





















Apache Cassandra and Python for Analyzing Streaming Big Data
- 1. Apache Cassandra and Python For streaming Big Data Prajod S Vettiyattil Architect, Wipro @prajods https://in.linkedin.com/in/prajod Nishant Sahay Architect, Wipro @nsahaytech https://in.linkedin.com/in/nishantsahay 1 Open Source India Nov 2015 Database track
- 2. Agenda 1. Time Series Data Analysis 2. Spark, Python, Cassandra and D3 3. Business problem 4. Solution using Logical Architecture 5. Data Processor 6. Data Persistence 7. Data Visualization 2
- 3. What this session is about 3 What Big Data Streaming Time Series How Spark Python Cassandra D3.js, Node.js
- 4. Tools: Python, Spark, Cassandra, Node and D3 • Python and Spark for Big data processing • Cassandra for persistence and serving • D3 for visualization • Node for • Enabling scalability • Data aggregation 4
- 5. python • Popular with Open source projects • Wide support base • Strong in data science • Visualization libraries • Statistics functions 5
- 6. Cassandra • noSQL database • Column family • Dynamic columns • AP in CAP theorem • Tunable consistency • Suited for time series storage 6
- 7. D3.js • Data driven documents • SVG, html, css and javascript • Fine grained control of screen elements • Plethora of UI widgets 7
- 8. Business Problem •Handle streaming data •Stock ticks •Weather movements •Satellite captures •Astronomical observations •Large Hadron Collider •Ingest •Persist •Visualize •Analysing stock prices 8
- 9. Logical Solution Architecture Time Series Data Producer (IoT devices, Stock ticks) Data Processor (pySpark) Data Persistence (Cassandra) Visualization Aggregator (Node.js) Visualization (D3.js) 9
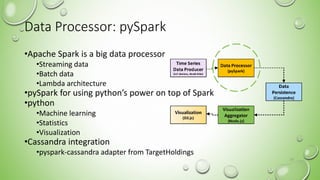
- 10. Data Processor: pySpark •Apache Spark is a big data processor •Streaming data •Batch data •Lambda architecture •pySpark for using python’s power on top of Spark •python •Machine learning •Statistics •Visualization •Cassandra integration •pyspark-cassandra adapter from TargetHoldings 10
- 11. Logical Architecture diagram of Spark Apache Spark Spark SQL MLlib GraphX SparkR pySpark 11 Spark Streaming
- 12. Apache Spark: Core • In memory processing for Big Data • Cached intermediate data sets • Multi-step DAG based execution • Resilient Distributed Data(RDD) sets 12
- 14. Apache Spark: Processing stock ticks • Ingest stock tick stream, coming in at a high rate • Calculate moving average of stock prices • Insert the average of prices into Cassandra 14
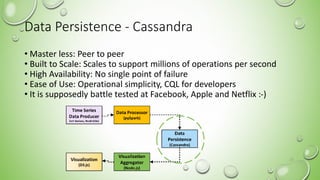
- 15. Data Persistence - Cassandra • Master less: Peer to peer • Built to Scale: Scales to support millions of operations per second • High Availability: No single point of failure • Ease of Use: Operational simplicity, CQL for developers • It is supposedly battle tested at Facebook, Apple and Netflix :-) 15
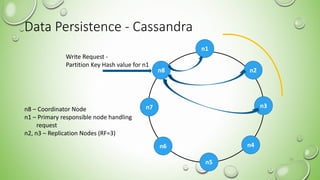
- 16. Data Persistence - Cassandra 16 n1 n5 n2 n4 n3n7 n8 n6 Write Request - Partition Key Hash value for n1 n8 – Coordinator Node n1 – Primary responsible node handling request n2, n3 – Replication Nodes (RF=3)
