Accelerating TensorFlow with RDMA for high-performance deep learning
Download as PPTX, PDF12 likes3,647 views

The document discusses the acceleration of TensorFlow using RDMA (Remote Direct Memory Access) to enhance deep learning performance, highlighting key technologies such as gRPC, TensorFlow, and various high-performance computing (HPC) architectures. It outlines the current trends in deep learning stacks, the importance of big data in analytics, and introduces specific benchmarking efforts to evaluate the integration of RDMA with TensorFlow for optimizing tensor communication. The presentation ultimately aims to explore how native RDMA support can provide significant performance improvements in deep learning applications.






































Accelerating TensorFlow with RDMA for high-performance deep learning
- 1. Accelerating TensorFlow with RDMA for High- Performance Deep Learning Dhabaleswar K. (DK) Panda The Ohio State University E-mail: [email protected] http://www.cse.ohio-state.edu/~panda Talk at DataWorks Summit Berlin 2018 by Xiaoyi Lu The Ohio State University E-mail: [email protected] http://www.cse.ohio-state.edu/~luxi
- 2. DataWorks Summit@Berlin 2018 2Network Based Computing Laboratory • Deep Learning is a sub-set of Machine Learning – But, it is perhaps the most radical and revolutionary subset • Deep Learning is going through a resurgence – Model: Excellent accuracy for deep/convolutional neural networks – Data: Public availability of versatile datasets like MNIST, CIFAR, and ImageNet – Capability: Unprecedented computing and communication capabilities: Multi-/Many-Core, GPGPUs, Xeon Phi, InfiniBand, RoCE, etc. • Big Data has become one of the most important elements in business analytics – Increasing demand for getting Big Value out of Big Data to drive the revenue continuously growing Why Deep Learning is so hot? Courtesy: http://www.zdnet.com/article/caffe2-deep-learning-wide-ambitions- flexibility-scalability-and-advocacy/ MNIST handwritten digits Deep Neural Network
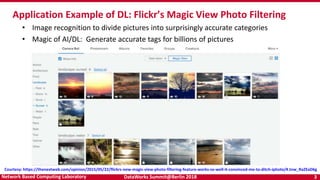
- 3. DataWorks Summit@Berlin 2018 3Network Based Computing Laboratory Application Example of DL: Flickr’s Magic View Photo Filtering Courtesy: https://thenextweb.com/opinion/2015/05/22/flickrs-new-magic-view-photo-filtering-feature-works-so-well-it-convinced-me-to-ditch-iphoto/#.tnw_RaZEaD6g • Image recognition to divide pictures into surprisingly accurate categories • Magic of AI/DL: Generate accurate tags for billions of pictures
- 4. DataWorks Summit@Berlin 2018 4Network Based Computing Laboratory • TensorFlow • Caffe/Caffe2 • Torch • SparkNet • TensorFrame • DeepLearning4J • BigDL • CNTK • mmlspark • Many others… Examples of Deep Learning Stacks
- 5. DataWorks Summit@Berlin 2018 5Network Based Computing Laboratory Trends of Deep Learning Stacks • Google TensorFlow • Microsoft CNTK • Facebook Caffe2 • Google Search Trend (March 23, 2018)
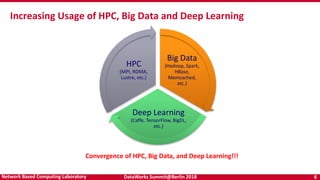
- 6. DataWorks Summit@Berlin 2018 6Network Based Computing Laboratory Big Data (Hadoop, Spark, HBase, Memcached, etc.) Deep Learning (Caffe, TensorFlow, BigDL, etc.) HPC (MPI, RDMA, Lustre, etc.) Increasing Usage of HPC, Big Data and Deep Learning Convergence of HPC, Big Data, and Deep Learning!!!
