Analyzing Petabyte Scale Financial Data with Apache Pinot and Apache Kafka | Xiaoman Dong and Joey Pereira, Stripe
1 like2,362 views

This document discusses the utilization of Apache Pinot and Apache Kafka to manage petabyte-scale financial data at Stripe, addressing challenges related to data scale, freshness, and query latency. It emphasizes the introduction of a unified system that enables real-time financial activity tracking through advanced query optimization techniques and technologies. The conclusion outlines future plans to further enhance efficiency and reduce costs in data handling while continuing to support crucial financial precision requirements.









































































Analyzing Petabyte Scale Financial Data with Apache Pinot and Apache Kafka | Xiaoman Dong and Joey Pereira, Stripe
- 1. Analyzing Petabyte Scale Financial Data with Apache Pinot and Apache Kafka Xiaoman Dong @Stripe Joey Pereira @Stripe
- 2. Agenda ● Tracking funds at Stripe ● Quick intro on Pinot ● Challenges: scale and latency ● Optimizations for a large table
- 3. Tracking funds at Stripe
- 4. Stripe is complicated Tracking funds at Stripe
- 5. Stripe is complicated Tracking funds at Stripe
- 6. Ledger, the financial source of truth ● Unified data format for financial activity ● Exhaustively covers all activity ● Centralized observability Tracking funds at Stripe
- 7. Ledger, the financial source of truth ● Unified data format for financial activity ● Exhaustively covers all activity ● Centralized observability Tracking funds at Stripe
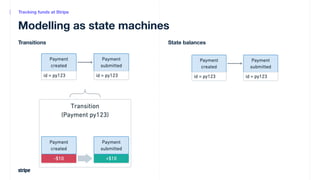
- 8. Modelling as state machines Successful payment Tracking funds at Stripe
- 9. Modelling as state machines Successful payment Tracking funds at Stripe
- 10. Modelling as state machines Successful payment Tracking funds at Stripe
- 11. Modelling as state machines Successful payment Tracking funds at Stripe
- 12. Modelling as state machines Successful payment Tracking funds at Stripe
- 13. ● What action caused the transition. ● Why it transitioned. ● When it transitioned. ● Looking at transitions across multiple systems and teams. Observability Transaction-level investigation Tracking funds at Stripe
- 14. Modelling as state machines Incomplete states are balances Tracking funds at Stripe
- 15. Modelling as state machines Incomplete states are balances Tracking funds at Stripe
- 16. Observability Aggregating state balances Tracking funds at Stripe
- 17. Observability Tracking funds at Stripe Detection Date of state’s first transition Amount ($$)
- 18. ● Look up one state transition ○ by ID or other properties ● Look up one state, inspect it ○ listing transitions with sorting, paging, and summaries ● Aggregate many states Query patterns Tracking funds at Stripe
- 19. ● Look up one state transition ○ by ID or other properties ● Look up one state, inspect it ○ listing transitions with sorting, paging, and summaries ● Aggregate many states This is easy... until we have: ● Hundreds of billions of rows ● States with hundreds of millions of transitions ● Need for fresh, real-time data ● Queries with sub-second latency, serving interactive UI Query patterns Tracking funds at Stripe
- 20. World before Pinot Tracking funds at Stripe Two complicated systems
- 21. World before Pinot Tracking funds at Stripe Two complicated systems
- 22. World with Pinot Tracking funds at Stripe ● One system for serving all cases ● Simple and elegant ● No more multiple copies of data
- 23. Quick intro on Pinot
- 24. Pinot Distributed Architecture * (courtesy of blog https://www.confluent.io/blog/real-time-analytics-with-kafka-and-pinot/ )
- 25. Pinot Distributed Architecture * (courtesy of blog https://www.confluent.io/blog/real-time-analytics-with-kafka-and-pinot/ )
- 26. Pinot Distributed Architecture * (courtesy of blog https://www.confluent.io/blog/real-time-analytics-with-kafka-and-pinot/ )
- 27. Pinot Distributed Architecture * (courtesy of blog https://www.confluent.io/blog/real-time-analytics-with-kafka-and-pinot/ )
- 28. (Transition joey => xd) ●
- 29. Our challenges Query Latency Data Freshness Data Scale
- 30. Challenge #1: Data Scale: the Largest Single Table in Pinot
- 31. One cluster to serve all major queries Huge tables ● Each with more than hundreds of billions rows ● 700TB storage on disk, after 2x replication Pinot numbers ● Offline segments: ~60k segments per table ● Real time table: 64 partitions Hosted by AWS EC2 Instances ● ~1000 small hosts (4000 vCPU) with attached SSD ● Instance config selected based on performance and cost
- 32. One cluster to serve all major queries Huge tables ● Each with more than hundreds of billions rows ● 700TB storage on disk, after 2x replication Pinot numbers ● Offline segments: ~60k segments per table ● Real time table: 64 partitions Hosted by AWS EC2 Instances ● ~1000 small hosts (4000 vCPU) with attached SSD ● Instance config selected based on performance and cost Largest Pinot table in the world !
