Accelerating stochastic gradient descent using adaptive mini batch size3
0 likes390 views

This document proposes a method called Train-Measure-Adapt-Repeat for accelerating stochastic gradient descent training of deep neural networks using adaptive mini-batch sizes. The method starts with an extremely small mini-batch size, such as 4-8 samples, to allow for faster training initially through more frequent weight updates. Accuracy is evaluated over time rather than by the number of steps, and the mini-batch size is increased adaptively when accuracy improvements stall. Experiments on image classification datasets demonstrate the method reaching higher accuracy levels faster than using fixed large mini-batch sizes.









![“Stochastic Learning” or “Stochastic Gradient Descent” (SGD) is
done by taking small random samples (mini-batches) instead of the
whole batch of training data “Batch Learning”. Faster to converge
and better in handling the noise and non-linearity. That’s why batch
learning was considered inefficient[1][2]
.
1. Y. LeCun, “Efficient backprop”
2. D. R. Wilson and T. R. Martinez, “The general inefficiency of batch training for gradient descent
learning,”
Batch Learning vs. Stochastic Learning](https://image.slidesharecdn.com/acceleratingstochasticgradientdescentusingadaptivemini-batchsize3-191010121657/85/Accelerating-stochastic-gradient-descent-using-adaptive-mini-batch-size3-11-320.jpg)
























Accelerating stochastic gradient descent using adaptive mini batch size3
- 1. Accelerating Stochastic Gradient Descent Using Adaptive Mini-Batch Size
- 2. Authors: ● Muayyad Alsadi <[email protected]> ● Rawan Ghnemat <[email protected]> ● Arafat Awajan <[email protected]>
- 3. What if you could just fast-forward through training process? 8x This way training becomes feasible even on commodity CPUs (without GPUs), getting high accuracy within hours.
- 4. Background
- 5. Artificial Neural Network (ANN) / Some Types and Applications ● Fully connected multi-layer Deep Neural Networks (DNN) ● Convolutional Neural Network (CNN) ○ Spacial (Image) ○ Context (Text and NLP) ● Recursive Neural Network ○ Sequences (Text letters, Stock events)
- 6. Artificial Neural Network (ANN) / Some Types and Applications ● Convolutional Neural Network (CNN) ○ Spacial (Image): classification/regression ○ Context (Text and NLP): classification/regression ● Recursive Neural Network ○ Sequences (Text letters, Stock events) ■ Seq2Seq: Translation, summarization, ... ■ Seq2Label ■ Seq2Value
- 7. ● Massive number of trainable weights to tune ● Massive number Multiply–Accumulate (MAC) operations ● Vanishing/Exploding Gradients Deep Learning / some challenges
- 8. ● Massive number of trainable weights to tune ● Massive number Multiply–Accumulate (MAC) operations ○ Low throughput (ex. images/second) ● Vanishing/Exploding Gradients ○ Slow to converge Deep Learning / some challenges
- 9. Input Output Deep Neural Network Millions of Operations Per Item
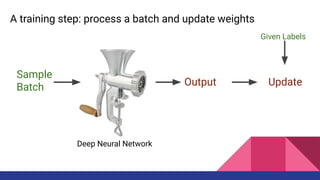
- 10. Sample Batch Update Deep Neural Network Given Labels Output A training step: process a batch and update weights
- 11. “Stochastic Learning” or “Stochastic Gradient Descent” (SGD) is done by taking small random samples (mini-batches) instead of the whole batch of training data “Batch Learning”. Faster to converge and better in handling the noise and non-linearity. That’s why batch learning was considered inefficient[1][2] . 1. Y. LeCun, “Efficient backprop” 2. D. R. Wilson and T. R. Martinez, “The general inefficiency of batch training for gradient descent learning,” Batch Learning vs. Stochastic Learning
- 12. Sample Update Deep Neural Network Given Labels Output Factors Affecting Convergence Speed Sample Size Design Complexity / Depth / Number of MAC operators # Classes Learning Rate Momentum Opt. Algo.
- 14. ● Sample size related ● Learning rate related ● Optimization Algorithm Related ● NN design related ● Transforming Input/Output Literature Review
- 15. ● Sample size related ○ Too big batch-size (8192 images per batch) ○ Increasing batch-size ● Learning rate related ○ Per-dimension ○ Fading ○ Momentum ○ Cyclic ○ Warm restart... ● Optimization Algorithm Related ○ AdaGrad, Adam, AdaDelta, ... Literature Review / see paper ● NN design related ○ SqueezeNet, MobileNet ○ Separable operators ○ Batch-norm ○ Early AUX classifier branches ● Transforming Input/Output ○ Reusing existing model (fine-tuning) ○ Knowledge transfer
- 16. Proposed Method
- 17. Do very high risk initializations using extremely small mini-batch size (ex. 4 or 8 samples per batch). Then “Train-Measure-Adapt-Repeat”. As long as it’s getting better results keep using such fast-forwarding settings. When stuck use larger mini-batch size (for example, 32 samples per batch). Proposed Method
- 18. ff_criteria can be defined with respect to change in evaluation accuracy like this If (acc_new>acc_old) then mode=ff else model=normal
- 19. ● Specially for cold start (initialization) ● Instead of too big batch-size like 8,192 samples per batch use extremely small mini-batch size like 4 or 8 samples per batch! (as long as hardware is fully utilized) ● The network is too cold, it’s already too bad and you have nothing to lose. Use extremely small mini-batch size
- 20. Assuming that the hardware is fully utilized and have constant throughput (Images/Seconds), processing a sample of 8 images is 4 times faster than processing a batch of 32 images. Doing 4 times more updates. A good guess for batch size is number of cores in your computer. (scope of paper is training on commodity hardware). Why it ticks faster?
- 21. By using 4x smaller batch-size, we are doing 4x more higher risk updates. Batch size have linear effect on speed but effect on accuracy is not linear. Don’t look at accuracy by number of steps but look at accuracy over time. It ticks faster but does it converge faster?
- 22. Experiments: Fine-tuning Inception v1 pre-trained on ImageNet 1K task.
- 23. Experiment: The Caltech-UCSD Birds-200-2011 Dataset
- 24. Experiment: Birds 200 Dataset
- 25. Accuracy over steps: accuracy of batch-size=10 (in cyan) is always below others Misleading
- 26. Accuracy over time: accuracy of batch-size=10 (in cyan) reached 56% in 2 hours, while others were lagging behind at 40%, 28%, and 10%.
- 27. Experiment: The Oxford-IIIT Pet Dataset (Pets-37)
- 29. Eval accuracy over time: using mini-batch size of 8 reached 80% accuracy within one hour only.
- 30. Experiment: Adaptive part on Birds-200 Dataset
- 31. Eval accuracy over time: reaching ~72% accuracy within ~2:20 hours
- 33. Summary: Train-Measure-Adapt-Repeat ● Start with very small mini-batch size and large learning rate ○ BatchSize=4; LearningRate=0.1 ● Let mini-batch size be cyclic ○ Switch between two settings (batch size of 8 and 32) ○ Adaptive, non-periodic, based on evaluation accuracy ○ Change the bounds of the settings as you go
- 34. Q & A
- 35. Thank you Follow me on Github http://muayyad-alsadi.github.io/