execute the below statements
• rank 1-N: wait for RPC request from rank 0
rank 0 sends RPC request to
rank 1-N to do the work
in the destructor of “use”, MPI_Finalize is called and
send RPC request to rank 1-N to stop the program](https://image.slidesharecdn.com/052020takeohosomitakuyaaraki-190508190425/85/Accelerating-Spark-MLlib-and-DataFrame-with-Vector-Processor-SX-Aurora-TSUBASA-15-320.jpg)
![16 © NEC Corporation 201916
Matrix Library
▌Implemented using Frovedis core and existing MPI libraries[*]
[*] ScaLAPACK/PBLAS, LAPACK/BLAS, Parallel ARPACK
▌Supports dense and sparse matrix of various formats
Dense: row-major, column-major, block-cyclic
Sparse: CRS, CCS, ELL, JDS, JDS/CRS Hybrid (for better vectorization)
▌Provides basic matrix operations and linear algebra
Dense: matrix multiply, solve, transpose, etc.
Sparse: matrix-vector multiply (SpMV), transpose, etc.
blockcyclic_matrix<double> A = X * Y; // mat mul
gesv(A, b); // solve Ax = b
Example](https://image.slidesharecdn.com/052020takeohosomitakuyaaraki-190508190425/85/Accelerating-Spark-MLlib-and-DataFrame-with-Vector-Processor-SX-Aurora-TSUBASA-16-320.jpg)













Accelerating Spark MLlib and DataFrame with Vector Processor “SX-Aurora TSUBASA”
- 1. 1 © NEC Corporation 20191 Accelerating Spark MLlib and DataFrame with Vector Processor “SX-Aurora TSUBASA” Takeo Hosomi ([email protected]) Takuya Araki, Ph.D. ([email protected]) Data Science Research Laboratories NEC Corporation
- 2. 2 © NEC Corporation 20192 Summary ▌NEC released new vector processor SX-Aurora TSUBASA Different characteristics than GPGPU: • Larger memory and higher memory bandwidth • Compatible with standard programming languages ▌Vector processor evolved from HPC Optimized for unified Big Data analytics Especially suitable for statistical ML ▌Packaged with machine learning middleware in C++/MPI Distributed and vectorized implementation Adapts Apache Spark APIs ~100x faster than Spark on x86
- 3. 3 © NEC Corporation 20193 What is a Vector Processor ? Processes many elements with one instruction, which is supported by large memory bandwidth Scalar processor Vector processor Computes many elements at once Suitable for simulation, AI, Big Data, etc. Unit of computation is small Suitable for web server, etc. Data Scalar computation Result Vector computation Result Data 256 256 1.2TB/s0.12TB/s
- 4. 4 © NEC Corporation 20194 New Vector Processor System “SX-Aurora TSUBASA” Downsized super computer: Can be used as an accelerator for Big Data and AI (Supercomputer) Rack Tower On-card Vector Processor
- 5. 5 © NEC Corporation 20195 On-card Vector Processor (Vector Engine) NEC-designed vector processor PCIe card implementation 8 cores / processor 4.9TF performance (single precision) 1.2TB/s memory bandwidth, 48GB memory Standard programing interface (C/C++/Fortran)
- 6. 6 © NEC Corporation 20196 Processor Specifications VE1.0 Specification vector length 256 words (16k bits) cores/CPU 8 frequency 1.6GHz core performance 307GF(DP) 614GF(SP) CPU performance 2.45TF(DP) 4.91TF(SP) cache capacity 16MB shared Memory bandwidth 1.2TB/s Memory capacity 48GB Software controllable cache 16MB core core core core core core core 1.2TB/s 3TB/s HBM2 memory x 6 0.4TB/s 307GF 2.45TF
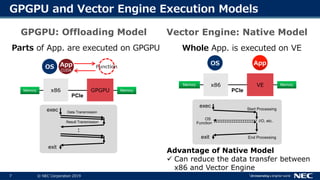
- 7. 7 © NEC Corporation 20197 GPGPU and Vector Engine Execution Models Parts of App. are executed on GPGPU Whole App. is executed on VE x86Memory GPGPU PCIe Memory exec Result Transmission Data Transmission exit : App CUDA FunctionOS exec OS Function Start Processing exit End Processing I/O, etc. x86Memory VE PCIe Memory AppOS GPGPU: Offloading Model Vector Engine: Native Model Advantage of Native Model Can reduce the data transfer between x86 and Vector Engine
- 8. 8 © NEC Corporation 20198 Usability Programing Environment automatic vectorization, automatic parallelization $ vi sample.c $ ncc sample.c Execution Environment $ ve_exec ./a.out execution x86 OS: RedHat Linux, Cent OS Fortran: F2003, F2008(partially) C: C11 C++: C++14 OpenMP: OpenMP4.5 MPI: MPI3.1 Vector Cross Compiler
- 9. 9 © NEC Corporation 20199 Why Vector Engine? High memory bandwidth and large memory capacity Supports native execution model Standard programing model Scale to multiple vector processors Direct data transfer among multiple vector processors through PCIe and InfiniBand Can accelerate memory intensive workloads
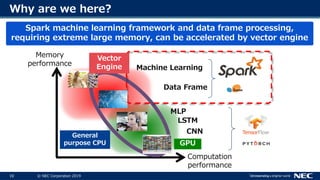
- 10. 10 © NEC Corporation 201910 Why are we here? Memory performance Computation performance z General purpose CPU CNN LSTM Data Frame GPU Machine Learning MLP Spark machine learning framework and data frame processing, requiring extreme large memory, can be accelerated by vector engine Vector Engine