- 17. Cassandra Data Model – Skinny Rows Skinny Rows: Primary Key with only partition key CREATE TABLE stock_info(stock_id text, date text, price double, PRIMARY KEY ((stock_id, date)); stock_id date price GAZP 2015-11-11 556.50 GAZP 2015-11-10 556.65 GAZP:2015-11-11 price 556.50 GAZP:2015-11-10 price 556.65 17 Composite Partition Key Logical View Disc View Node n1 Node n4
- 18. Cassandra Data Model – Wide Rows Wide Rows Primary key contains column (Clustering Columns) other than the partition key. CREATE TABLE stock_ticker(stock_id text, price double, event_time timestamp , PRIMARY KEY (stock_id, event_time); GAZP 2015-11-10 13:30:00:price 556.45 2015-11-10 09:30:00:price 559.45 stock_ id price date event_time GAZP 559.45 2015-11-10 2015-11-10 09:30:00 GAZP 556.45 2015-11-10 2015-11-10 13:30:00 GAZP 556.65 2015-11-11 2015-11-11 18:00:00 2015-11-11 16:00:00:price 556.65 18 Logical View Disc View Compound Primary Key (Partition+Clustering) Node n1
- 19. Time Series – Cassandra Data Model Wide Row + Row Partition CREATE TABLE stock_info(stock_id text, date text, price double, event_time timestamp, PRIMARY KEY ((stock_id, date), event_time); stock_id price date event_time GAZP 559.45 2015-11-10 2015-11-10 09:30:00 GAZP 556.45 2015-11-10 2015-11-10 13:30:00 GAZP 556.65 2015-11-11 2015-11-11 18:00:00 GAZP:2015-11-10 2015-11-10 13:30:00:price 556.45 2015-11-10 09:30:00:price 559.45 GAZP:2015-11-11 2015-11-11 18:00:00:price 556.65 19 Logical View Disc View Node n1 Node n6
- 20. Summary – Cassandra Data Model Skinny Row Wide Row Wide Row + Row Partition Optimize with Expiring Columns/Split day bucket to multiple rows 20 GAZP:2015-11-10 2015-11-10 13:30:00:price 556.45 2015-11-10 09:30:00:price 559.45 GAZP:2015-11-11 2015-11-11 18:00:00:price 556.65 Node n1 Node n6 GAZP 2015-11-10 13:30:00:price 556.45 2015-11-10 09:30:00:price 559.45 2015-11-11 16:00:00:price 556.65 Node n1 GAZP:2015-11-11 price 556.50 GAZP:2015-11-10 price 556.65 Node n1 Node n4
- 21. Node.js, Cassandra and D3.js D3.js graph Browser Web UI Layer ExpressJS cassandra- driver Server Layer Database Layer Cassandra DB Rest Based Polling Get JSON Data CQL – Select Time Series Data 21
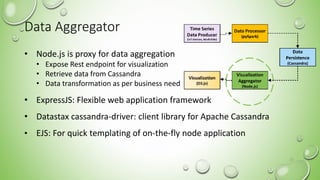
- 22. Data Aggregator • Node.js is proxy for data aggregation • Expose Rest endpoint for visualization • Retrieve data from Cassandra • Data transformation as per business need • ExpressJS: Flexible web application framework • Datastax cassandra-driver: client library for Apache Cassandra • EJS: For quick templating of on-the-fly node application 22
- 23. Visualization - Frameworks • D3 for transformation of time series data into visual information • Consume REST API • Generate customized data driven graphs and visualization • Rickshaw is a JavaScript toolkit for creating interactive time series graphs • Built on D3.js • Generate time-series graph 23
- 24. Visualization – Graphs 2424 Price Moving Average Trade Volume Stock Price
- 25. Summary • Processing time series data • Apache Spark • Cassandra • Node.js • D3.js 25
- 26. QUESTIONS Prajod S Vettiyattil Architect, Wipro @prajods https://in.linkedin.com/in/prajod Nishant Sahay Architect, Wipro @nsahaytech https://in.linkedin.com/in/nishantsahay