- 7. DataWorks Summit@Berlin 2018 7Network Based Computing Laboratory • BLAS Libraries – the heart of math operations – Atlas/OpenBLAS – NVIDIA cuBlas – Intel Math Kernel Library (MKL) • DNN Libraries – the heart of Convolutions! – NVIDIA cuDNN (already reached its 7th iteration – cudnn-v7) – Intel MKL-DNN (MKL 2017) – recent but a very promising development • Communication Libraries – the heart of model parameter updating – RDMA – GPUDirect RDMA Highly-Optimized Underlying Libraries with HPC Technologies
- 8. DataWorks Summit@Berlin 2018 8Network Based Computing Laboratory Outline • Overview of gRPC, TensorFlow, and RDMA Technologies • Accelerating gRPC and TensorFlow with RDMA • Benchmarking gRPC and TensorFlow • Performance Evaluation • Conclusion
- 9. DataWorks Summit@Berlin 2018 9Network Based Computing Laboratory Architecture Overview of gRPC Key Features: • Simple service definition • Works across languages and platforms • C++, Java, Python, Android Java etc • Linux, Mac, Windows • Start quickly and scale • Bi-directional streaming and integrated authentication • Used by Google (several of Google’s cloud products and Google externally facing APIs, TensorFlow), NetFlix, Docker, Cisco, Juniper Networks etc. • Uses sockets for communication! Source: http://www.grpc.io/ Large-scale distributed systems composed of micro services
- 10. DataWorks Summit@Berlin 2018 10Network Based Computing Laboratory Architecture Overview of Google TensorFlow Key Features: • Widely used for Deep Learning • Open source software library for numerical computation using data flow graphs • Graph edges represent the multidimensional data arrays • Nodes in the graph represent mathematical operations • Flexible architecture allows to deploy computation to one or more CPUs or GPUs in a desktop, server, or mobile device with a single API • Used by Google, Airbnb, DropBox, Snapchat, Twitter • Communication and Computation intensive Source: https://www.tensorflow.org/ Architecture of TensorFlow
- 11. DataWorks Summit@Berlin 2018 11Network Based Computing Laboratory Overview of gRPC with TensorFlow Worker services communicate among each other using gRPC, or gRPC+X! Client Master Worker /job:PS/task:0 Worker /job:Worker/task:0 CPU GPU gRPC server/ client CPU GPU gRPC server/ client
- 12. DataWorks Summit@Berlin 2018 12Network Based Computing Laboratory Drivers of Modern HPC Cluster and Data Center Architecture • Multi-core/many-core technologies • Remote Direct Memory Access (RDMA)-enabled networking (InfiniBand and RoCE) – Single Root I/O Virtualization (SR-IOV) • Solid State Drives (SSDs), NVM, Parallel Filesystems, Object Storage Clusters • Accelerators (NVIDIA GPGPUs and Intel Xeon Phi) High Performance Interconnects – InfiniBand (with SR-IOV) <1usec latency, 200Gbps Bandwidth> Multi-/Many-core Processors Cloud CloudSDSC Comet TACC Stampede Accelerators / Coprocessors high compute density, high performance/watt >1 TFlop DP on a chip SSD, NVMe-SSD, NVRAM
- 13. DataWorks Summit@Berlin 2018 13Network Based Computing Laboratory Interconnects and Protocols in OpenFabrics Stack Kernel Space Application / Middleware Verbs Ethernet Adapter Ethernet Switch Ethernet Driver TCP/IP 1/10/25/40/ 100 GigE InfiniBand Adapter InfiniBand Switch IPoIB IPoIB Ethernet Adapter Ethernet Switch Hardware Offload TCP/IP 10/40 GigE- TOE InfiniBand Adapter InfiniBand Switch User Space RSockets RSockets iWARP Adapter Ethernet Switch TCP/IP User Space iWARP RoCE Adapter Ethernet Switch RDMA User Space RoCE InfiniBand Switch InfiniBand Adapter RDMA User Space IB Native Sockets Application / Middleware Interface Protocol Adapter Switch InfiniBand Adapter InfiniBand Switch RDMA SDP SDP
- 14. DataWorks Summit@Berlin 2018 14Network Based Computing Laboratory • 163 IB Clusters (32.6%) in the Nov’17 Top500 list – (http://www.top500.org) • Installations in the Top 50 (17 systems): Large-scale InfiniBand Installations 19,860,000 core (Gyoukou) in Japan (4th) 60,512 core (DGX SATURN V) at NVIDIA/USA (36th) 241,108 core (Pleiades) at NASA/Ames (17th) 72,000 core (HPC2) in Italy (37th) 220,800 core (Pangea) in France (21st) 152,692 core (Thunder) at AFRL/USA (40th) 144,900 core (Cheyenne) at NCAR/USA (24th) 99,072 core (Mistral) at DKRZ/Germany (42nd) 155,150 core (Jureca) in Germany (29th) 147,456 core (SuperMUC) in Germany (44th) 72,800 core Cray CS-Storm in US (30th) 86,016 core (SuperMUC Phase 2) in Germany (45th) 72,800 core Cray CS-Storm in US (31st) 74,520 core (Tsubame 2.5) at Japan/GSIC (48th) 78,336 core (Electra) at NASA/USA (33rd) 66,000 core (HPC3) in Italy (51st) 124,200 core (Topaz) SGI ICE at ERDC DSRC in US (34th) 194,616 core (Cascade) at PNNL (53rd) 60,512 core (NVIDIA DGX-1/Relion) at Facebook in USA (35th) and many more!
