Achieve big data analytic platform with lambda architecture on cloud
Download as PPTX, PDF7 likes1,063 views

This document discusses achieving a big data analytic platform using the Lambda architecture on cloud infrastructure. It begins by explaining why moving to the cloud provides benefits like elastic scaling, reduced operational overhead, and increased focus on innovation. Common cloud services at Trend Micro like an analytic engine and cloud storage are then described. The document introduces the Lambda architecture and proposes a serving layer as a service. Key lessons learned from building big data solutions on AWS include the pros of unlimited scalability and easy disaster recovery compared to on-premises infrastructure.














![1.User invokes submitJob
2.Auth service check user’s credential
3.AE knows user name and group
4.AE matches the job and
deliver it to target cluster
5.AE pull data from CS
6.Job run on target cluster
7.AE output result to CS
8. AE sends msg to SNS
Topic if user specified
Usecase#3 – User submits job to target cluster to
run (1/4)
16
AE SaaSusers
submitJob
EMR
Cloud Storage
1.
2.
4.
3.
clusterCriteria:
[[‘sched:adhoc’,
‘env:prod’],
[“env:prod”]]
group:SPN,
tag:
‘sched:routine’,
‘env:prod’
validUser
is SPN
group
group:SPN,
tag:
‘sched:adhoc’,
‘env:prod’
5.
7.
6.
8.
Auth Service](https://image.slidesharecdn.com/scottmiao-achievebigdataanalyticplatformwithlambdaarchitectureoncloud-v01-160912055220/85/Achieve-big-data-analytic-platform-with-lambda-architecture-on-cloud-16-320.jpg)
![Usecase#3 – User submits job to target cluster to
run (2/4)
• Sample payload of submitJob API
2
{
"clusterCriterias": [
{
"tags": [
"sechd:adhoc",
"env:prod"
]
},
{
"tags": [
"env:prod"
]
}
],
"commandArgs": "$inputPaths $outputPaths",
// see below](https://image.slidesharecdn.com/scottmiao-achievebigdataanalyticplatformwithlambdaarchitectureoncloud-v01-160912055220/85/Achieve-big-data-analytic-platform-with-lambda-architecture-on-cloud-17-320.jpg)
![Usecase#3 – User submits job to target cluster to
run (3/4)
2
// see previous
"fileDependencies": "s3://path/to/my/main.sh,s3://path/to/my/test.pig",
"inputPaths": [
"cs://path/to/my/input/data“
// or you can use metadata search for input data
// “csq://first_entry_date:['2016-05-30T09:00:000Z','2016-05-30T09:01:000Z'}”
],
"name": "SubmitJob_pig_cs_to_cs_csq",
"outputPaths": [
"cs://path/to/my/output/result"
],
"tags": [
"env:my-test"
],
"notifyTo" : "arn:aws:sns:us-east-1:123456789123:my-sns"
}](https://image.slidesharecdn.com/scottmiao-achievebigdataanalyticplatformwithlambdaarchitectureoncloud-v01-160912055220/85/Achieve-big-data-analytic-platform-with-lambda-architecture-on-cloud-18-320.jpg)






































Achieve big data analytic platform with lambda architecture on cloud
- 1. Achieve Big Data Analytic Platform with Lambda Architecture on Cloud SPN Infra. , Trend Micro Scott Miao & SPN infra. 9/10/2016 1
- 2. Who am I • Scott Miao • RD, SPN, Trend Micro • Hadoop ecosystem about 6 years • AWS for BigData about 3 years • Expertise in HDFS/MR/HBase/AWS EMR • @takeshimiao • @slideshare
- 3. Agenda • Why go on Cloud • Common Cloud Services in Trend • Lambda Architecture on Cloud • Servicing Layer as-a Service • What we learned
- 4. Why go on Cloud
- 5. Data volume increases 1.5 ~ 2x every year Growth becomes 2x
- 6. Return of Investment • On traditional infra., we put a lot of efforts on services operation • On the Cloud, we can leverage its elasticities to automate our services • More focus on innovation !! Time Money Revenue Cost
- 7. Why AWS ?
