Andriy Zrobok "MS SQL 2019 - new for Big Data Processing"
Download as PPTX, PDF0 likes107 views

This document discusses MS SQL Server 2019's capabilities for big data processing through PolyBase and Big Data Clusters. PolyBase allows SQL queries to join data stored externally in sources like HDFS, Oracle and MongoDB. Big Data Clusters deploy SQL Server on Linux in Kubernetes containers with separate control, compute and storage planes to provide scalable analytics on large datasets. Examples of using these technologies include data virtualization across sources, building data lakes in HDFS, distributed data marts for analysis, and integrated AI/ML tasks on HDFS and SQL data.













![PolyBase: statistics
CREATE STATISTICS
CustomerCustKeyStatistics
ON pb_sqlserver.address
(stateprovinceid) WITH FULLSCAN;
SELECT DISTINCT a.city
from [pb_sqlserver].[address] a
where a.stateprovinceid = 9](https://image.slidesharecdn.com/mssql2019bigdataprocessing-190408133358/85/Andriy-Zrobok-MS-SQL-2019-new-for-Big-Data-Processing-14-320.jpg)






Andriy Zrobok "MS SQL 2019 - new for Big Data Processing"
- 1. MS SQL 2019: Big Data Processing Andrii Zrobok Chief Database Developer, EPAM [email protected]
- 2. Agenda MS SQL 2019 overview PolyBase: History, What, Why, Demo Big Data Cluster Scenarios
- 3. About me 25 + years of experience in database development: development data-centric applications from scratch, support of legacy databases/applications, data migration tasks, performance tuning, SSIS/ETL tasks, consulting, database trainer, etc. Databases: FoxPro 2.0 for DOS (Fox Software), MS SQL Server (from version 6.5, 1996), Oracle, Sybase ASE, MySQL, PostgreSQL Co-leader of Lviv Data Platform UG (PASS Local Chapter) (http://lvivsqlug.pass.org/) Speaker at: • PASS SQLSaturday conferences (Lviv, Kyiv, Dnipro, Odessa, Kharkiv; since 2013) • PASS L’viv/Vinnitsa/Virtual SQL Server User Groups; • EPAM IT Week 2015-2017
- 4. Nowadays challenges Unified access to all your data with unparalleled performance Easily and securely manage data big and small Build intelligent Apps and AI with all your data
- 5. MS SQL 2019 Preview Windows: Standard version with PolyBase Linux: Linux version without PolyBase Docker: Database Engine Container Image (Ubuntu, Red Hat) Big Data Analytics: Linux container on Kubernetes https://www.microsoft.com/en-us/sql-server/sql-server-2019#Install
- 6. PolyBase: What? SQL Server PolyBase external tables / external data source T-SQLApplications Analytics Microsoft's newest technology for connecting to remote servers. https://docs.microsoft.com/uk-ua/sql/relational-databases/polybase/polybase- guide?view=sqlallproducts-allversions
- 7. PolyBase: History Introduced in SQL Server Parallel Data Warehouse (PDW) edition, back in 2010 Expanded in SQL Server Analytics Platform System (APS) in 2012. Released to the "general public" in SQL Server 2016, with most support being in Enterprise Edition. Extended support for additional technologies (like Oracle, MongoDB, etc.) will be available in SQL Server 2019.
- 8. PolyBase: Why? Without PolyBase Transfer half your data so that all your data was in one format or the other Query both sources of data, then write custom query logic to join and integrate the data at the client level. With PolyBase using T-SQL to join the data (external table, statistics for external table) Usage Querying / Import (into table) / Export (into data storage) Performance Use computation on Target server (OPTION (FORCE EXTERNALPUSHDOWN))
- 9. PolyBase: Demo - tools 1) PolyBase should be installed and enabled 2) Using Management Studio (scripts, no visibility) OR 3) Using Azure Data Studio + SQL Server 2019 (Preview) Extension https://docs.microsoft.com/en-us/sql/azure-data-studio/download?view=sql- server-2017 https://docs.microsoft.com/en-us/sql/azure-data-studio/sql-server-2019- extension?view=sqlallproducts-allversions
- 10. PolyBase: Demo - steps Create master key (needed for password encryption) Create database scoped credential (access to remote database server) Create external data source (address of remote database server) Create schema for external data (optional) Create external tables / statistics on external tables
- 11. PolyBase: Demo – external tables CREATE DATABASE SCOPED CREDENTIAL OracleCredentials WITH IDENTITY = 'system', Secret = '0x7ORA18c'; CREATE EXTERNAL DATA SOURCE OracleInstance WITH ( LOCATION = 'oracle://192.168.1.103:1521', CREDENTIAL = OracleCredentials); CREATE EXTERNAL TABLE pb_oracle.countries ( country_id CHAR(2) NOT NULL , country_name VARCHAR(40) , region_id INTEGER ) WITH ( LOCATION='XE.EDU.COUNTRIES', DATA_SOURCE=OracleInstance);