- 15. DataWorks Summit@Berlin 2018 15Network Based Computing Laboratory • Introduced in Oct 2000 • High Performance Data Transfer – Interprocessor communication and I/O – Low latency (<1.0 microsec), High bandwidth (up to 25 GigaBytes/sec -> 200Gbps), and low CPU utilization (5-10%) • Flexibility for LAN and WAN communication • Multiple Transport Services – Reliable Connection (RC), Unreliable Connection (UC), Reliable Datagram (RD), Unreliable Datagram (UD), and Raw Datagram – Provides flexibility to develop upper layers • Multiple Operations – Send/Recv – RDMA Read/Write – Atomic Operations (very unique) • high performance and scalable implementations of distributed locks, semaphores, collective communication operations • Leading to big changes in designing HPC clusters, file systems, cloud computing systems, grid computing systems, …. Open Standard InfiniBand Networking Technology
- 16. DataWorks Summit@Berlin 2018 16Network Based Computing Laboratory RDMA over Converged Enhanced Ethernet (RoCE) IB Verbs Application Hardware RoCE IB Verbs Application RoCE v2 InfiniBand Link Layer IB Network IB Transport IB Verbs Application InfiniBand Ethernet Link Layer IB Network IB Transport Ethernet Link Layer UDP / IP IB Transport • Takes advantage of IB and Ethernet – Software written with IB-Verbs – Link layer is Converged (Enhanced) Ethernet (CE) – 100Gb/s support from latest EDR and ConnectX- 3 Pro adapters • Pros: IB Vs RoCE – Works natively in Ethernet environments • Entire Ethernet management ecosystem is available – Has all the benefits of IB verbs – Link layer is very similar to the link layer of native IB, so there are no missing features • RoCE v2: Additional Benefits over RoCE – Traditional Network Management Tools Apply – ACLs (Metering, Accounting, Firewalling) – GMP Snooping for Optimized Multicast – Network Monitoring Tools Courtesy: OFED, Mellanox Network Stack Comparison Packet Header Comparison ETH L2 Hdr Ethertype IB GRH L3 Hdr IB BTH+ L4 Hdr RoCE ETH L2 Hdr Ethertype IP Hdr L3 Hdr IB BTH+ L4 Hdr Proto# RoCEv2 UDP Hdr Port#
- 17. DataWorks Summit@Berlin 2018 17Network Based Computing Laboratory • RDMA for Apache Spark • RDMA for Apache Hadoop 2.x (RDMA-Hadoop-2.x) – Plugins for Apache, Hortonworks (HDP) and Cloudera (CDH) Hadoop distributions • RDMA for Apache HBase • RDMA for Memcached (RDMA-Memcached) • RDMA for Apache Hadoop 1.x (RDMA-Hadoop) • OSU HiBD-Benchmarks (OHB) – HDFS, Memcached, HBase, and Spark Micro-benchmarks • http://hibd.cse.ohio-state.edu • Users Base: 280 organizations from 34 countries • More than 26,000 downloads from the project site The High-Performance Big Data (HiBD) Project Available for InfiniBand and RoCE Also run on Ethernet Available for x86 and OpenPOWER Support for Singularity and Docker