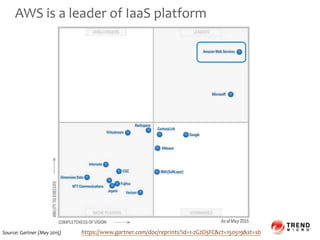
- 8. AWS is a leader of IaaS platform https://www.gartner.com/doc/reprints?id=1-2G2O5FC&ct=150519&st=sbSource: Gartner (May 2015)
- 9. AWS Evaluation Cost acceptable Functionalities satisfied Performance satisfied
- 10. Common Cloud Services in Trend ANALYTIC ENGINE + CLOUD STORAGE
- 11. Common Services on the Cloud Cloud CI/CD Common Auth Analytic Engine Cloud Storage
- 12. AE + CS Analytic Engine •Computation service for Trenders •Based on AWS EMR •Simple RESTful API calls •Computing on demand •Short live •Long running •No operation effort •Pay by computing resources Cloud Storage •Storage service for Trenders •Based on AWS S3 •Simple RESTful API calls •Share data to all in one place •Metadata search for files •No operation effort •Pay by storage size used
- 13. Analytic Engine is a… A common Big Data computation service on Cloud (AWS) 2
- 14. Major Features in nutshell 14 AE CS submitJob EMR createCluster Input from • cs path • cs metadata search • Pig UDFs support Output to CS with meta data UIs Cost visibility (AWS Cost explor.) Client logs (SumoLogic) Cluster info. (Proxy Gateway) Visibility • Fully HA • Fully automated • Auto recovery
- 15. Support usecases 1. User creates a cluster 2. User can create multiple clusters as he/she need 3. User submits job to target cluster to run 4. AE delivers job to secondary cluster if target cluster down 5. Diff. group of users are not allowed to submit cluster(s) 6. Diff. group of users are not allowed to delete cluster 7. Only same group of users are allowed to delete cluster 8. User wants to know what their current cost is 9. User wants to troubleshoot his/her submitted job 10. User wants to observe his/her cluster status 2
- 16. 1.User invokes submitJob 2.Auth service check user’s credential 3.AE knows user name and group 4.AE matches the job and deliver it to target cluster 5.AE pull data from CS 6.Job run on target cluster 7.AE output result to CS 8. AE sends msg to SNS Topic if user specified Usecase#3 – User submits job to target cluster to run (1/4) 16 AE SaaSusers submitJob EMR Cloud Storage 1. 2. 4. 3. clusterCriteria: [[‘sched:adhoc’, ‘env:prod’], [“env:prod”]] group:SPN, tag: ‘sched:routine’, ‘env:prod’ validUser is SPN group group:SPN, tag: ‘sched:adhoc’, ‘env:prod’ 5. 7. 6. 8. Auth Service
- 17. Usecase#3 – User submits job to target cluster to run (2/4) • Sample payload of submitJob API 2 { "clusterCriterias": [ { "tags": [ "sechd:adhoc", "env:prod" ] }, { "tags": [ "env:prod" ] } ], "commandArgs": "$inputPaths $outputPaths", // see below
- 18. Usecase#3 – User submits job to target cluster to run (3/4) 2 // see previous "fileDependencies": "s3://path/to/my/main.sh,s3://path/to/my/test.pig", "inputPaths": [ "cs://path/to/my/input/data“ // or you can use metadata search for input data // “csq://first_entry_date:['2016-05-30T09:00:000Z','2016-05-30T09:01:000Z'}” ], "name": "SubmitJob_pig_cs_to_cs_csq", "outputPaths": [ "cs://path/to/my/output/result" ], "tags": [ "env:my-test" ], "notifyTo" : "arn:aws:sns:us-east-1:123456789123:my-sns" }
- 19. Usecase#3 – User submits job to target cluster to run (4/4) • All existing job types used in on-premise are supported • Pure MR • Pig and UDFs • Hadoop streaming – Python, Ruby, etc 2
- 20. Usecase#8 – User wants to know what their current cost is (1/2) 20 • Billing & Cost management -> Cost Explorer -> Launch Cost Explorer • Filtered by • tags: “sys = ae“ and “comp = emr” and “other = <your-cluster-name>” • Group by Service
- 21. Usecase#8 – User wants to know what their current cost is (2/2) - Billing and Cost Analysis • Attach tags to your AWS resources 21 Tag Key Tag Value (sample) Description name aesaas-s-11-api *optional* for AWS cost explorer stack aesaas-s-11 *optional* for AWS cost explorer service aesaas *optional* for AWS cost explorer owner spn *required* the bill is under whose budget env prod|stg|dev *required* environment type sys ae *required* the system name comp api-server|emr *required* the subcomponent name other spn-stg *optional* an optional tag that free for other usage.