- 33. Challenge #2: Data freshness: Kafka Ingestion
- 34. What Pinot + Kafka Brings Pinot broker provides merged view of offline and real time data ● Real-time Kafka ingestion comes with second level data freshness ● Merged view allows us query whole data set like one single table
- 35. Financial Data in Real Time (1/2) Avoid duplication is critical for financial systems ● A Flink deduplication job as upstream ● Exactly-once Kafka sink used in Flink Exactly-once from Flink to Pinot ● Kafka transactional consumer enabled in Pinot ● Atomic update of Kafka offset and Pinot segment ● Result: 1:1 mapping from Flink output to Pinot ● No extra effort needed for us
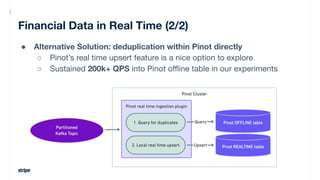
- 36. Financial Data in Real Time (2/2) ● Alternative Solution: deduplication within Pinot directly ○ Pinot’s real time upsert feature is a nice option to explore ○ Sustained 200k+ QPS into Pinot offline table in our experiments
- 37. Challenge #3: Drive Down the Query Latency
- 38. Optimizations Applied (1/4) ● Partitioning - Hashing data across Pinot servers ○ The most powerful optimization tool in Pinot ○ Map partitions to servers: Pinot becomes a key-value store
- 39. Optimizations Applied (1/4) ● Partitioning - Hashing data across Pinot servers ○ The most powerful optimization tool in Pinot ○ Map partitions to servers: Pinot becomes a key-value store Depending on query type, partitioning can improve query latency by 2x ~ 10x
- 40. Optimizations Applied (2/4) ● Sorting - Organize data between segments ○ Sorting is powerful when done in Spark ETL job; we can arrange how the rows are divided into segments ○ Column min/max values can help avoid scanning segments ○ Grouping the same value into the the same segment can reduce storage cost and speed up pre-aggregations
- 41. Optimizations Applied (2/4) ● Sorting - Organize data between segments ○ Sorting is powerful when done in Spark ETL job; we can arrange how the rows are divided into segments ○ Column min/max values can help avoid scanning segments ○ Grouping the same value into the the same segment can reduce storage cost and speed up pre-aggregations In our production data set, sorting roughly improves aggregation query latency by 2x
- 42. Optimization Applied (3/4) ● Bloom filter - Quickly prune out a Pinot segment ○ Best friend of key-value style lookup query ○ Works best when there are very few hit in filter ○ Configurable in Pinot: control false positive rate or total size
- 43. Optimization Applied (4/4) ● Pre-aggregation by star tree index ○ Pinot supports a specialized pre-aggregation called “star-tree index” ○ Pre-aggregates several columns to avoid computation during query ○ Star tree index balances between disk space and query time for aggregations with multiple dimensions
- 44. Optimization Applied (4/4) ● Pre-aggregation by star tree index ○ Pinot supports a specialized pre-aggregation called “star-tree index” ○ Pre-aggregates several columns to avoid computation during query ○ Star tree index balances between disk space and query time for aggregations with multiple dimensions Query latency improvement (accounts with billion-level transactions): ~30 seconds vs. 300 milliseconds
- 45. The Combined Power of Four Optimizations ● They can reduce query latency to sub second for any large table ○ Works well for our hundreds of billions of rows ○ Most of the time, tables are small and we only need some of them ● We chose the optimizations to speed up all 5 production queries ○ Some queries need only bloom filter ○ Partitioning and sorting are applied for critical queries
- 46. Real time ingestion needs extra care
- 47. Optimizing real time ingestion (1/2) With 3-day real time data in Pinot, we saw 2~3 sec added latencies ● Pinot real time segments are often very small ● Real time server numbers are limited by Kafka partition count (max 64 servers in our case) ● Each real time server ends up with many small segments ● Real time server has high I/O and high CPU during query
- 48. Optimizing real time ingestion (2/2) Latency back to sub-seconds after adopting Tiered Storage ● Tiered storage enables different storage hosts for segments based on time ● Moves real time segments into dedicated servers ASAP ● Utilizes more servers to process query for real time segments ● Avoids query slow down in Kafka consumers with back pressure
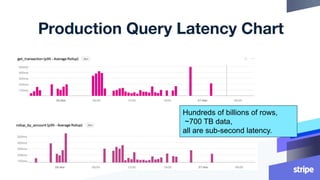
- 49. Production Query Latency Chart Hundreds of billions of rows, ~700 TB data, all are sub-second latency.