- 18. DataWorks Summit@Berlin 2018 18Network Based Computing Laboratory HiBD Release Timeline and Downloads 0 5000 10000 15000 20000 25000 30000 NumberofDownloads Timeline RDMA-Hadoop2.x0.9.1 RDMA-Hadoop2.x0.9.6 RDMA-Memcached0.9.4 RDMA-Hadoop2.x0.9.7 RDMA-Spark0.9.1 RDMA-HBase0.9.1 RDMA-Hadoop2.x1.0.0 RDMA-Spark0.9.4 RDMA-Hadoop2.x1.3.0 RDMA-Memcached0.9.6&OHB-0.9.3 RDMA-Spark0.9.5 RDMA-Hadoop1.x0.9.0 RDMA-Hadoop1.x0.9.8 RDMA-Memcached0.9.1&OHB-0.7.1 RDMA-Hadoop1.x0.9.9
- 19. DataWorks Summit@Berlin 2018 19Network Based Computing Laboratory • Can similar designs be done for gRPC and TensorFlow to achieve significant performance benefits by taking advantage of native RDMA support? • How do we benchmark gRPC and TensorFlow for both deep learning and system researchers? • What kind of performance benefits we can get through native RDMA-based designs in gRPC and TensorFlow? Motivation
- 20. DataWorks Summit@Berlin 2018 20Network Based Computing Laboratory Outline • Overview of gRPC, TensorFlow, and RDMA Technologies • Accelerating gRPC and TensorFlow with RDMA • Benchmarking gRPC and TensorFlow • Performance Evaluation • Conclusion
- 21. DataWorks Summit@Berlin 2018 21Network Based Computing Laboratory Tensor Communication over gRPC channel • Rendezvous protocol • TensorFlow worker (tensor receiving process) actively requests for tensors to the parameter server (tensor sending process) • Worker issues Tensor RPC request that to Parameter Server (PS) • PS finds the requested tensor, and responds to the worker • gRPC core uses recvmsg and sendmsg primitives for receiving and sending payloads • Tensor Transmission uses iovec structures R. Biswas, X. Lu, and D. K. Panda, Designing a Micro-Benchmark Suite to Evaluate gRPC for TensorFlow: Early Experiences, BPOE, 2018.
- 22. DataWorks Summit@Berlin 2018 22Network Based Computing Laboratory • gRPC + Verbs – Dedicated verbs channel for tensor communication – gRPC channel for administrative task communication • gRPC + MPI – Dedicated MPI channel for tensor communication – gRPC channel for administrative task communication • Uber Horovod – Uber’s approach of MPI based distributed TensorFlow • Baidu Tensorflow-Allreduce – Baidu’s approach of MPI based distributed TensorFlow High Performance Tensor Communication Channel
- 23. DataWorks Summit@Berlin 2018 23Network Based Computing Laboratory TensorFlow workload via gRPC iovec Buffer Distribution Observed for TensorFlow training over gRPC • Small, Medium and Large indicate buffers of few Bytes, KBytes and MBytes of length • gRPC payload may contain a uniform distribution of such Small buffers • A lot of Large buffers and a few Small buffers may create a skew distribution of such buffers in one gRPC payload R. Biswas, X. Lu, and D. K. Panda, Designing a Micro- Benchmark Suite to Evaluate gRPC for TensorFlow: Early Experiences, BPOE, 2018.