- 11. Frovedis: Framework of vectorized and distributed data analytics
- 12. 12 © NEC Corporation 201912 Frovedis: FRamework Of VEctorized and DIStributed data analytics Frovedis Core Matrix Library Machine Learning DataFrame Spark / Python Interface Open Source! github.com/frovedis ▌C++ framework similar to Spark Supports Spark/Python interface ▌MPI is used for high performance communication ▌Optimized for SX-Aurora TSUBASA (also works on x86)
- 13. 13 © NEC Corporation 201913 Frovedis Core ▌Provides Spark core-like functionalities (e.g. map, reduce) Internally uses MPI to implement distributed processing Inherently supports multiple cards/servers ▌Users need not be aware of MPI to write distributed processing code Write functions in C++ Provide functions to the framework to run them in parallel ▌Example: double each element of distributed variable int two_times(int i) {return i * 2;} int main(...) { ... dvector<int> r = d1.map(two_times); } run “two_times” in parallel distributed variable
- 14. 14 © NEC Corporation 201914 Complete Sample Program (1/2) ▌Scatter a vector; double each element; then gather ▌Do not have to be aware of MPI (SPMD programming style) Looks more like a sequential program #include <frovedis.hpp> using namespace frovedis; int two_times(int i) {return i*2;} int main(int argc, char* argv[]) { use_frovedis use(argc, argv); std::vector<int> v = {1,2,3,4,5,6,7,8}; dvector<int> d1 = make_dvector_scatter(v); dvector<int> d2 = d1.map(two_times); std::vector<int> r = d2.gather(); } initialization scatter to create dvector gather to std::vector
- 15. 15 © NEC Corporation 201915 Complete Sample Program (2/2) ▌Works as an MPI program #include <frovedis.hpp> using namespace frovedis; int two_times(int i) {return i*2;} int main(int argc, char* argv[]) { use_frovedis use(argc, argv); std::vector<int> v = {1,2,3,4,5,6,7,8}; dvector<int> d1 = make_dvector_scatter(v); dvector<int> d2 = d1.map(two_times); std::vector<int> r = d2.gather(); } MPI_Init is called in the constructor, then branch: • rank 0: execute the below statements • rank 1-N: wait for RPC request from rank 0 rank 0 sends RPC request to rank 1-N to do the work in the destructor of “use”, MPI_Finalize is called and send RPC request to rank 1-N to stop the program
- 16. 16 © NEC Corporation 201916 Matrix Library ▌Implemented using Frovedis core and existing MPI libraries[*] [*] ScaLAPACK/PBLAS, LAPACK/BLAS, Parallel ARPACK ▌Supports dense and sparse matrix of various formats Dense: row-major, column-major, block-cyclic Sparse: CRS, CCS, ELL, JDS, JDS/CRS Hybrid (for better vectorization) ▌Provides basic matrix operations and linear algebra Dense: matrix multiply, solve, transpose, etc. Sparse: matrix-vector multiply (SpMV), transpose, etc. blockcyclic_matrix<double> A = X * Y; // mat mul gesv(A, b); // solve Ax = b Example
- 17. 17 © NEC Corporation 201917 Machine Learning Library ▌Supported algorithms: Linear model • Logistic Regression • Multinominal Logistic Regression • Linear Regression • Linear SVM ALS K-means Preprocessing • SVD, PCA ▌Under development: Frequent Pattern Mining Spectral Clustering Hierarchical Clustering Latent Dirichlet Allocation Deep Learning (MLP, CNN) Random Forest Gradient Boosting Decision Tree ▌We will support more! Word2vec Factorization Machines Decision Tree Naïve Bayes Graph algorithms • Shortest Path, PageRank, Connected Components Implemented with Frovedis Core and Matrix Library Supports both dense and sparse data Sparse data support is important in large scale machine learning
- 18. 18 © NEC Corporation 201918 DataFrame ▌Supports similar interface as Spark DataFrame Select, Filter, Sort, Join, Group by/Aggregate (SQL interface is not supported yet) ▌Implemented as distributed column store Each column is represented as distributed vector Each operation only scans argument columns: other columns are created when necessary (late materialization) Reduces size of data to access A B C D A B C D rank #0 rank #1 rank #2
- 19. 19 © NEC Corporation 201919 Spark / Python Interface ▌Writing C++ programs is sometimes tedious, so we created a wrapper interface to Spark Call the framework through the same Spark API Users do not have to be aware of vector hardware ▌Implementation: created a server with the functionalities Receives RPC request from Spark and executes ML algorithm, etc. Only pre-built algorithms can be used from Spark ▌Other languages can also be supported by this architecture Currently Python is supported (scikit-learn API)
- 20. 20 © NEC Corporation 201920 How it works ▌Rank 0 of the Frovedis server waits for RPC from driver of Spark ▌Data communication is done in parallel All workers/ranks send/receive data in parallel Assuming that the data can fit in the memory of the Frovedis server Spark Frovedis Server driver worker 0 worker 1 worker 2 rank 0 rank 1 rank 2 Interactive operation RPC request Data communication