- 12. PolyBase: select from remote servers SELECT e.employee_id, e.first_name, e.last_name ,d.department_name ,l.city ,c.country_name ,r.region_name FROM dbo.employees e INNER JOIN dbo.departments d ON e.department_id = d.department_id INNER JOIN dbo.locations l ON d.location_id = l.location_id INNER JOIN pb_oracle.countries c ON c.country_id = l.country_id INNER JOIN pb_sqlserver.regions r ON r.region_id = c.region_id
- 14. PolyBase: statistics CREATE STATISTICS CustomerCustKeyStatistics ON pb_sqlserver.address (stateprovinceid) WITH FULLSCAN; SELECT DISTINCT a.city from [pb_sqlserver].[address] a where a.stateprovinceid = 9
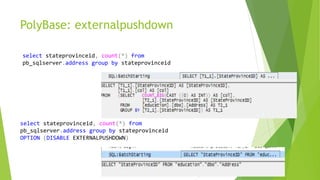
- 15. PolyBase: externalpushdown select stateprovinceid, count(*) from pb_sqlserver.address group by stateprovinceid select stateprovinceid, count(*) from pb_sqlserver.address group by stateprovinceid OPTION (DISABLE EXTERNALPUSHDOWN)
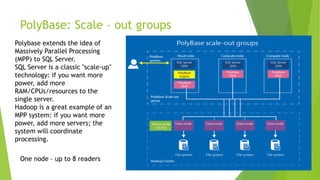
- 16. PolyBase: Scale – out groups One node – up to 8 readers Polybase extends the idea of Massively Parallel Processing (MPP) to SQL Server. SQL Server is a classic "scale-up" technology: if you want more power, add more RAM/CPUs/resources to the single server. Hadoop is a great example of an MPP system: if you want more power, add more servers; the system will coordinate processing.
- 18. Big data cluster architecture
- 19. Big data cluster component Component Description Control Plane The control plane provides management and security for the cluster. It contains the Kubernetes master, the SQL Server master instance, and other cluster-level services such as the Hive Metastore and Spark Driver. Compute plane The compute plane provides computational resources to the cluster. It contains nodes running SQL Server on Linux pods. The pods in the compute plane are divided into compute pools for specific processing tasks. A compute pool can act as a PolyBase scale-out group for distributed queries over different data sources-such as HDFS, Oracle, MongoDB, or Teradata. Data plane The data plane is used for data persistence and caching. The SQL data pool consists of one or more pods running SQL Server on Linux. It is used to ingest data from SQL queries or Spark jobs. SQL Server big data cluster data marts are persisted in the data pool. The storage pool consists of storage pool pods comprised of SQL Server on Linux, Spark, and HDFS. All the storage nodes in a SQL Server big data cluster are members of an HDFS cluster.
- 20. Management Easy deploy and manage because of benefits of containers and Kubernetes Fast to deploy Self contained (no installations required, images) Easy upgrade – new image uploading Scalable, multi-tenant
- 21. Scenarios: Data virtualization By leveraging SQL Server PolyBase SQL Server big data clusters can query external data sources without moving or copying the data
- 22. Scenarios: Data Lake A SQL Server big data cluster includes a scalable HDFS storage pool. This can be used to store big data, potentially ingested from multiple external sources. Once the big data is stored in HDFS in the big data cluster, you can analyze and query the data and combine it with your relational data.
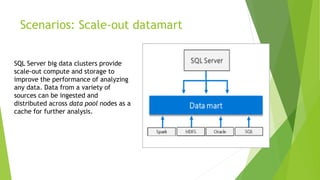
- 23. Scenarios: Scale-out datamart SQL Server big data clusters provide scale-out compute and storage to improve the performance of analyzing any data. Data from a variety of sources can be ingested and distributed across data pool nodes as a cache for further analysis.
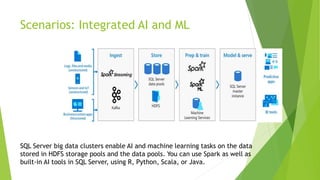
- 24. Scenarios: Integrated AI and ML SQL Server big data clusters enable AI and machine learning tasks on the data stored in HDFS storage pools and the data pools. You can use Spark as well as built-in AI tools in SQL Server, using R, Python, Scala, or Java.
- 25. MS SQL Server 2019 & Big Data Processing The end Q&A THANK YOU
Editor's Notes
- #6: Big Data Clusters The latest version simplifies big data analytics for SQL Server users. The new SQL server combines HDFS (the Hadoop Distributed File System) and Apache Spark and provides one integrated system. It provides the facility of data virtualization by integrating data without extracting , transforming and loading it. Big data clusters are difficult to deploy but if you have Kubernetes infrastructure, a single command will deploy your big data cluster in about half an hour.