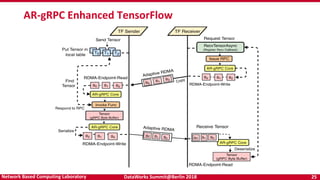
- 24. DataWorks Summit@Berlin 2018 24Network Based Computing Laboratory OSU AR-gRPC Architecture R. Biswas, X. Lu, and D. K. Panda, Characterizing and Accelerating TensorFlow: Can Adaptive and RDMA-based RPC Benefit It? (Under Review) • Adaptive RDMA gRPC • Features – Hybrid Communication engine • Adaptive protocol selection between eager and rendezvous – Message pipelining and coalescing • Adaptive chunking and accumulation • Intelligent threshold detection – Zero copy transmission • Zero copy send/recv
- 25. DataWorks Summit@Berlin 2018 25Network Based Computing Laboratory AR-gRPC Enhanced TensorFlow
- 26. DataWorks Summit@Berlin 2018 26Network Based Computing Laboratory Outline • Overview of gRPC, TensorFlow, and RDMA Technologies • Accelerating gRPC and TensorFlow with RDMA • Benchmarking gRPC and TensorFlow • Performance Evaluation • Conclusion
- 27. DataWorks Summit@Berlin 2018 27Network Based Computing Laboratory MNIST CIFAR-10 ImageNet Category Digit Classification Object Classification Object Classification Resolution 28 × 28 B&W 32 × 32 Color 256 × 256 Color Classes 10 10 1000 Training Images 60 K 50 K 1.2 M Testing Images 10 K 10 K 100 K Available Benchmarks, Models, and Datasets Model Layers (Conv. / Full-connected) Dataset Framework LeNet 2 / 2 MNIST CaffeOnSpark, TensorFlowOnSpark SoftMax Regression NA / NA MNIST TensorFlowOnSpark CIFAR-10 Quick 3 / 1 CIFAR-10 CaffeOnSpark, TensorFlowOnSpark, MMLSpark VGG-16 13 / 3 CIFAR-10 BigDL AlexNet 5 / 3 ImageNet CaffeOnSpark GoogLeNet 22 / 0 ImageNet CaffeOnSpark Resnet-50 53/1 Synthetic TensorFlow
- 28. DataWorks Summit@Berlin 2018 28Network Based Computing Laboratory • Current DL models and benchmarks are deep learning research oriented • Example: Facebook caffe2 takes 1 hour to train ImageNet data (State of the art)1 • However, many system researchers are focused on improving the communication engine of deep learning frameworks • A fast benchmark that models deep learning characteristics is highly desirable Are Current Benchmarks Sufficient? 1. Goyal, Priya, et al. "Accurate, large minibatch SGD: training imagenet in 1 hour." arXiv preprint arXiv:1706.02677 (2017).
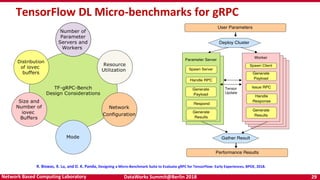
- 29. DataWorks Summit@Berlin 2018 29Network Based Computing Laboratory TensorFlow DL Micro-benchmarks for gRPC R. Biswas, X. Lu, and D. K. Panda, Designing a Micro-Benchmark Suite to Evaluate gRPC for TensorFlow: Early Experiences, BPOE, 2018.
- 30. DataWorks Summit@Berlin 2018 30Network Based Computing Laboratory Outline • Overview of gRPC, TensorFlow, and RDMA Technologies • Accelerating gRPC and TensorFlow with RDMA • Benchmarking gRPC and TensorFlow • Performance Evaluation • Conclusion
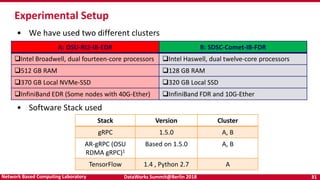
- 31. DataWorks Summit@Berlin 2018 31Network Based Computing Laboratory Experimental Setup • We have used two different clusters • Software Stack used A: OSU-RI2-IB-EDR B: SDSC-Comet-IB-FDR Intel Broadwell, dual fourteen-core processors Intel Haswell, dual twelve-core processors 512 GB RAM 128 GB RAM 370 GB Local NVMe-SSD 320 GB Local SSD InfiniBand EDR (Some nodes with 40G-Ether) InfiniBand FDR and 10G-Ether Stack Version Cluster gRPC 1.5.0 A, B AR-gRPC (OSU RDMA gRPC)1 Based on 1.5.0 A, B TensorFlow 1.4 , Python 2.7 A