- 50. Financial Precision ● Precise numbers are critical for financial data processing ● Java BigDecimal is the answer for Pinot ● Pinot supports BigDecimal by BINARY columns (currently) ○ Computation (e.g., sum) done by UDF-style scalar functions ○ Star Tree index can be applied to BigDecimal columns ○ Works for all our use cases ○ No significant performance penalty observed
- 51. With Pinot and Kafka working together, we have created the largest Pinot table in the world, to represent financial funds flow graphs. ● With hundreds of billions of edges ● Seconds of data freshness ● Financial precise number support ● Exactly-once Kafka semantics ● Sub-second query latency Conclusion
- 52. Future Plans ● Reduce hardware cost by applying tiered storage in offline table ○ Use HDD-based hosts for data months old ● Multi-region Pinot cluster ● Try out many of Pinot’s exciting new features
- 53. Thanks and Questions (We are hiring!)
- 54. (Backup Slides)
- 55. ● Ledger models financial activity as state machines ● Transitions are immutable append-only logs in Kafka ● Everything is transaction-level ● Incomplete states are represented by balances. ● Two core use-cases: transaction-level queries, and aggregation analytics ● Current system is unscalable and complex Summarizing Tracking funds at Stripe
- 56. Pinot and Kafka works in synergy
- 57. Detect problems in hundreds of billions rows (cont’d) How to detect issues in a graph of half trillion nodes? 1) Sum all money in/out nodes, focus only on non-zero nodes Now we have 20 million nodes with non-zero sum, how to analyze it? 2) Group by a) Day of first transaction seen -- Time Series b) Sign of sum (negative/positive flow) c) Some node properties like type We have a time series, and fields we can slice/dice. OLAP Cube
- 58. Modelling as state machines Tracking funds at Stripe Transitions State balances
- 59. Modelling as state machines Tracking funds at Stripe Transitions State balances
- 60. Modelling as state machines Tracking funds at Stripe Transitions State balances
- 61. Modelling as state machines Balances of incomplete payment Tracking funds at Stripe
- 62. Modelling as state machines Balances of successful payment Tracking funds at Stripe
- 63. Observability Aggregating state balances Tracking funds at Stripe
- 64. ● Data volume, handling hundreds of billions of records ● Data freshness, getting real-time processing ● Query latency, making analytics usable for interactive internal UIs ● Achieving all three at once: difficult! Why this is challenging? Tracking funds at Stripe
- 65. Modelling as state machines Dozens and dozens of states Tracking funds at Stripe
- 66. Observability Aggregating state balances Tracking funds at Stripe
- 67. Observability Aggregating state balances Tracking funds at Stripe
- 68. Double-Entry Bookkeeping ● Internal funds flow represented by a directed graph ● Record the graph edge as Double-Entry Bookkeeping ● Nodes in the graph are modeled as accounts ● Accounts should eventually have zero balances
- 69. Detect problems in hundreds of billions of rows Money in/out graph nodes should sum to zero (“cleared”). Stuck funds over time = Revenue Loss ● One card swipe could create 10+ nodes ● Hundreds of billions unique nodes and increasing
- 71. Lessons Learned ● Metadata becomes heavy for huge tables ○ O(n2 ) algorithm is not good when processing 60k segments ○ Avoid sending 1k+ segment names across 100+ servers ○ Metadata is important when aiming for sub-second latency ● Tailing effect of p99/p95 latencies when we have 1000 servers ○ Occasional hiccups in server becomes high probability events and drags down p99/p95 query latency ○ Limit servers queried to be as small as possible (partitioning, server grouping, etc)
- 72. Clearing Time Series (Exploring)
- 73. Pinot Segment File Storage
- 74. Financial Data in Real Time (1/2) ● We have an upstream Flink deduplication job in place ● No duplication allowed ○ Pinot’s real time primary key is a nice option to explore ○ Sustained 200k+ QPS into Pinot offline tables in our deduplication experiments (after optimization) ○ An upstream Flink deduplication job may be the best choice ● Exactly-once consumption from Kafka to Pinot ○ Kafka transactional consumer enabled in Pinot ○ 1:1 mapping of Kafka message to table rows ○ Critical for financial data processing
- 75. Table Design Optimization Iterations ● It takes 2~3 days for Spark ETL job to process full data set ● Scale up only after optimized design ○ Shadow production query ○ Rebuild whole data set when needed ● General rule of thumb: the fewer segments scanned, the better
- 76. Kafka Ingestion Optimization (2/2) ● Partition/Sharding in Real time tables (Experimented) ○ Needs a streaming job to shuffler Kafka topic by key ○ Helps query performance for real time table ○ Worth adopting ● Merging small segments into large segments ○ Needs cron style job to do the work ○ Helps pruning and scanning ○ Not a bottleneck for us