- #7: Polybase is Microsoft's newest technology for connecting to remote servers. It started by letting you connect to Hadoop and has expanded since then to include Azure Blob Storage. Polybase is also the best method to load data into Azure SQL Data Warehouse. The PolyBase product which was in earlier version too has been expanded. Sql server can now support queries from external sources like Oracle, Teradata, MongoDB which as a result increases the flexibility of the sql server
- #17: Polybase lets SQL Server compute nodes talk directly to Hadoop data nodes, perform aggregations, and then return results to the head node. This removes the classic SQL Server single point of contention.
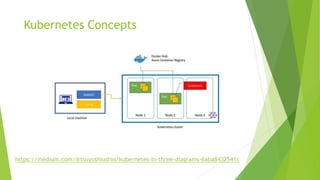
- #18: Kubernetes enable you to use the cluster as if it is single PC. You don’t need to care the detail of the infrastructure. Just declare the what you want in yaml file, you will get what you want Cluster A Kubernetes cluster is a set of machines, known as nodes. One node controls the cluster and is designated the master node; the remaining nodes are worker nodes. The Kubernetes master is responsible for distributing work between the workers, and for monitoring the health of the cluster. Node A node runs containerized applications. It can be either a physical machine or a virtual machine. A Kubernetes cluster can contain a mixture of physical machine and virtual machine nodes. Pod A pod is the atomic deployment unit of Kubernetes. A pod is a logical group of one or more containers-and associated resources-needed to run an application. Each pod runs on a node; a node can run one or more pods. The Kubernetes master automatically assigns pods to nodes in the cluster. In SQL Server big data clusters, Kubernetes is responsible for the state of the SQL Server big data clusters; Kubernetes builds and configures the cluster nodes, assigns pods to nodes, and monitors the health of the cluster.
- #19: Big Data Clusters The latest version simplifies big data analytics for SQL Server users. The new SQL server combines HDFS (the Hadoop Distributed Filing System) and Apache Spark and provides one integrated system. It provides the facility of data virtualization by integrating data without extracting , transforming and loading it. Big data clusters are difficult to deploy but if you have Kubernetes infrastructure, a single command will deploy your big data cluster in about half an hour. A SQL Server big data cluster is a cluster of Linux containers orchestrated by Kubernetes. Starting with SQL Server 2019 preview, SQL Server big data clusters allow you to deploy scalable clusters of SQL Server, Spark, and HDFS containers running on Kubernetes. These components are running side by side to enable you to read, write, and process big data from Transact-SQL or Spark, allowing you to easily combine and analyze your high-value relational data with high-volume big data. Control plane The control plane provides management and security for the cluster. It contains the Kubernetes master, the SQL Server master instance, and other cluster-level services such as the Hive Metastore and Spark Driver. Compute plane The compute plane provides computational resources to the cluster. It contains nodes running SQL Server on Linux pods. The pods in the compute plane are divided into compute pools for specific processing tasks. A compute pool can act as a PolyBase scale-out group for distributed queries over different data sources-such as HDFS, Oracle, MongoDB, or Teradata. Data plane The data plane is used for data persistence and caching. It contains the SQL data pool, and storage pool. The SQL data pool consists of one or more pods running SQL Server on Linux. It is used to ingest data from SQL queries or Spark jobs. SQL Server big data cluster data marts are persisted in the data pool. The storage pool consists of storage pool pods comprised of SQL Server on Linux, Spark, and HDFS. All the storage nodes in a SQL Server big data cluster are members of an HDFS cluster.
- #22: Data virtualization: By leveraging SQL Server PolyBase, SQL Server big data clusters can query external data sources without moving or copying the data.
- #23: Data lake A SQL Server big data cluster includes a scalable HDFS storage pool. This can be used to store big data, potentially ingested from multiple external sources. Once the big data is stored in HDFS in the big data cluster, you can analyze and query the data and combine it with your relational data.
- #24: Data virtualization: By leveraging SQL Server PolyBase, SQL Server big data clusters can query external data sources without moving or copying the data. SQL Server 2019 preview introduces new connectors to data sources. Data lake A SQL Server big data cluster includes a scalable HDFS storage pool. This can be used to store big data, potentially ingested from multiple external sources. Once the big data is stored in HDFS in the big data cluster, you can analyze and query the data and combine it with your relational data. Scale-out data mart SQL Server big data clusters provide scale-out compute and storage to improve the performance of analyzing any data. Data from a variety of sources can be ingested and distributed across data pool nodes as a cache for further analysis.
- #25: Integrated AI and Machine Learning SQL Server big data clusters enable AI and machine learning tasks on the data stored in HDFS storage pools and the data pools. You can use Spark as well as built-in AI tools in SQL Server, using R, Python, Scala, or Java.