- 32. DataWorks Summit@Berlin 2018 32Network Based Computing Laboratory Performance Benefits for AR-gRPC with Micro-Benchmark Point-to-Point Latency • AR-gRPC (OSU design) Latency on SDSC-Comet-FDR – Up to 2.7x performance speedup over Default gRPC (IPoIB) for Latency for small messages. – Up to 2.8x performance speedup over Default gRPC (IPoIB) for Latency for medium messages. – Up to 2.5x performance speedup over Default gRPC (IPoIB) for Latency for large messages. 0 15 30 45 60 75 90 2 8 32 128 512 2K 8K Latency(us) payload (Bytes) Default gRPC (IPoIB-56Gbps) AR-gRPC (RDMA-56Gbps) 0 200 400 600 800 1000 16K 32K 64K 128K 256K 512KLatency(us) Payload (Bytes) Default gRPC (IPoIB- 56Gbps) AR-gRPC (RDMA-56 Gbps) 100 3800 7500 11200 14900 18600 1M 2M 4M 8M Latency(us) Payload (Bytes) Default gRPC (IPoIB-56Gbps) AR-gRPC (RDMA- 56Gbps) R. Biswas, X. Lu, and D. K. Panda, Characterizing and Accelerating TensorFlow: Can Adaptive and RDMA-based RPC Benefit It? (Under Review)
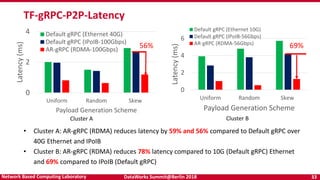
- 33. DataWorks Summit@Berlin 2018 33Network Based Computing Laboratory 0 2 4 Uniform Random Skew Latency(ms) Payload Generation Scheme Default gRPC (Ethernet 40G) Default gRPC (IPoIB-100Gbps) AR-gRPC (RDMA-100Gbps) TF-gRPC-P2P-Latency 0 2 4 6 Uniform Random Skew Latency(ms) Payload Generation Scheme Default gRPC (Ethernet 10G) Default gRPC (IPoIB-56Gbps) AR-gRPC (RDMA-56Gbps) • Cluster A: AR-gRPC (RDMA) reduces latency by 59% and 56% compared to Default gRPC over 40G Ethernet and IPoIB • Cluster B: AR-gRPC (RDMA) reduces 78% latency compared to 10G (Default gRPC) Ethernet and 69% compared to IPoIB (Default gRPC) Cluster A Cluster B 56% 69%
- 34. DataWorks Summit@Berlin 2018 34Network Based Computing Laboratory TF-gRPC-P2P-Bandwidth 0 1000 2000 3000 4000 5000 6000 Uniform Random Skew Bandwidth(MB/s) Payload Generation Scheme Default gRPC (Ethernet 40G) Default gRPC (IPoIB-100Gbps) AR-gRPC (RDMA-100Gbps) 0 2000 4000 6000 Uniform Random Skew Bandwidth(MB/s) Payload Generation Scheme Default gRPC (Ethernet 10G) Default gRPC (IPoIB-56Gbps) AR-gRPC (RDMA-56Gbps)Cluster A Cluster B • Cluster A: AR-gRPC (RDMA) gRPC achieves a 2.14x bandwidth increase compared to Default gRPC (IPoIB and Ethernet) • Cluster B: AR-gRPC (RDMA) achieves 3.2x bandwidth compared to Default gRPC IPoIB for skewed data 2.14x 3.2x
- 35. DataWorks Summit@Berlin 2018 35Network Based Computing Laboratory 0 1000 2000 3000 4000 Uniform Random Skew RPC/second Payload Generation Scheme Default gRPC (Ethernet 40G) Default gRPC (IPoIB-100Gbps) AR-gRPC (RDMA-100Gbps) TF-gRPC-PS-Throughput 0 1000 2000 3000 4000 Uniform Random Skew RPC/second Payload Generation Scheme Default gRPC (Ethernet 10G) Default gRPC (IPoIB-56Gbps) AR-gRPC (RDMA-56Gbps) Cluster A Cluster B • Cluster A: AR-gRPC (RDMA) gRPC achieves a 3.4x speedup compared to Default gRPC over IPoIB for uniform scheme • Cluster B: AR-gRPC (RDMA) achieves 3.6x bandwidth compared to Default gRPC over IPoIB for uniform scheme 3.4 x 3.6 x