- 22. Why we use AE instead of EMR directly ? • Abstraction • Avoid locked-in • Hide details impl. behind the scene • AWS EMR was not design for long running jobs • >= AMI-3.1.1 – 256 ACTIVE or PENDING jobs (STEPs) • < AMI-3.1.1 – 256 jobs in total • Better integrated with other common services • Keep our hands off from AWS native codes • Centralized Authentication & Authorization • Leverage our internal LDAP server • No AWS tokens for user http://docs.aws.amazon.com/ElasticMapReduce/latest/DeveloperGuide/AddingStepstoaJobFlow.html
- 23. Lambda Architecture on Cloud
- 24. Next Phase Cloud Infra. AE-v1.0 AE + CS (v1.1~) Lambda arch. 24
- 25. What is Lambda (λ) Architecture 2
- 26. Data Ingestion Batch Layer Master Dataset Speed Layer Streaming Processing Batch Processing Batch View Merged View Real-Time View Serving Layer Data Access API Batch Layer as-a Service Serving Layer as-a Service A data-processing architecture designed to handle massive quantities of data by taking advantage of both batch- and stream- processing methods https://en.wikipedia.org/wiki/Lambda_architecture
- 27. Servicing Layer as-a Service METADATA STORE
- 28. Goals Help everyone to easily access metadata shared by several teams • Access data in one place • Avoid storage duplication • Share immediately to all • Provide unified intelligence Common metadata storage for several services • Abstract to hide infra & ops • Customize for different needs 28 (on aws)
- 29. Usecase • Store all threat entities into one place from new born – Every team can leverage contributions from other teams at very early stage 2
- 30. Features 30 Metadata Store Service Random Writes Bulk Writes Sync Query Async Query Automatic Provision Customizable Schema Unified Intelligence Threat Monitor
- 31. Borrow idea from Star Schema • A schema design widely used in data warehousing 31 Historical data – measurements or metrics for a specific event Descriptive attributes – characteristics to describe and select the fact data
- 32. Basic Idea • Refer to Star Schema design – Fact table • Put all records into this table (Single Source of Truth) • Affordable for random and bulk load of writes • Fast random reads by rowkey – Dimension table • Fast and flexible info. discovery • Get rowkey of records stored in Fact table • Then retrieve records by rowkey
- 33. Reference Implementation – Part 1 • This Star Schema concept can be fulfill by different impl. • A famous one is HBase + Indexer + Solr http://www.hadoopsphere.com/2013/11/the-evolving-hbase-ecosystem.html https://community.hortonworks.com/articles/1181/hbase-indexing-to-solr-with-hdp-search-in-hdp-23.html
- 34. Reference Implementation – Part 2 2 http://www.slideshare.net/AmazonWebServices/bdt310-big-data-architectural-patterns-and- best-practices-on-aws #p57
- 35. Dimension Tables Schema Dimension Tables Engine: Elastic Search Dimension Tables Engine: MySQL (RDS) Dimension Tables Engine: Dynamo DB Propagate data to dimension storage 35 Fact Tables (Dynamo DB) Propagato r Dynamo DB Streams Propagation Rules Random Writes Bulk Writes (Eventually Consistent)
- 39. What we learned FROM BIG DATA ON CLOUD
- 40. Pros & Cons Aspects IDC AWS Data Capacity Limited by physical rack space No limitation in seasonable amount Computation Capacity Limited by physical rack space No limitation in seasonable amount DevOps Hard, due to on physical machine/ VM farm Easy, due to code is everything (CI/CD) Scalability Hard, due to on physical machine/ VM farm Easy, relied on ELB, Autoscaling group from AWS
- 41. Pros & Cons Aspects IDC AWS Disaster Recovery Hard, due to on physical machine/ VM farm Easy, due to code is everything Data Location Limited due to IDC location Various and easy due to multiple regions of AWS Cost Implied in Total Cost of Ownership Acceptable cost with Cost Conscious Design Something more details…
- 43. We Are Hiring !