- 21. 21 © NEC Corporation 201921 Programming Interface ▌Provides same interface as the Spark’s MLlib By changing importing module ▌How to use: … import org.apache.spark.mllib.classification.LogisticRegressionWithSGD … val model = LogisticRegressionWithSGD.train(data) … … import com.nec.frovedis.mllib.classificaiton.LogisticRegressionWithSGD //change import … FrovedisServer.initialize(...) // invoke Server val model = LogisticRegressionWithSGD.train(data) // no change: same API FrovedisServer.shut_down() // stop Server Original Spark program: logistic regression Change to call Frovedis implementation Specify command to invoke server (e.g. mpirun, qsub)
- 22. 22 © NEC Corporation 201922 YARN Support ▌Resource allocation by YARN is also supported Implemented in the collaboration with Cloudera (formerly Hortonworks) team ▌Implementation: YARN is modified to support Vector Engine (VE) as resource (like GPU) Created a wrapper program of mpirun, which works as YARN client • Obtain VE from YARN Resource Manager, and run MPI program on the given VE Used the wrapper as the server invocation command • Specified in FrovedisServer.initialize(...) YARN RM VE VE VE Spark mpirun wrapper mpirun
- 23. 23 © NEC Corporation 201923 Performance Evaluation: Machine Learning ▌Xeon (Gold 6126) 1 socket vs 1 VE, with sparse data (w/o I/O) LR uses CTR data provided by Criteo (1/4 of the original, 6GB) K-means and SVD used Wikipedia doc-term matrix (10GB) Spark version: 2.2.1 1 1 1 10.6 8.8 5.3 113.2 42.8 56.8 0 20 40 60 80 100 120 LR K-means SVD Spark/x86 Frovedis/x86 Frovedis/VE SpeedUp(Spark=1)
- 24. 24 © NEC Corporation 201924 Performance Evaluation: DataFrame ▌Evaluated with TPC-H SF-20 Q1: group by/aggregate Q3: filter, join, group by/aggregate Q5: filter, join, group by/aggregate (larger join) Q6: filter, group by/aggregate 1 1 1 13.2 8.8 5.8 10.610.1 33.8 47.3 34.8 0 10 20 30 40 50 Q01 Q03 Q05 Q06 Spark/x86 Frovedis/x86 Frovedis/VE SpeedUp(Spark=1)
- 25. 25 © NEC Corporation 201925 NEC X Vector Engine Data Acceleration Center (VEDAC) ▌NEC X is the innovation accelerator for NEC’s emerging technologies, located in Silicon Valley ▌Today opened VEDAC Lab: Several servers with multiple SX-Aurora vector engine cards running Frovedis middleware ▌Remote access for qualified companies, universities and government labs; or physically by entrepreneurs: Short series of tutorials on vector processing Upload data to VEDAC; get true sense of performance in actual applications ▌Request access: [email protected] Please follow @incNECX for more latest news
- 26. 26 © NEC Corporation 201926 Conclusion ▌NEC released new vector processor SX-Aurora TSUBASA that can accelerate data analytics and machine learning applications ▌We have developed data analytics middleware Frovedis for SX- Aurora TSUBASA ▌We show a 10x to 100x performance improvement on several machine learning and data frame processing ▌NEC-X has opened VEDAC lab for accessing SX-Aurora TSUBASA AI platform with Frovedis.
- 27. 27 © NEC Corporation 201927 Biographies ▌ Takeo Hosomi Takeo Hosomi is a senior engineer at NEC Data Science Research Laboratories. He has a broad experience in High Performance Computing and Big Data. ▌ Takuya Araki, Ph.D. Takuya Araki received B.E., M.E., and Ph.D. degrees from the University of Tokyo, Japan in 1994, 1996, and 1999, respectively. He was a visiting researcher at Argonne National Laboratory from 2003 to 2004. He is currently a Senior Principal Researcher at NEC Data Science Research Laboratories. His research interests include parallel and distributed computing and its application to AI/machine learning. He is also a director of the Information Processing Society of Japan (IPSJ).
- 28. 28 © NEC Corporation 201928 Biographies ▌ NEC X NEC X, Inc. accelerates the development of innovative products and services based on the strengths of NEC Laboratories technologies. The organization was launched by NEC Corp. in 2018 to fast-track technologies and business ideas selected from inside and outside NEC. For companies launched by its Corporate Accelerator Program, often with partner venture capital investments, NEC X supports their business development activities to help them achieve revenue growth. Additionally, NEC X provides an option for entrepreneurs, startups and existing companies to use NEC’s emerging technologies in the Americas. The company is centrally located in Silicon Valley for access to its entrepreneurial ecosystem and its strong high-technology market. Learn more at http://nec-x.com.