- 36. DataWorks Summit@Berlin 2018 36Network Based Computing Laboratory Performance Benefits for AR-gRPC with Micro-Benchmark Fully-Connected Architecture (Mimic TensorFlow communication) • AR-gRPC (OSU design) TensorFlow Mimic test on SDSC-Comet-FDR – Up to 60% reduction in average latency over Default gRPC (IPoIB) – Up to 2.68x performance speedup over Default gRPC (IPoIB) 0 6 12 18 24 30 2M 4M 8M Latency(ms) payload (Bytes) Default gRPC (IPoIB-56Gbps) AR-gRPC (RDMA-56Gbps) 0 100 200 300 400 500 2M 4M 8M Calls/Second payload (Bytes) Default gRPC (IPoIB-56Gbps) AR-gRPC (RDMA-56Gbps) 2.68 x
- 37. DataWorks Summit@Berlin 2018 37Network Based Computing Laboratory 0 200 400 600 800 16 32 64 Images/Second Batch Size gRPPC (IPoIB-100Gbps) Verbs (RDMA-100Gbps) MPI (RDMA-100Gbps) AR-gRPC (RDMA-100Gbps) 0 200 400 600 16 32 64 Images/Second Batch Size gRPPC (IPoIB-100Gbps) Verbs (RDMA-100Gbps) MPI (RDMA-100Gbps) AR-gRPC (RDMA-100Gbps) 0 100 200 300 16 32 64 Images/Second Batch Size gRPPC (IPoIB-100Gbps) Verbs (RDMA-100Gbps) MPI (RDMA-100Gbps) AR-gRPC (RDMA-100Gbps) Performance Benefit for TensorFlow (Resnet50) • TensorFlow Resnet50 performance evaluation on an IB EDR cluster – Up to 30% performance speedup over Default gRPC (IPoIB) for 8 GPUs – Up to 34% performance speedup over Default gRPC (IPoIB) for 16 GPUs – Up to 44% performance speedup over Default gRPC (IPoIB) for 24 GPUs 4 Nodes (8 GPUs) 8 Nodes (16 GPUS) 12 Nodes (24 GPUS)
- 38. DataWorks Summit@Berlin 2018 38Network Based Computing Laboratory 0 50 100 150 200 16 32 64 Images/Second Batch Size gRPPC (IPoIB-100Gbps) Verbs (RDMA-100Gbps) MPI (RDMA-100Gbps) AR-gRPC (RDMA-100Gbps) Performance Benefit for TensorFlow (Inception3) • TensorFlow Inception3 performance evaluation on an IB EDR cluster – Up to 20% performance speedup over Default gRPC (IPoIB) for 8 GPUs – Up to 34% performance speedup over Default gRPC (IPoIB) for 16 GPUs – Up to 37% performance speedup over Default gRPC (IPoIB) for 24 GPUs 4 Nodes (8 GPUS) 8 Nodes (16 GPUS) 12 Nodes (24 GPUS) 0 200 400 600 16 32 64 Images/Second Batch Size gRPPC (IPoIB-100Gbps) Verbs (RDMA-100Gbps) MPI (RDMA-100Gbps) AR-gRPC (RDMA-100Gbps) 0 100 200 300 400 16 32 64Images/Second Batch Size gRPPC (IPoIB-100Gbps) Verbs (RDMA-100Gbps) MPI (RDMA-100Gbps) AR-gRPC (RDMA-100Gbps)
- 39. DataWorks Summit@Berlin 2018 39Network Based Computing Laboratory Outline • Overview of gRPC, TensorFlow, and RDMA Technologies • Accelerating gRPC and TensorFlow with RDMA • Benchmarking gRPC and TensorFlow • Performance Evaluation • Conclusion
- 40. DataWorks Summit@Berlin 2018 40Network Based Computing Laboratory • Present overview of gRPC and TensorFlow • Present overview of RDMA and high-performance networks • Discussed challenges in accelerating and benchmarking TensorFlow and gRPC • RDMA can benefit DL workloads as showed by our AR-gRPC and the corresponding enhanced TensorFlow • Many other open issues need to be solved • Will enable Deep Learning community to take advantage of modern HPC technologies to carry out their analytics in a fast and scalable manner Concluding Remarks