- 44. Backup
- 45. AE SaaS Architecture Design
- 46. IDC High Level Architecture Design 46 AZb AE API servers RDS Private ELB AZa AZb AZc AE API servers RDS services services services peering HTTPS EMR EMR Cross-account S3 buckets Time based Auto Scaling group worker s worker sMulti-AZs Auto Scaling group Time based Auto Scaling group Eureka Eureka VPN HTTPS/HTTP Basic Cloud StorageInternet HTTPS/HTTP Basic Amazon SNS Oregon (us-west-2) SJC1 SPN VPC CI slave Splunk forwarde r peering VPN Splunk peering
- 47. What is Netflix Genie • A practice from Netflix • A hadoop client to submit jobs to EMR • Flexible data model design to adopt diff kind of cluster • Flexible Job/cluster matching design (based on tags) • Cloud characteristics built-in design – e.g. auto-scaling, load-balance, etc • It’s goal is plain & simple • We use it as an internal component 47https://github.com/Netflix/genie/wiki
- 48. What is Netflix Eureka • Is a RESTful service • Built by Netflix • A critical component for Genie to do Load Balance and failover 48 Genie API API API
- 49. 9/12/2016 Confidential | Copyright 2016 TrendMicro Inc. 49 AWS EMR (Elastic MapReduce)
- 52. 2
- 53. 9/12/2016 Confidential | Copyright 2016 TrendMicro Inc. 53 Lessons Learned on AWS details
- 54. Different types of Auto-scaling group 54 Service Auto Scaling Group Type Features Provision Deploy/Conf ig Method OpsWorks 24/7 •manual creation/deletion •configure one instance for one AZ • CloudFormation • AWS::OpsWorks::In stance. AutoScalingType chef recipe time-based •can specify time slot(s) based on hour unit, on everyday or any day in week •configure one instance for one AZ load-based •can specify CPU/MEM/workload avg. based on an OPS layer •UP: when to increase instances •Down: when to decrease instances •No max./min. # of instances setting •configure one instance for one AZ EC2 •can set max./min. for # of instance •Multi-AZs support • CloudFormation • AWS::AutoScaling:: AutoScalingGroup • AWS::AutoScaling:: LaunchConfigurati on user-data
- 55. ELB + Auto-Scaling Group • ELB – Health Check • Determining the route for coming requests • Auto-Scaling Groups – Monitoring EC2 instance by CloudWatch – If EC2 abnormal, then terminate and start a new one • ELB + Auto-Scaling Group – Auto attach/detach EC2 instance(s) to ELB if Auto-Scaling Group launch/terminate EC2 http://docs.aws.amazon.com/autoscaling/latest/userguide/autoscaling-load-balancer.html
- 56. Auto Recovery based on Monit • OpsWorks already use Monit for Auto Recovery – Leverage the Monit on EC2 – Have practices in on-premise 2 AZ1 AZ2 API server API server https://mmonit.com/monit/ Auto Scaling group • Instance check by CloudWatch • Process check by Monit • No process – restart process • Process health check failed – terminate EC2 • Terminate EC2 !Auto Scaling group launch new EC2
Editor's Notes
- #5: What’s our goal
- #11: What’s our goal
- #32: https://en.wikipedia.org/wiki/Star_schema
- #35: Do not use CloudSearch Aurora is good !!
- #36: MongoDB is excluded based on Chien’s suggestion.
- #38: TAO: The Associations and Objects, a distributed Graph data store Unicorn: Graph-aware search system Graph API: interface to users