- 41. DataWorks Summit@Berlin 2018 41Network Based Computing Laboratory Funding Acknowledgments Funding Support by Equipment Support by
- 42. DataWorks Summit@Berlin 2018 42Network Based Computing Laboratory Personnel Acknowledgments Current Students (Graduate) – A. Awan (Ph.D.) – R. Biswas (M.S.) – M. Bayatpour (Ph.D.) – S. Chakraborthy (Ph.D.) – C.-H. Chu (Ph.D.) – S. Guganani (Ph.D.) Past Students – A. Augustine (M.S.) – P. Balaji (Ph.D.) – S. Bhagvat (M.S.) – A. Bhat (M.S.) – D. Buntinas (Ph.D.) – L. Chai (Ph.D.) – B. Chandrasekharan (M.S.) – N. Dandapanthula (M.S.) – V. Dhanraj (M.S.) – T. Gangadharappa (M.S.) – K. Gopalakrishnan (M.S.) – R. Rajachandrasekar (Ph.D.) – G. Santhanaraman (Ph.D.) – A. Singh (Ph.D.) – J. Sridhar (M.S.) – S. Sur (Ph.D.) – H. Subramoni (Ph.D.) – K. Vaidyanathan (Ph.D.) – A. Vishnu (Ph.D.) – J. Wu (Ph.D.) – W. Yu (Ph.D.) Past Research Scientist – K. Hamidouche – S. Sur Past Post-Docs – D. Banerjee – X. Besseron – H.-W. Jin – W. Huang (Ph.D.) – W. Jiang (M.S.) – J. Jose (Ph.D.) – S. Kini (M.S.) – M. Koop (Ph.D.) – K. Kulkarni (M.S.) – R. Kumar (M.S.) – S. Krishnamoorthy (M.S.) – K. Kandalla (Ph.D.) – M. Li (Ph.D.) – P. Lai (M.S.) – J. Liu (Ph.D.) – M. Luo (Ph.D.) – A. Mamidala (Ph.D.) – G. Marsh (M.S.) – V. Meshram (M.S.) – A. Moody (M.S.) – S. Naravula (Ph.D.) – R. Noronha (Ph.D.) – X. Ouyang (Ph.D.) – S. Pai (M.S.) – S. Potluri (Ph.D.) – J. Hashmi (Ph.D.) – H. Javed (Ph.D.) – P. Kousha (Ph.D.) – D. Shankar (Ph.D.) – H. Shi (Ph.D.) – J. Zhang (Ph.D.) – J. Lin – M. Luo – E. Mancini Current Research Scientists – X. Lu – H. Subramoni Past Programmers – D. Bureddy – J. Perkins Current Research Specialist – J. Smith – M. Arnold – S. Marcarelli – J. Vienne – H. Wang Current Post-doc – A. Ruhela – K. Manian Current Students (Undergraduate) – N. Sarkauskas (B.S.)
- 43. DataWorks Summit@Berlin 2018 43Network Based Computing Laboratory The 4th International Workshop on High-Performance Big Data Computing (HPBDC) HPBDC 2018 will be held with IEEE International Parallel and Distributed Processing Symposium (IPDPS 2018), Vancouver, British Columbia CANADA, May, 2018 Workshop Date: May 21st, 2018 Keynote Talk: Prof. Geoffrey Fox, Twister2: A High-Performance Big Data Programming Environment Six Regular Research Papers and Two Short Research Papers Panel Topic: Which Framework is the Best for High-Performance Deep Learning: Big Data Framework or HPC Framework? http://web.cse.ohio-state.edu/~luxi/hpbdc2018 HPBDC 2017 was held in conjunction with IPDPS’17 http://web.cse.ohio-state.edu/~luxi/hpbdc2017 HPBDC 2016 was held in conjunction with IPDPS’16 http://web.cse.ohio-state.edu/~luxi/hpbdc2016
- 44. DataWorks Summit@Berlin 2018 44Network Based Computing Laboratory {panda, luxi}@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda http://www.cse.ohio-state.edu/~luxi Thank You! Network-Based Computing Laboratory http://nowlab.cse.ohio-state.edu/ The High-Performance Big Data Project http://hibd.cse.ohio-state.edu/